
yolov5代码解读之detect.py文件【超详细的好吗!点进来看阿很用心的!】
其实就是因为我们在sys.path路径中存在了yolov5-master这个文件夹的路径,所以导包的时候,它就能知道要在yolov5-master这个文件夹里面去找models文件夹里面的common。warmup就是一个热身环节,它内部就是初始化了一张空白的图片传入到模型中,让模型执行了一次前馈传播,相当于随便给了gpu一张图片,让gpu跑了一遍,让gpu有一个“热身”环节哈哈,完了之后再把自己
yolov5的代码一直在更新,所以你们代码有些部分可能不太一样,但大差不差。
先给大家看一下项目结构:(最好有这个项目,且跑通过)
detect.py文件:它可以预测视频、图片文件夹、网络流等等。
如何执行这个项目前面已经讲过了:从零开始yolov5模型训练【绝对能学会】
执行这个代码首先就是运行前面的这一部分:
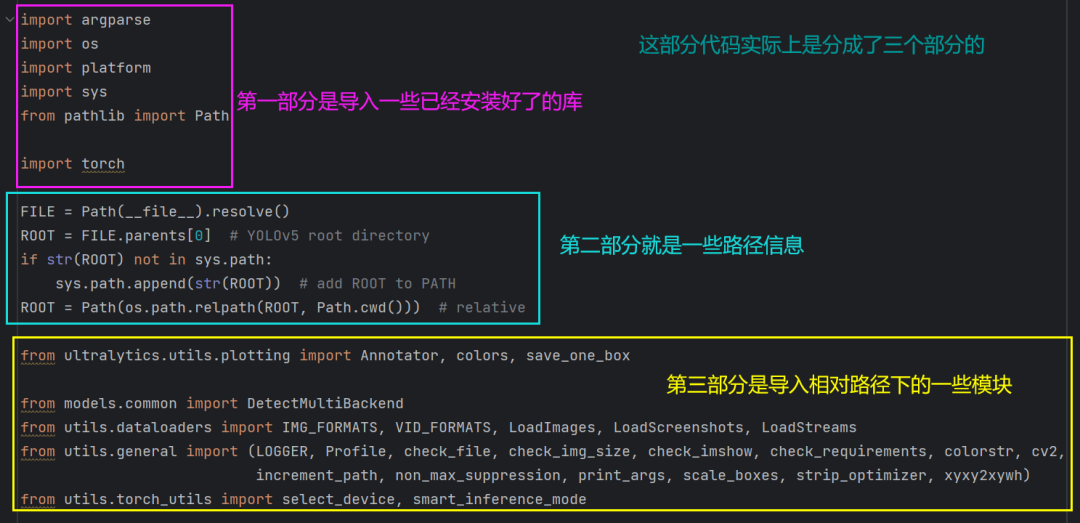
