
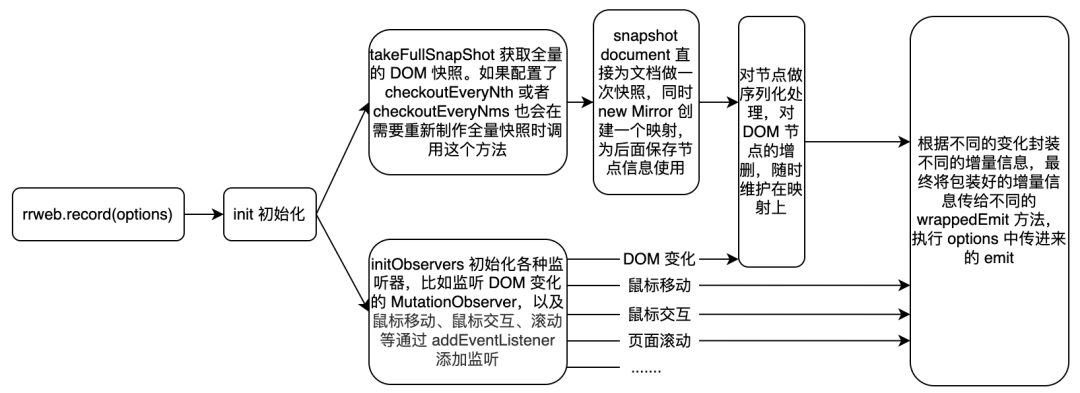
rrweb 实现原理介绍
一、背景rrweb 全称 'record and replay the web',是当下很流行的一个录制屏幕的开源库。与我们传统认知的录屏方式(如 WebRTC)不同的是,rrweb 录制的不是真正的视频流,而是一个记录页面 DOM 变化的 JSON 数组,因此不能录制整个显示器的屏幕,只能录制浏览器的一个页签。二、基本使用https://github.com/rrweb-io/rrweb/blo
一、背景
rrweb 全称 'record and replay the web',是当下很流行的一个录制屏幕的开源库。与我们传统认知的录屏方式(如 WebRTC)不同的是,rrweb 录制的不是真正的视频流,而是一个记录页面 DOM 变化的 JSON 数组,因此不能录制整个显示器的屏幕,只能录制浏览器的一个页签。
二、基本使用
https://github.com/rrweb-io/rrweb/blob/master/guide.zh_CN.md
import rrweb from 'rrweb';
let events = [];
let stopFn = rrweb.record({
emit(event) {
events.push(event); // 将 event 存入 events 数组中
if (events.length > 100) { // 当事件数量大于 100 时停止录制
stopFn();
}
},
});
// rrweb 播放器回放
const replayer = new rrweb.Replayer(events);
replayer.play(); // 播放Demo 地址:https://www.rrweb.io/demo/checkout-form
三、实现原理
3.1 包的组成
rrweb 主要由以下三个包构成:
3.1.1 rrweb
主要提供了 record 和 replay 两个方法,record 负责从一开始录制 DOM 全量信息,到后面监听页面的变化(mutation),并将每次的变化 emit 出来传给开发用户。replay 负责将 record 录制的一系列 JSON 数据重组再回放出当时的页面内容。
3.1.2 rrweb-snapshot
主要提供了 record 中用的两个方法:序列化 node 节点获得用于传递变化信息的 serializeNodeWithId 和获取页面快照的 snapshot ;此外还提供了 replay 中用到的一个方法:还原页面快照帮助构建回放 DOM 的 rebuild。
3.1.3 rrweb-player
为 rrweb 设计了一套全新 UI 的播放器,可以实现拖拽进度条、调整播放速度等功能。
3.2 录制过程 record
整体思路:初始化时获取当前页面的全量快照,添加监听器监听页面不同类型的变化(比如 DOM 的变化以及鼠标、滚动以及页面 resize 等的变化),当以上这些变化(mutation)发生时,根据类型的不同分别进行不同的序列化处理,并将处理好的数据 emit 出来。序列化处理时,给每个序列化的 node 节点分配一个 ID,并维护一个从 ID 到 node 节点的映射以及一个 node 节点到序列化后 serializedNode 节点的映射。
Q:为什么需要序列化节点?直接用原生的 node 节点不行吗?