对于第三部分的话,看一下这个就很明了:

对于第二部分:
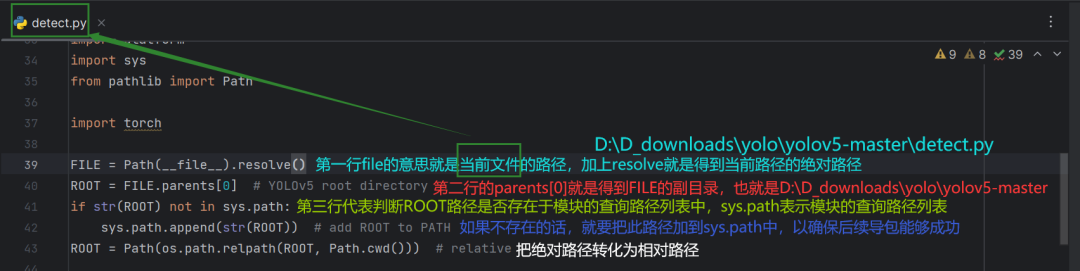
什么是模块的查询路径列表:(sys.path)
就比如我们刚刚导入的models.common的那一行,我们执行的是detect.py文件,那么这个文件是如何知道这个模块在哪呢?其实就是因为我们在sys.path路径中存在了yolov5-master这个文件夹的路径,所以导包的时候,它就能知道要在yolov5-master这个文件夹里面去找models文件夹里面的common。如果sys.path里面没有yolov5-master这个文件夹里面的路径的话,导包就会出现错误。第三行的代码也是为了确保ROOT路径是存在于yolov5-master这个文件夹下的。
当把包导完之后,它就会跳到文件的最下面去执行if __name__当中的代码:

先聊聊命令行参数的意思:
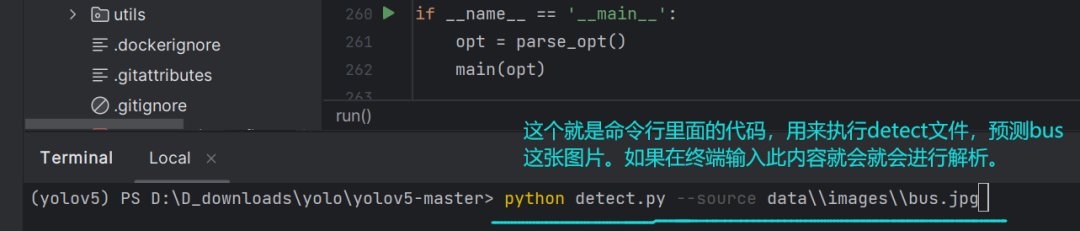
再聊聊if __name__中的第一行代码的内容:(来到parse_opt函数)
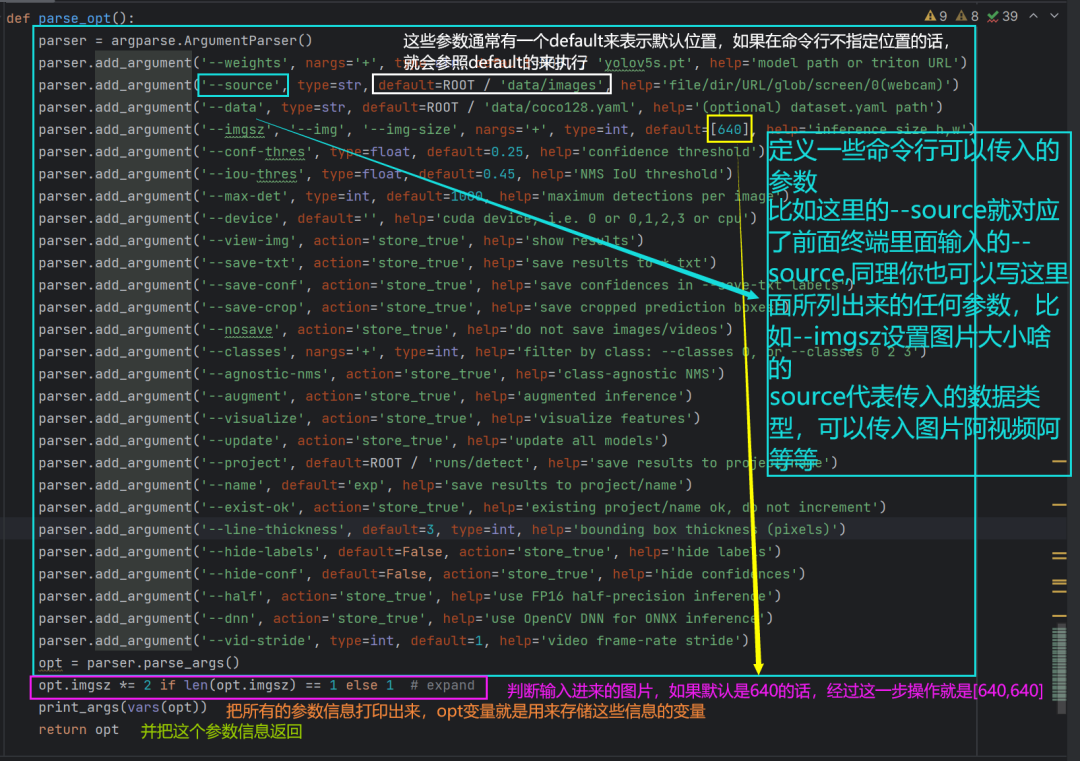
参数信息打印出来大概就是这样:


然后来看看run函数吧:
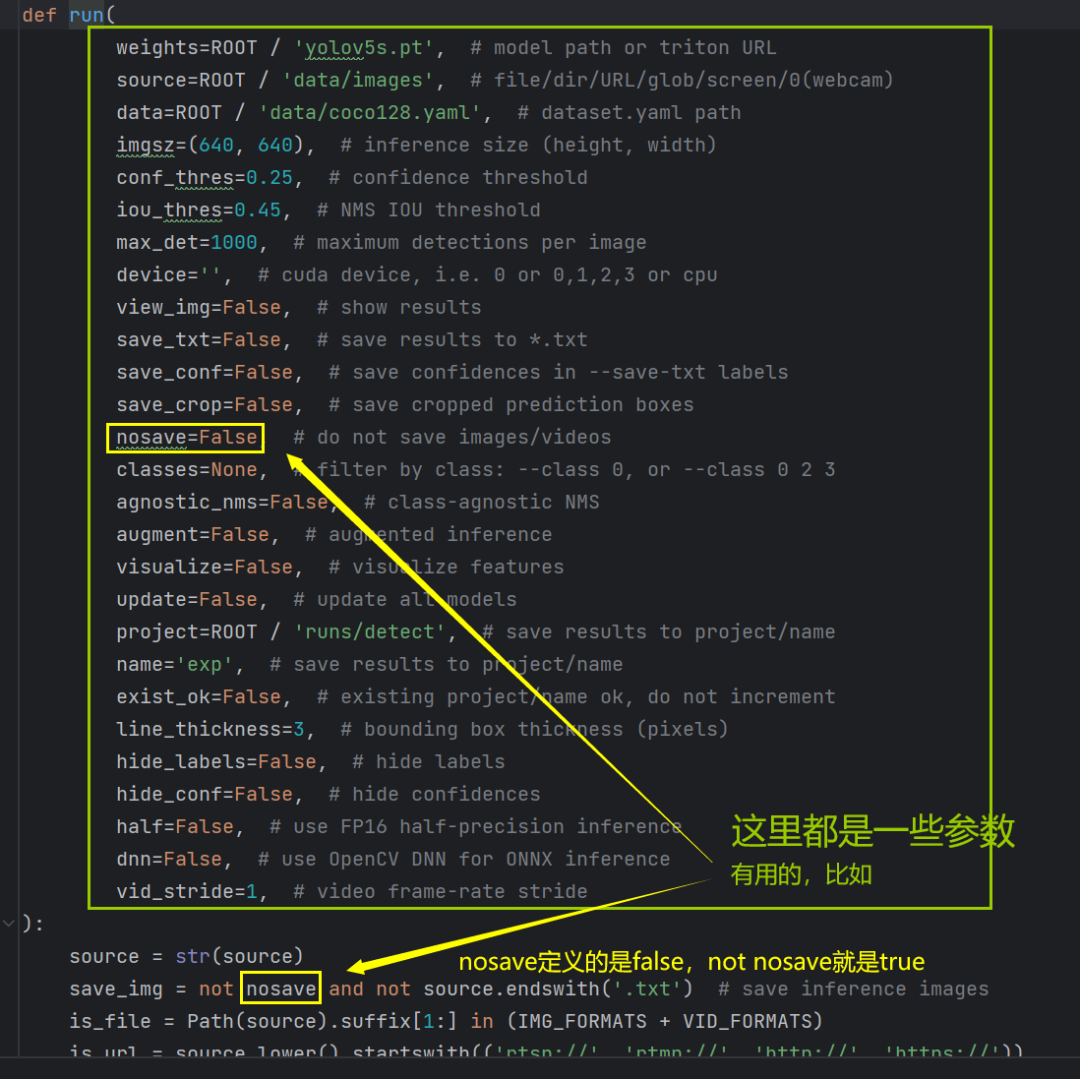
run函数第一部分代码:

第三行is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)的意思:
is_file呢就是表示我们传入的地址是不是一个文件地址;
suffix表示的就是后缀的意思,就是“.jpg”;[1:]表示从“j”开头,所以Path(source).suffix[1:]表示的就是“jpg"。
然后判断jpg是不是在IMG_FORMATS +和VID_FORMATS这两个格式中。
那么这两个格式又是啥呢,点进来看(按住crtl,然后鼠标点击这两个美丽的单词):