A:由于需要经过网络传输存储在后端,如果直接用 node 节点对象首先是无法通过网络传输(必须要序列化),其次后端也无法存储。因此需要设计出一种合适的(能完整表达一个节点的所有信息,如位置、属性等)数据结构来序列化节点。
3.2.1 前置知识
Node.nodeType(https://developer.mozilla.org/en-US/docs/Web/API/Node/nodeType): 代表 node 节点的不同类型,在 rrweb 中我们常用到的有 ELEMENT_NODE、TEXT_NODE 和 DOCUMENT_NODE 。
双向链表:https://juejin.cn/post/7078915940418748430
MutationObserver(https://developer.mozilla.org/zh-CN/docs/Web/API/MutationObserver):可以监视 DOM 树的变更,当发生变更时会调用传入构建函数的 callback。它最重要的特点是会批量异步处理 DOM 的变化,比如对于多个 appendChild 和 removeChild 会批量处理调用一次 callback。
3.2.2 源码阅读
为了解主流程原理,对源码进行了大幅简化。首先从我们调用的 rrweb.record 方法进入:
function wrapEvent(e) {
return Object.assign(Object.assign({}, e), { timestamp : Date . now () } );
}
function record(options = {}) {
let incrementalSnapshotCount = 0;
wrappedEmit = ( e, isCheckout ) => {
emit ( eventProcessor (e), isCheckout);
if (exceedCount || exceedTime) {
takeFullSnapshot ( true );
}
};
takeFullSnapshot = (isCheckout = false) => {
wrappedEmit(wrapEvent({
type: EventType.Meta,
data: {
href: window.location.href,
width: getWindowWidth(),
height: getWindowHeight(),
},
}), isCheckout);
// 获取了文档的全量快照,同时维护了一个节点和 ID 的映射 mirror
const node = snapshot ( document , {
mirror,
// ...
});
wrappedEmit ( wrapEvent ({
type : EventType . FullSnapshot ,
data: {
node,
initialOffset: {
// left: ,
// top: ,
},
},
}));
};
const handlers = [];
const observe = ( doc ) => {
return initObservers ({
mutationCb : ( m ) => wrappedEmit ( wrapEvent ({ type : EventType . IncrementalSnapshot , data : Object . assign ({ source : IncrementalSource . Mutation }, m), })),
mousemoveCb : ( positions, source ) => wrappedEmit ( wrapEvent ({
type : EventType . IncrementalSnapshot ,
data : {
source,
positions,
},
})),
// 其他监听器...
}, hooks);
};
const init = () => {
takeFullSnapshot ();
handlers. push ( observe ( document ));
recording = true ;
};
init ();
return () => {
handlers.forEach((h) => h());
recording = false;
};
}record 中定义了多个关键的函数。init 中执行了 takeFullSnapshot 和 observe(document):
takeFullSnapshot:获取文档的全量快照,作为后面增量快照的基准。首先 emit 了一个 meta 信息,然后执行snapshot(document, {...}),会遍历整个文档树,为每个节点创建一个唯一的 ID 并序列化,维护在 mirror 对象的映射中。mirror 中维护了一个 ID 到原生 node 节点的映射和一个原生 node 节点到序列化后的 serializedNode 的映射,后面所有对 DOM 的操作变化都会实时维护在这两个映射中。这个映射主要用在回放中,可以试想如果只在本地构建重组 DOM 树,可以直接用原生的 node 节点组装起来(直接利用原生 node 的自带属性,如parentNode、nextSibling、previousSibling等);但是如果需要传递一系列增量快照到远端存储并试图重建时,就必须传递可以序列化的信息,必须要有 ID 和序列化后的节点信息,这样用每个节点的 ID 加上这个节点本身的一些信息(比如节点类型,属性等)就可以重新构建。最后 emit 一个 fullSnapshot 信息,将序列化好的整个 DOM 树当作参数。observe:初始化各种监听器,以两种主要的变化举例:鼠标的移动和 DOM 的变化。它们都包了两层,第一层先通过wrapEvent封装一个带timestamp时间戳(用于后续还原播放时使用)的 payload,然后再执行wrappedEmit函数,这个函数包装了外界传参进来的emit方法,也就是说带时间戳的 payload 会被作为入参传给 rrweb 使用的开发者所写的emit方法。
这些 payload 根据变化类型的不同会有各自的属性,来帮助播放时还原录制的现场,比如鼠标的移动就需要鼠标的位置信息:
function initObservers(o, hooks = {}) {
const mutationObserver = initMutationObserver(o, o.doc);
const mousemoveHandler = initMoveObserver(o);
// 其他监听器...