所以我们可以看到jpg是位于这两个格式中的,因此is_file也是表示的true。


(webcam是false哦,这个能推出来吧,不能推出来建议了解一下or和and)

然后到我们的run函数中的第二部分代码(94和95行)
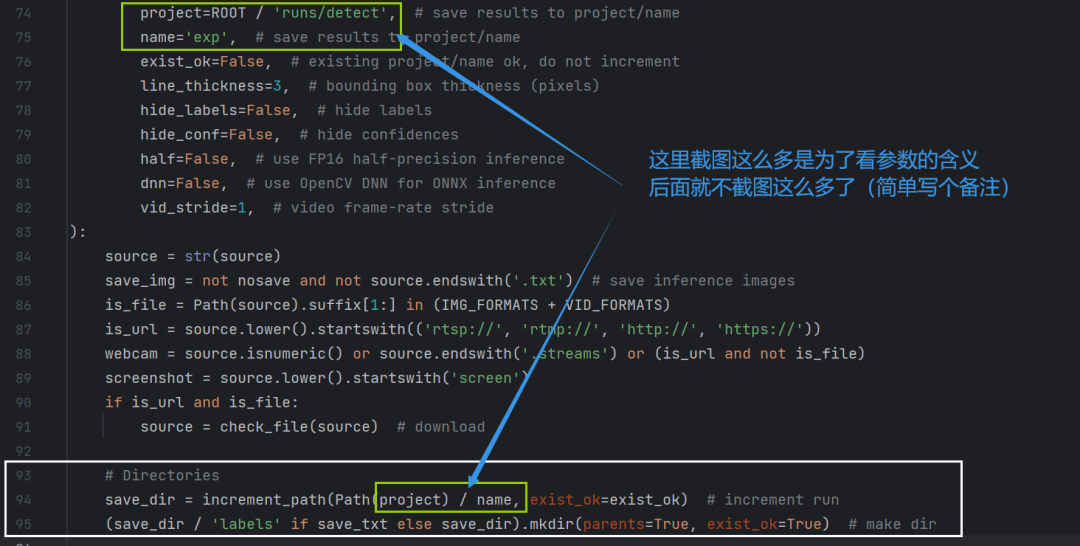
第94行的含义:
save_dir就是新建一个保存结果的文件夹;
project代表:ROOT / 'runs/detect', name代表'exp', 用“/”把他们两个拼接起来;
increment代表增量,increment_path表示增量路径,啥叫增量路径呢:
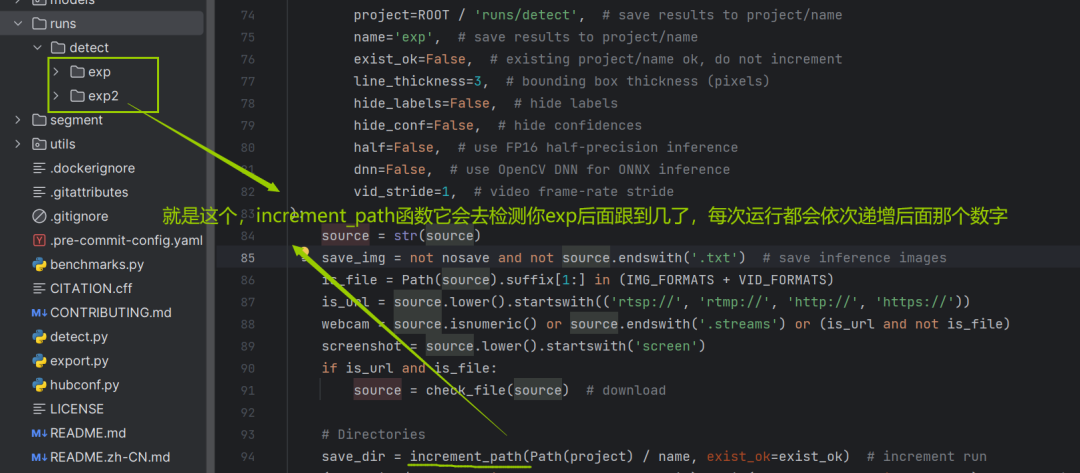
95行:

run函数的第三部分(模型加载部分):
这一部分的话,先看一下多后端:
具体就是第99句的参数含义:model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