}
function initMoveObserver({ mousemoveCb, sampling, doc, mirror, }) {
const threshold = typeof sampling.mousemove === 'number' ? sampling.mousemove : 50;
const callbackThreshold = typeof sampling.mousemoveCallback === 'number'
? sampling.mousemoveCallback
: 500;
let positions = [];
const wrappedCb = throttle((source) => {
const totalOffset = Date.now() - timeBaseline;
mousemoveCb (positions. map ( ( p ) => {
p. timeOffset -= totalOffset;
return p;
}), source);
positions = [];
}, callbackThreshold);
const updatePosition = throttle((evt) => {
const target = getEventTarget(evt);
const { clientX, clientY } = isTouchEvent(evt)
? evt.changedTouches[0]
: evt;
positions. push ({
x : clientX,
y : clientY,
id : mirror. getId (target),
timeOffset : Date . now () - timeBaseline,
});
wrappedCb(typeof DragEvent !== 'undefined' && evt instanceof DragEvent
? IncrementalSource.Drag
: evt instanceof MouseEvent
? IncrementalSource.MouseMove
: IncrementalSource.TouchMove);
}, threshold, {
trailing: false,
});
// 使用 addEventListener 就可以实现
const handlers = [
on ( 'mousemove' , updatePosition, doc),
on ( 'touchmove' , updatePosition, doc),
on ( 'drag' , updatePosition, doc),
];
return () => {
handlers.forEach((h) => h());
};
}首先对几种鼠标变化添加 addEventListener 监听器,当发生变化时执行 updatePosition 函数把获得的 position 作为 mousemoveCb 函数的入参传出来,最终给到上文的 emit 方法。注意其中做了节流的处理,rrweb 支持用 sampling 属性来配置抽样的频率。
再来看看我们最关注的 DOM 变化是如何转换成增量快照的。和鼠标移动的处理方式一样,在 initObservers 函数中调用处理 mutation 的 initMutationObserver 函数,其中我们创造了一个 MutationBuffer 对象 mutationBuffer 并 init 用来存放每次的 DOM 变化,然后利用创造一个 MutationObserver 对象 observer,observer 观察文档所有内容的变化。
function initMutationObserver(options, rootEl) {
const mutationBuffer = new MutationBuffer(); // 存放本次变化有关的信息
mutationBuffers.push(mutationBuffer);
mutationBuffer.init(options);
const observer = new MutationObserver(mutationBuffer.processMutations.bind(mutationBuffer));
observer.observe(rootEl, {
attributes: true,
attributeOldValue: true,
characterData: true,
characterDataOldValue: true,
childList: true,
subtree: true,
});
return observer;
}当变化发生时,执行 mutationBuffer 的一个方法 processMutations,mutation 的类型有三种:
characterData:纯文本类型的变动;
attributes:节点属性类的变动;
childList:节点的新增、删除和移动。
我们最关注第三类节点的变化:
class MutationBuffer {
constructor() {
this.frozen = false;
this.locked = false;
this.removes = [];
this.mapRemoves = [];
this.addedSet = new Set();
this.movedSet = new Set();