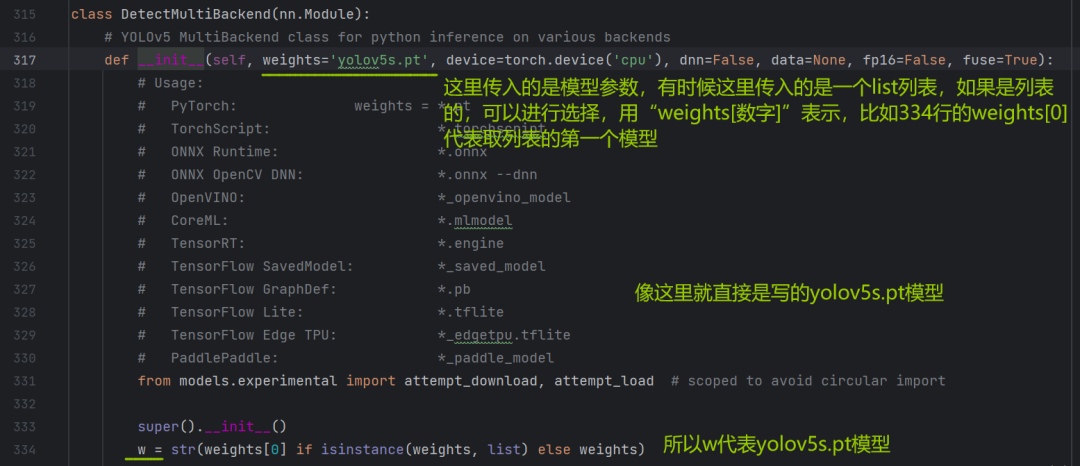
weights是run函数开头参数定义的:(可以看到他用的是yolov5的s这个模型,yolov5还有其他的比如m、x、n、l等,这里默认用的s):
weights=ROOT / 'yolov5s.pt', # model path or triton URLdevice就是使用gpu还是cpu;
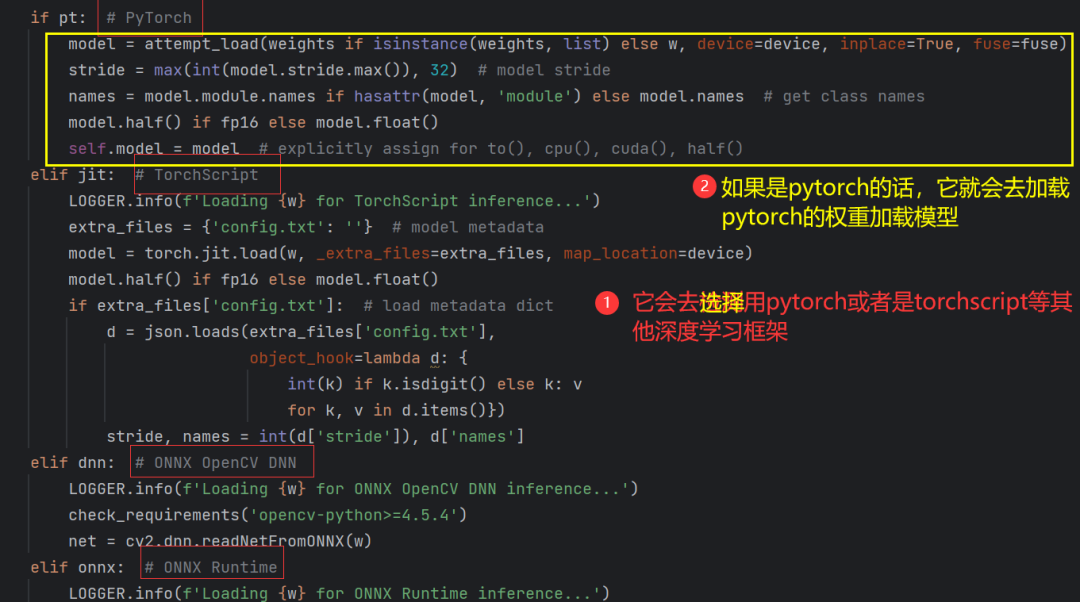
dnn默认的false(run函数开头定义,点进多后端可以k看到dnn代表的就是onnx opencv dnn模型);
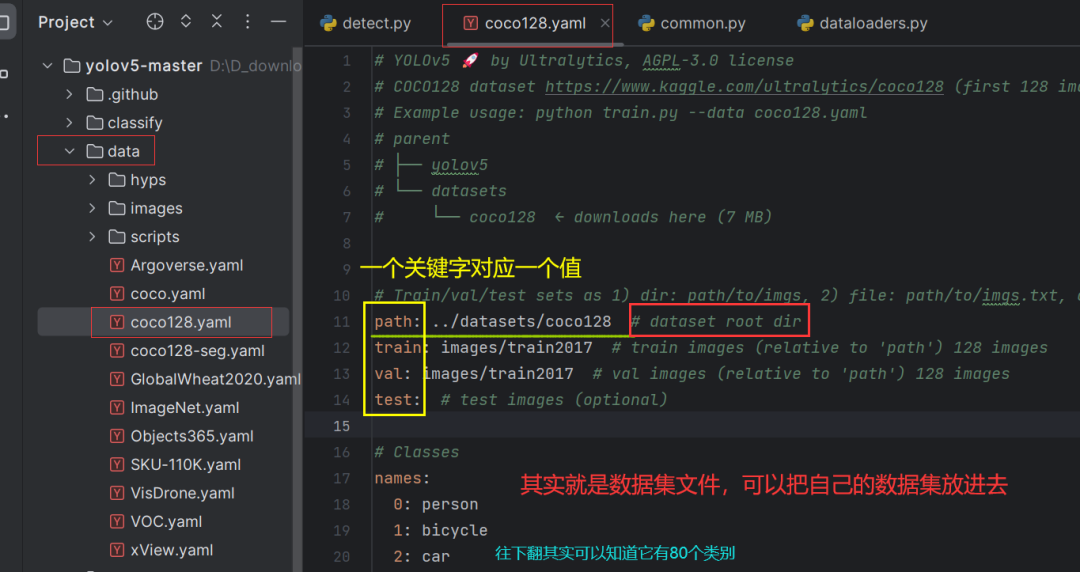
data是“ROOT / 'data/coco128.yaml'”这个文件,点进去看一下:
half表示半精度推理过程,默认为false,也就是没用到,不管他~
多后端点进去(模型选择):
再看看多后端是如何创建的:



然后这是第三部分的其他代码:

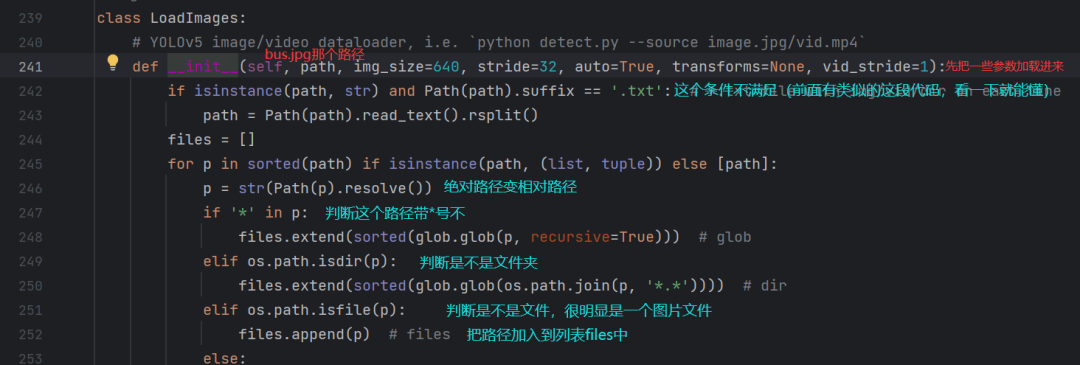
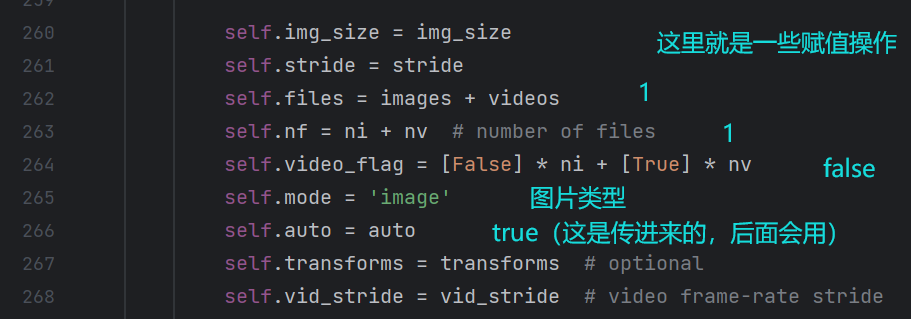
run函数的第四部分(dataloader部分):
(batch_size=1,每次输入一张图片)
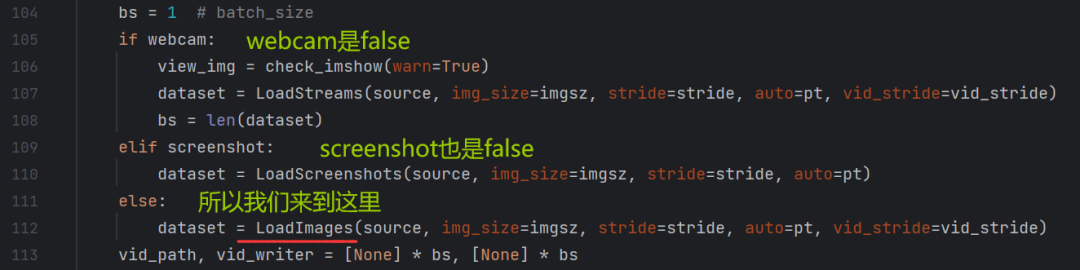
(vid_path,vid_writer列表长度都是1,后面有用)
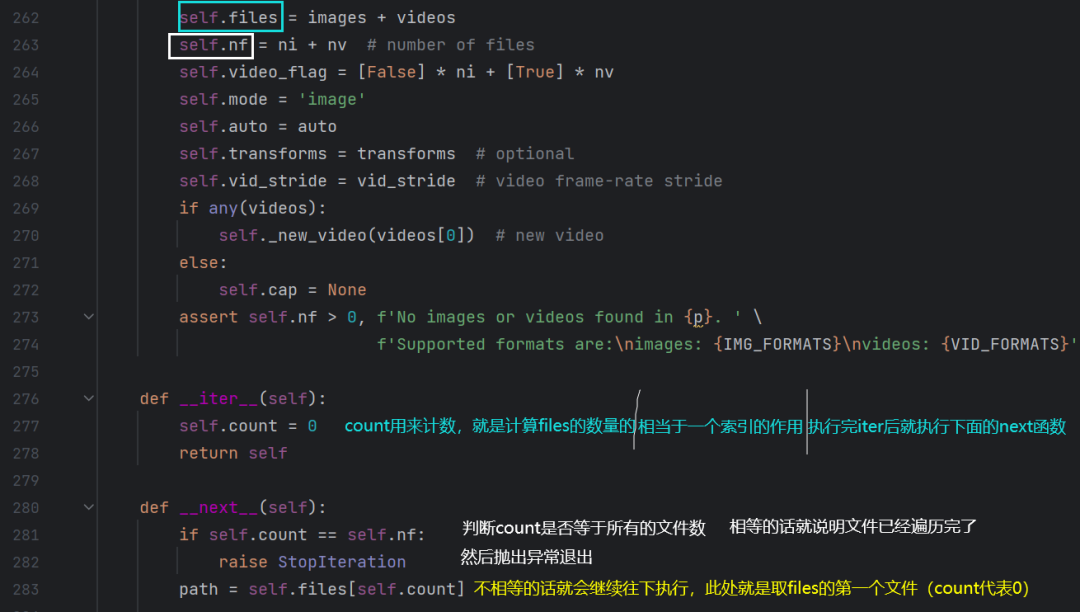
LoadImages点进去看看是个啥:


run函数的第五部分(推理部分):
(先看dataloders.py下面几段代码)
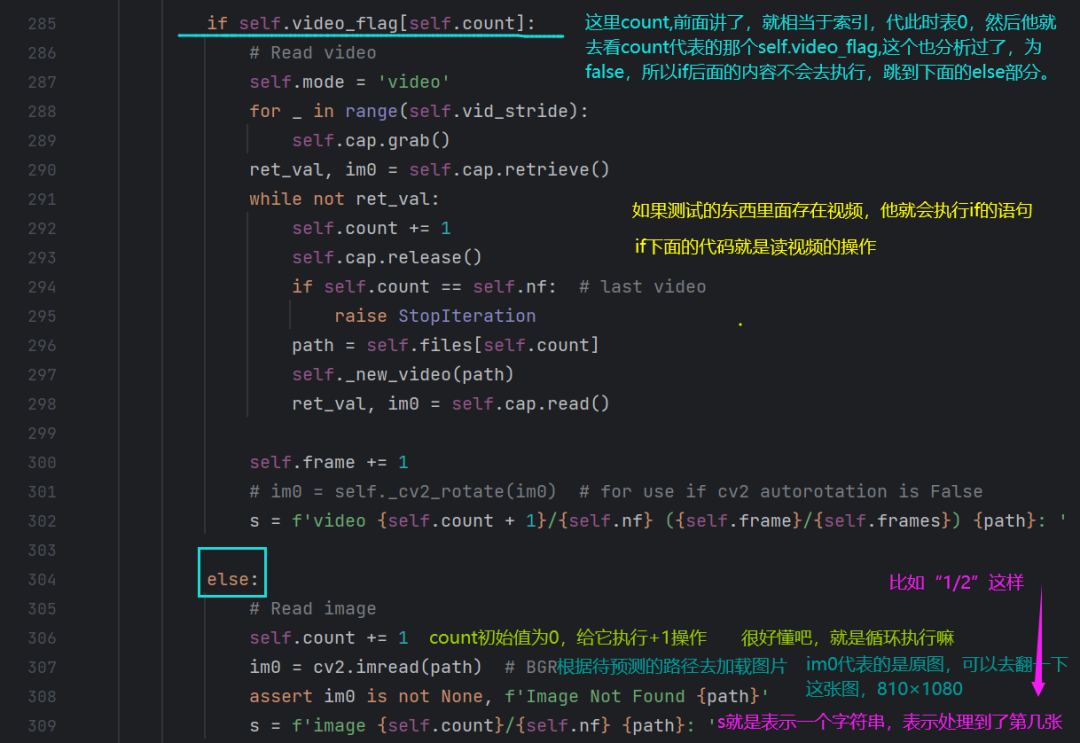