this . processMutations = ( mutations ) => {
mutations. forEach ( this . processMutation );
this . emit ();
};
this.emit = () => {
// ...
};
this.processMutation = (m) => {
switch (m. type ) { // 判断mutation的类型
case 'characterData': {
// ...
}
case 'attributes': {
// ...
}
case 'childList' : {
m. addedNodes . forEach ( ( n ) => this . genAdds (n, m. target ));
m. removedNodes . forEach ( ( n ) => {
const nodeId = this.mirror.getId(n);
const parentId = isShadowRoot(m.target)
? this.mirror.getId(m.target.host)
: this.mirror.getId(m.target);
if (isBlocked(m.target, this.blockClass, this.blockSelector, false) ||
isIgnored(n, this.mirror) ||
!isSerialized(n, this.mirror)) {
return;
}
else if (this.addedSet.has(m.target) && nodeId === -1) ;
else if (isAncestorRemoved(m.target, this.mirror)) ;
else if (this.movedSet.has(n) &&
this.movedMap[moveKey(nodeId, parentId)]) {
deepDelete(this.movedSet, n);
}
else {
this . removes . push ({
parentId,
id : nodeId,
isShadow : isShadowRoot (m. target ) && isNativeShadowDom (m. target )
? true
: undefined ,
});
}
});
}
}
};
this . genAdds = ( n, target ) => {
if ( this . mirror . hasNode (n)) {
this . movedSet . add (n);
}
else {
this . addedSet . add (n);
}
if (! isBlocked (n, this . blockClass , this . blockSelector , false ))
n. childNodes . forEach ( ( childN ) => this . genAdds (childN));
};
}
}mutationBuffer 对象维护了两个集合:addedSet、movedSet,还有一个 removes 数组,用于处理三种节点的变化:
新增节点(
mutation.addedNodes): 直接添加到addedSet中,对于这个节点的childNodes****中每个子节点都去递归执行genAdds函数;删除节点(
mutation.removedNodes): 由于MutationObserver批量异步处理的特性,如果本次变化中出现先增加 A 节点,再删除 A 节点,此次变化的addedNodes和removedNodes都会有 A 节点。按照处理顺序会先把该节点添加进addedSet中,再处理removedNodes时应该把它从addedSet中删掉。对于需要真正删掉之前已有节点的情况,我们在回放时只需要拿到它的父节点和被删除的节点本身,所以直接将它的父节点 ID 和它本身的 ID (由于是已有的节点,所以在我们的 mirror 映射中一定能找到对应的节点信息)存放到removes数组当中即可;移动节点: 当我们的映射
mirror中已经存在节点 n 时,代表本次 mutation 的节点之前就在我们的 DOM 结构中。移动产生的根本原因也一定是先removeChild,再appendChild这个移除的节点到新的父节点下。因此在MutationObserver中会先产生一个mutation.removedNodes的记录,再产生一个mutation.addedNodes的记录。首先按照删除节点的逻辑,会存放该节点信息到removes数组中,然后到genAdds****函数中发现此节点在 mirror 映射中,因此属于移动的节点,添加到movedSet中,同样递归它的子节点执行genAdds函数。
添加节点时使用集合 Set 的原因:
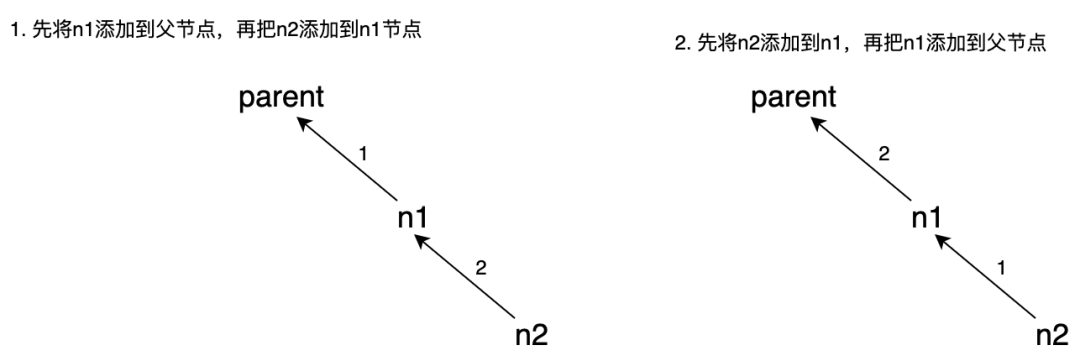
以下两种操作会生成相同的 DOM 结构,但是产生不同的 mutation 记录:
会生成两条 mutation 记录,但是由于 MutationObserver 的批量异步处理特性,在第一条 mutation 记录中拿到的 n1 节点此时已经有 childNodes 了(即 n2 节点);
只会产生一条 mutation 记录,即 n1 添加到父节点中,为了不落下 n2 节点,需要对这条 mutation 记录遍历它的所有子节点(上文新增节点中有提到)。
那么如果对于第一种情况,处理 n1 时遍历它的子节点添加了一次 n2,再处理第二条 mutation 记录 n2 节点时又会添加一遍,因此为了去重需要使用集合 Set。而删除节点则无需用集合,因为在回放 removeChild 时自然会把所有子节点都删掉。
在 processMutations 中,以上工作将本次回调的所有变动都收集好了,接下来继续执行 emit 方法:
共识:序列化节点的顺序应当是从位置能确定的节点(父节点和兄弟节点已经过序列化)开始。对于不确定的节点,需要先存储起来( rrweb 就是利用了双向链表存储),待能确定后再序列化。
this.emit = () => {
if (this.frozen || this.locked) {
return;
}
const adds = [];
const addList = new DoubleLinkedList ();
const getNextId = (n) => {
// 获取nextSibling的ID
};
const pushAdd = (n) => {
if (!n.parentNode) {
return;
}
const parentId = this.mirror.getId(n.parentNode);
const nextId = getNextId(n);
if (parentId === - 1 || nextId === - 1 ) {
return addList. addNode (n);
}
const sn = serializeNodeWithId (n, {
// options...
});
if (sn) {
adds. push ({
parentId,
nextId,
node : sn,
});
}
};
for (const n of Array.from(this.movedSet.values())) {
if (isParentRemoved(this.removes, n, this.mirror) && !this.movedSet.has(n.parentNode)) {
continue;
}
pushAdd(n);
}
for (const n of Array.from(this.addedSet.values())) {
if (!isAncestorInSet(this.droppedSet, n) && !isParentRemoved(this.removes, n, this.mirror)) {
pushAdd(n);
}
else if (isAncestorInSet(this.movedSet, n)) {
pushAdd(n);
}
else {
this.droppedSet.add(n);
}
}
let candidate = null;
while (addList.length) {
let node = null;
if (candidate) {
const parentId = this.mirror.getId(candidate.value.parentNode);
const nextId = getNextId(candidate.value);
if (parentId !== -1 && nextId !== -1) {
node = candidate;
}
}
if (!node) {
for (let index = addList. length - 1 ; index >= 0 ; index--) {
const _node = addList.get(index);
if (_node) {
const parentId = this.mirror.getId(_node.value.parentNode);
const nextId = getNextId(_node.value);
if (nextId === -1)
continue;
else if (parentId !== -1) {
node = _node;
break;
}
}
}
}
if (!node) {
while (addList.head) {
addList.removeNode(addList.head.value);
}
break;
}
candidate = node.previous;
addList.removeNode(node.value);
pushAdd(node.value);
}
const payload = {
// 省略文本和属性部分代码
removes : this . removes ,
adds,
};
this . mutationCb (payload);
};emit 方法最终会组合出一个代表本次 DOM 变化的 payload 传给 mutationCb(在 mutationBuffer init 时传入)执行,最终一路向上追溯到执行 rrweb 使用方所写的 emit 函数。
我们分析下是如何拿到这个 payload 的:
对于删除的节点,直接使用 removes 数组;对于新增(或移动)的节点,我们在回放时需要用到它的父节点、兄弟节点和它本身,定义 adds 数组存放新增的节点信息。首先遍历 movedSet,如果节点的父节点在本次回调中被删除了则不处理,否则执行 pushAdd 函数,然后遍历 addedSet,与 movedSet 处理相同。