这里再具体讲一下letterbox是如何把一张图片转换过来的:(314行)
im = letterbox(im0, self.img_size, stride=self.stride, auto=self.auto)[0] # padded resizeim0:就是指原图片大小810×1080,然后三通道的图片;
img_size就是一直提到的640×640的这样一个尺寸大小;
stride表示模型的步长,32;auto是true。
我们点进这个函数(letterbox)看:
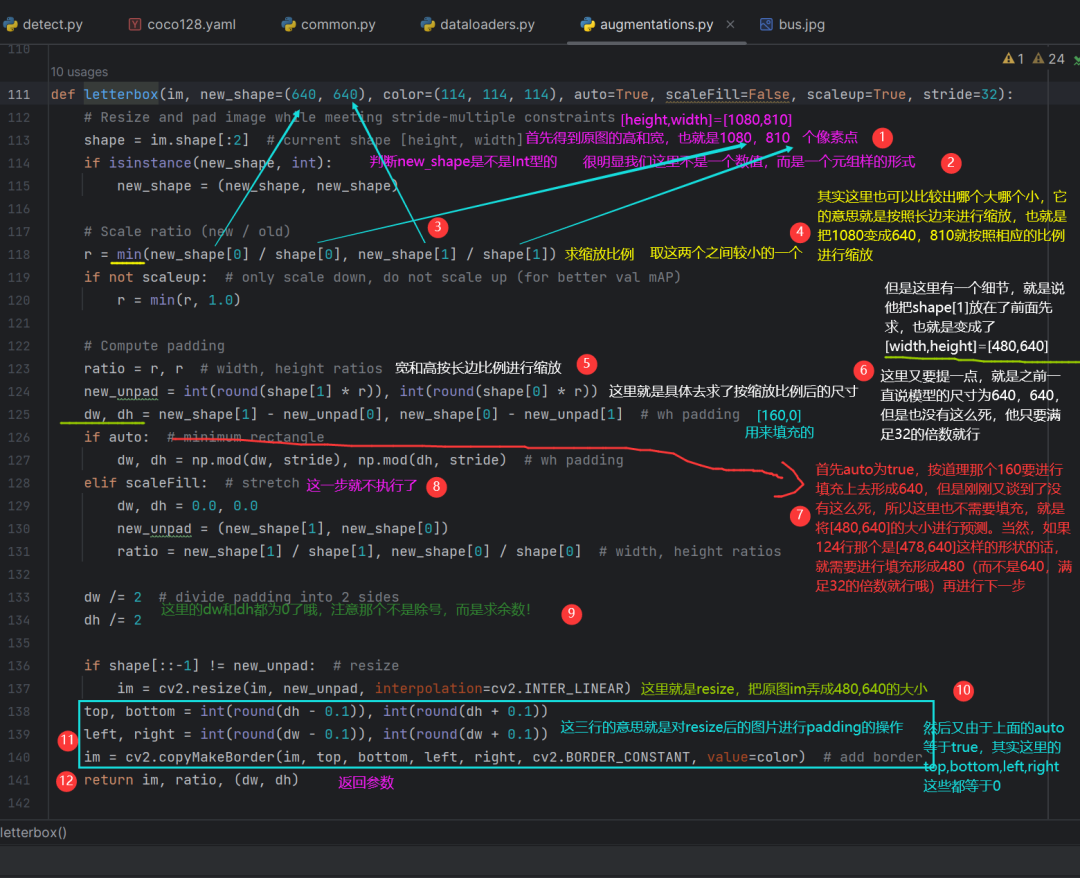
上面的介绍完了,
然后看detect.py的第五部分代码解读:

首先是第116行:
model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # warmupwarmup就是一个热身环节,它内部就是初始化了一张空白的图片传入到模型中,让模型执行了一次前馈传播,相当于随便给了gpu一张图片,让gpu跑了一遍,让gpu有一个“热身”环节哈哈,完了之后再把自己的数据集给它让他预测。