在 pushAdd 函数中,首先去获取当前被添加节点的父节点 ID 和下一相邻的兄弟节点 ID,如果发现父节点或者下一相邻节点尚未序列化(即尚未来得及维护 ID 加入 mirror 映射),将这个节点加入双向链表 addList 中(双向链表的 addNode 方法是按照 DOM 节点顺序来添加节点的,根据节点的 previousSibling 和 nextSibling 属性能找到前一兄弟节点的放到它后面,能找到后一兄弟节点的放到它前面,都找不到放到 head。也就是层级越深越靠前、同一层级按 DOM 顺序排位)先存储起来。 如果能找到父节点 ID 和 下一相邻节点 ID 则对这个节点序列化 serializeNodeWithId,将序列化的节点和 parentId 以及 nextId 作为当前被添加节点的全部信息存到 adds 数组中。
处理完 movedSet 和 addedSet 后,遍历 addList,由于需要用到 parentId 和 nextId ,所以需要先序列化层级浅、同层级 DOM 顺序靠后的节点,也就是我们 addList 存储的相反顺序。所以从最后一个节点开始遍历 addList 双向链表,对每个节点执行 pushAdd 函数序列化(由于链表的最后一个节点 N 一定是没有下一兄弟节点的,所以在它执行 pushAdd 函数时可以走到序列化的步骤并添加它的有关信息到 adds 数组中,这样前一节点 N - 1 也可以拿到 N 的 ID)。
到这里所有被添加的节点也都处理完成了,adds 数组就是我们 payload 需要的,也就完成了从一次 mutationObserver 回调的多条记录到一个 payload 中的文本、属性、添加节点信息、移除节点信息的转变。
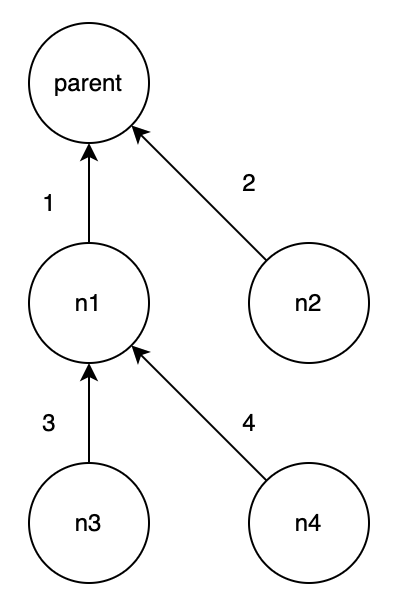
3.2.3 举例
举一个稍微复杂的例子,按 1234 的顺序添加节点到 DOM 中:
function App() {
useEffect(() => {
record({
emit(event) {
if (event.data.source === 0) {
console.log('events', event)
}
}
});
}, []);
return (
<div className="App">
<div id='parent' />
<button
onClick={() => {
const p = document.querySelector('#parent');
const n1 = document.createElement('div');
n1.id = '1';
const n2 = document.createElement('div');
n2.id = '2';
const n3 = document.createElement('div');
n3.id = '3';
const n4 = document.createElement('div');
n4.id = '4';
p.appendChild(n1);
p.appendChild(n2);
n1.appendChild(n3);
n1.appendChild(n4);
}}
>
test
</button>
</div>
);
}observer 返回了四条 mutation 变化记录:

由于 MutationObserver 的批量异步处理方式,第一条新增的 n1 节点的 childNodes 已经有 n3 和 n4 节点了:

对于第一条 mutation 执行 processMutation,由于是新增节点会执行 m.addedNodes.forEach((n) => this.genAdds(n, m.target));。 genAdds 函数会对 n1 节点的子节点递归,所以第一次执行完 n1 节点时,addedSet 中已经存在了 n1 和它的两个子节点 n3、n4:

接下来执行第二条 mutation 即新增 n2 节点,执行完成后 addedSet 中就有全部四个新节点了:

最后执行第三、四条 mutation,但是 addedSet 不会有变化。
此时转化的第一步 processMutation 就完成了,继续第二步 this.emit() 转换成我们需要的 payload:
遍历 addedSet,先将 n1 节点取出执行 pushAdd(n1),由于 n1 的 nextSibling n2 节点尚未序列化,需要先存储 n1 到双向链表 addList 的 head 位置待 n2 序列化后再处理。接着取 n3 节点执行 pushAdd(n3),和 n1 一样,n3 的 nextSibling n4 节点尚未序列化,需要先存到 addList 中,按双向链表添加节点的规则,n3 的前一兄弟节点和后一兄弟节点都没有在双向链表中,所以需要将 n3 添加到 head 位置上,此时双向链表的结构是:
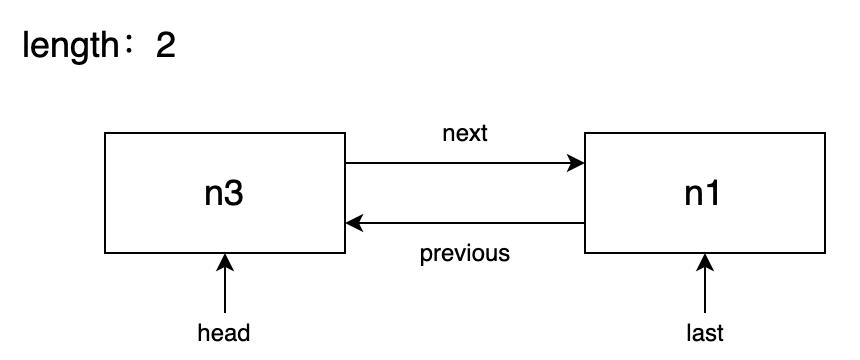
接下来处理 n4 节点,虽然 n4 的 nextSibling 是 null ( nextId 也是 null ),但是它的父节点 n1 依然没有序列化(也暂存在双向链表中等待稍后序列化),所以 n4 也命中了 if (parentId === -1|| nextId === -1) 的判断需要存到链表中,由于 n4 的前一兄弟节点 n3 在链表头部,所以按照双向链表添加节点的规则需要将 n4 存到 n3 的后面,此时双向链表的结构是:
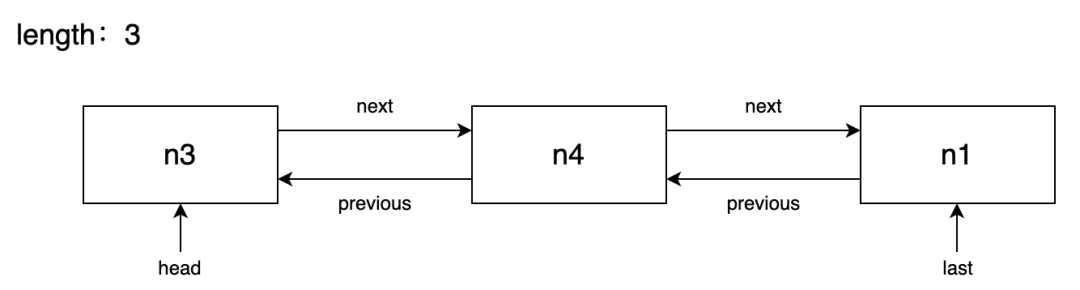
最后处理 n2 节点,由于 n2 的父节点是已经在 mirror 映射中的,所以能取到 parentId,它没有下一兄弟节点,所以 nextId 是 null,无需添加到链表中,可以直接序列化 serializeNodeWithId(n2, {...}),把序列化的结果以及 parentId 和 nextId 一起存到 adds 数组中。
对 addedSet 的四个节点遍历完成后,最后一步是倒序处理双向链表暂存的那些节点。最后一个节点是 n1,n1 的
nextSibling n2 已经序列化了,执行 pushAdd(n1),能拿到 n1 的 parentId 和 nextId,直接序列化 serializeNodeWithId(n1, {...}),将拿到的序列化节点以及 parentId 和 nextId 一起存放到 adds 数组中。此时 candidate 指向 n1 的 previous 节点也就是 n4,和 n1 同样的处理方式,将序列化的 n4 节点以及 parentId(也就是刚刚序列化的 n1 节点的 ID)和 nextId(null)一起存到 adds 数组中。最后是 head 节点即 n3 节点,将序列化的 n3 以及parentId(n1 的 ID)和 nextId(null)一起存到 adds 数组中。
到这里双向链表中暂存的三个节点也处理完了,此时 adds 数组中保存了全部处理后的四个节点:
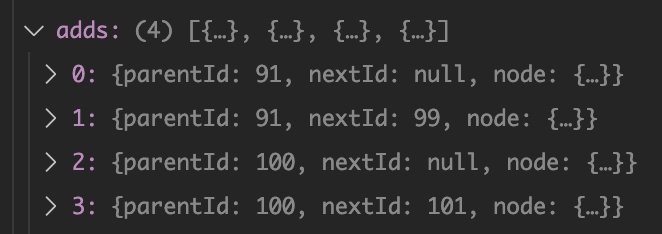
依次是 n2、n1、n4 和 n3。组装好的 payload 如下:
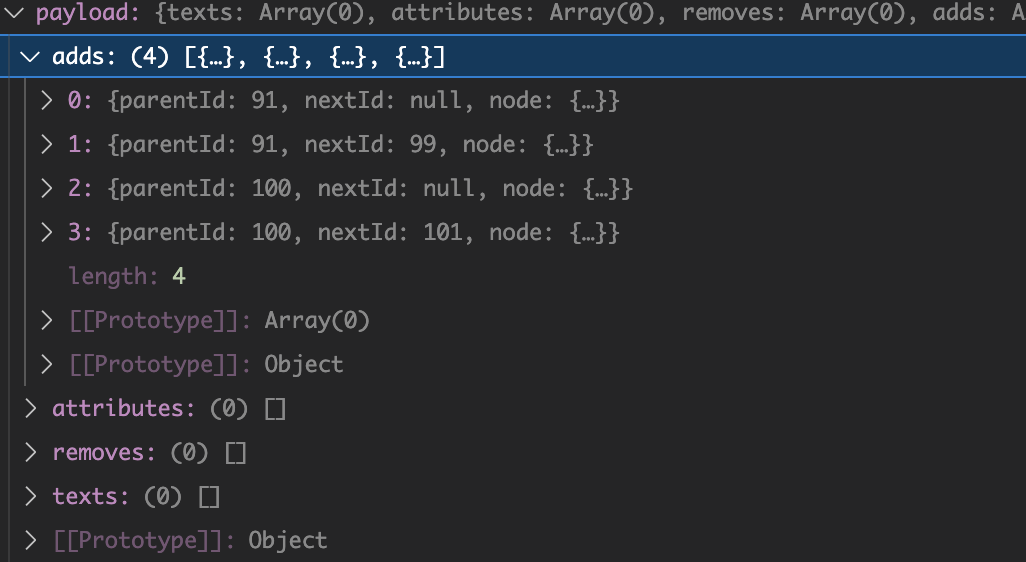
最后经过一系列包装处理这个 payload 传递给使用者写的 emit 方法去执行,看到浏览器打印的信息如下:
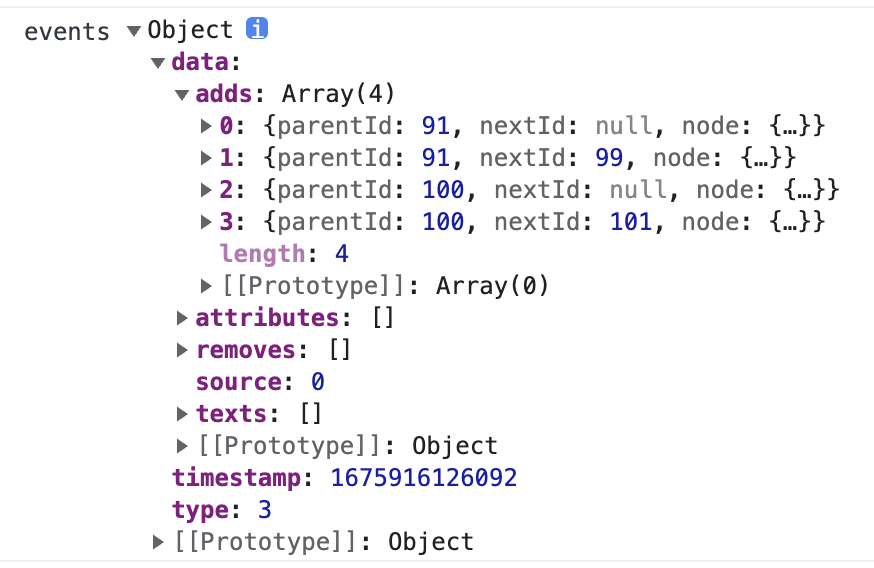
payload 基础上加一个 source 属性构成 data 字段,source 表示增量快照的类型,0 代表是 DOM 类的 Mutation,另外 timestamp 和 type 是所有 payload 都会包装的两个属性,timestamp 用于表示开始录屏到现在过了多久用于播放器回放,type 表示这个 payload 的类型,3 代表是增量快照,2 代表是全量快照。
export enum EventType {
DomContentLoaded,
Load,
FullSnapshot,
IncrementalSnapshot,
Meta,
Custom,
Plugin,
}3.3 回放过程 replay
3.3.1 前置知识
XState(https://xstate.js.org/docs/zh/):有限状态机,通过各种不同的 action 管理状态的流转。
requestAnimationFrame(https://developer.mozilla.org/zh-CN/docs/Web/API/window/requestAnimationFrame):告诉浏览器执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。该方法需要传入一个回调函数作为参数,该回调函数会在浏览器下一次重绘之前执行。
3.3.2 重建 DOM 流程
在回放过程中,播放器是用 XState 做状态管理的,有两个状态:播放 playing 和暂停 paused,初始状态是暂停。创建 Replayer 播放器实例时,会创建两个 service:createPlayerService 用于处理事件回放的逻辑,createSpeedService 用于控制播放速度。然后会用事件中的第一个全量快照来还原一个初始的 DOM 树作为后续添加增量快照变更的基础。与录屏时相同,对每个节点也要做序列化 buildNodeWithSN 并维护同样的 mirror 映射。在构建全量 DOM 树和后面处理增量快照时,都是结合目标节点本身、父节点和兄弟节点的信息来定位位置和属性,再调用 appendChild、insertBefore、removeChild 这几个 Node 节点的方法(或者其他处理节点属性的方法)。调用 replayer 实例上的 play 方法就开始按时间顺序还原增量快照了,会向 playerService 派发 'PLAY' 事件,此时状态机就从初始的 paused 转变为 playing。当调用 replayer 实例上的 pause 方法时,会向 playerService 派发 'PAUSE' 事件,此时状态由 playing 转变为 paused。
回放重建 DOM 与录屏时的区别是:录屏时先对 DOM 做改动再产出序列化节点,回放重建是先根据 event 序列化节点,再改动 DOM 结构。两者各自都随时维护着一个 mirror 映射。
3.3.3 播放器
rrweb 的播放器是在一个 iframe 上回放录屏的,为了阻断 iframe 上的用户交互需要做一些特殊处理,比如在 iframe 标签上设置 CSS 属性:
pointer-events: none;为了去脚本化,将 <script> 标签替换为 <noscript> 标签,另外将 iframe 的 sandbox 属性设置为 “allow-same-origin”,可以防止任何脚本的执行。
播放器的进度条是如何控制与每个增量快照发生的时间对应上呢?
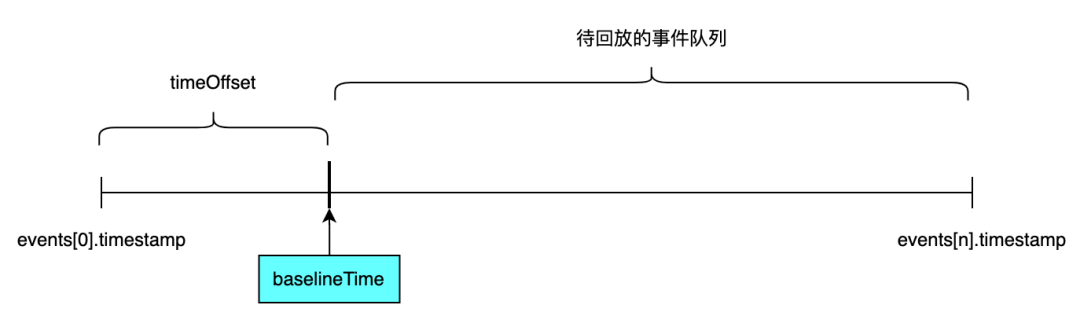
比如在播放时用户点击进度条上的某一点,这一点距离初始时间点是 timeOffset 长度,点击的这个点可以叫做基线时间点 baselineTime,rrweb 会根据这个点将所有的事件分成两部分:前一部分是在基线时间点前已经发生的事件队列,后一部分是待回放的事件队列。把前一部分事件同步还原构建完成,作为后面队列的全量基准 DOM 树,再继续异步地按照正确的时间间隔构建后面的增量快照。
rrweb 借助 requestAnimationFrame 实现了一个高精度的计时器 Timer。上面介绍待回放的事件队列会被加到定时器的 actions 中,当每次requestAnimationFrame 调用回调函数 check 时,会判断当前时间与下一个待回放事件的时间先后顺序,如果发现当前时间大于等于下一事件的播放时间了,就去 doAction 执行它,确保绝大部分情况下增量快照的重放延迟不超过一帧。
public start() {
this.timeOffset = 0;
let lastTimestamp = performance.now();
const check = () => {
const time = performance.now();
this.timeOffset += (time - lastTimestamp) * this.speed;
lastTimestamp = time;
while (this.actions.length) {
const action = this.actions[0];
if ( this . timeOffset >= action. delay ) {
this . actions . shift ();
action. doAction ();
} else {
break;
}
}
if ( this . actions . length > 0 || this . liveMode ) {
this . raf = requestAnimationFrame (check);
}
};
this . raf = requestAnimationFrame (check);
}四、与 WebRTC 对比
| rrweb | WebRTC | |
|---|---|---|
| 录制显示器上的完整信息 | 仅能录制当前浏览器 TAB 页 | ✅ |
| 用户无感知录制 | ✅ | 需要用户同意并选择录制的屏幕内容 |
| 录制内容大小 | 均为 JSON 数据,且页面无变动时不会增加大小 | 与录制时间成正比,占据存储空间较大 |
| 播放器 | 提供了一套独立设计的播放器,功能完整 | 需自行寻找合适的播放器 |
| 回放视频清晰度 | 完全还原 DOM 结构 | 清晰度会有损失 |
参考资料:
状态机系列 (一) : 令人头疼的状态管理:https://zhuanlan.zhihu.com/p/406551473
rrweb 录屏原理浅析:https://segmentfault.com/a/1190000041657578
rrweb 带你还原问题现场:https://musicfe.com/rrweb/

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)