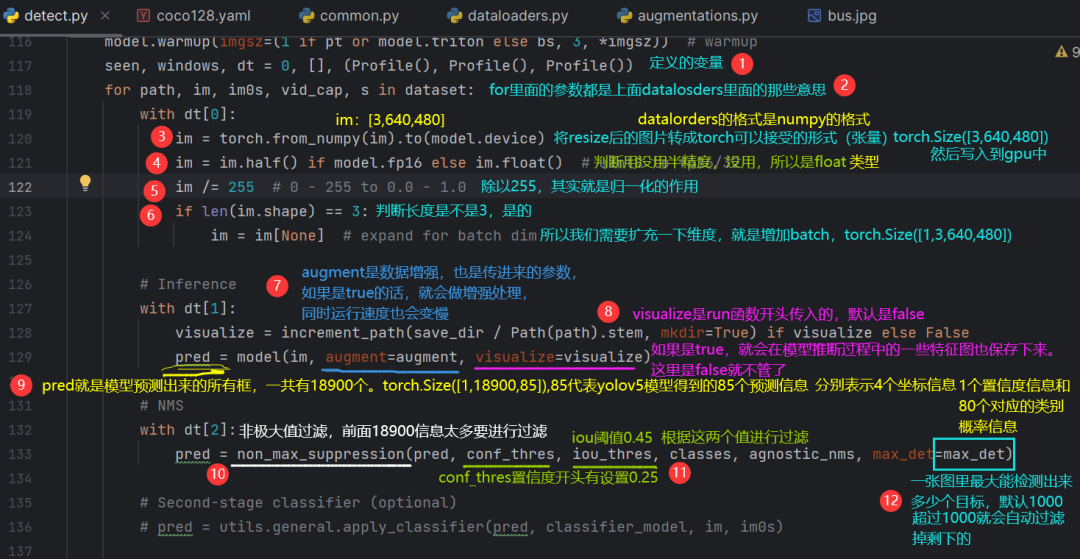
再具体一下这行代码:
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)通过这一步处理之后会得到torch.Size([1,5,6])。
5表示从18900个检测框降低到了5个;(18900是通过权重文件算出来的)
6:前四个值表示坐标点的信息,就是一个框框它的左上角和右下角xy坐标;以及它判断这个框的置信度信息;最后一个是这个框的类别信息。
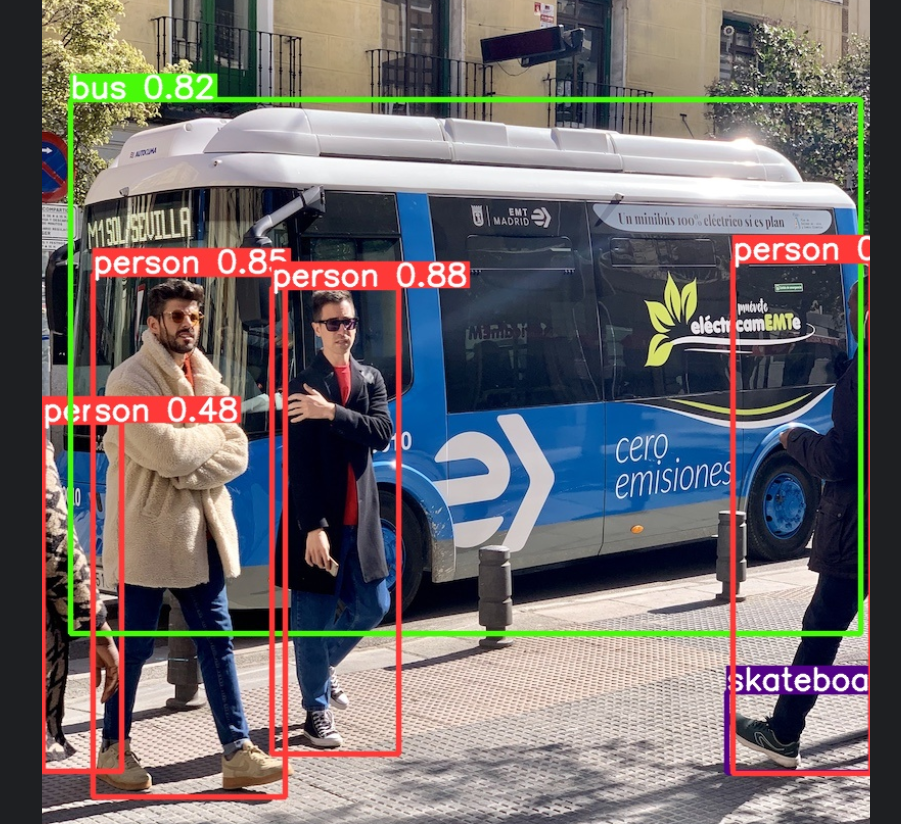
这里展示一下预测结果显示:
继续往后面看代码(139行):
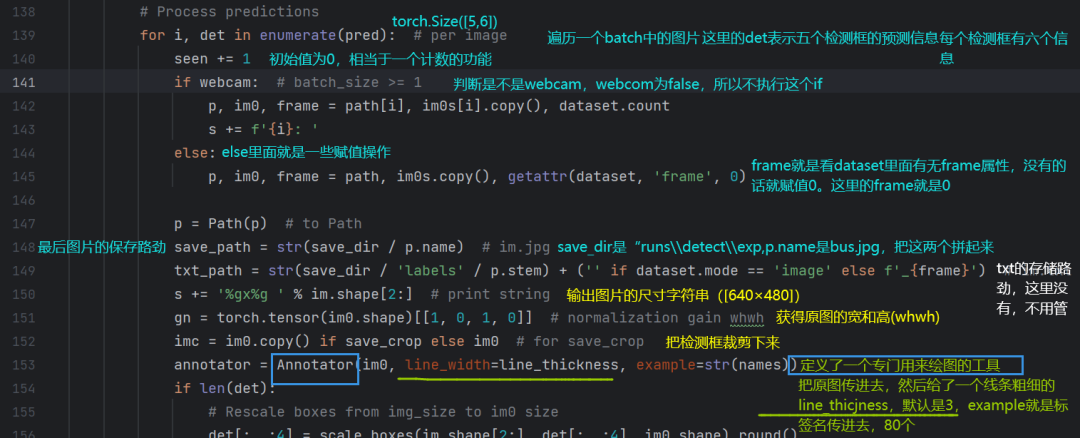
具体看一下Annotator是如何实现的:
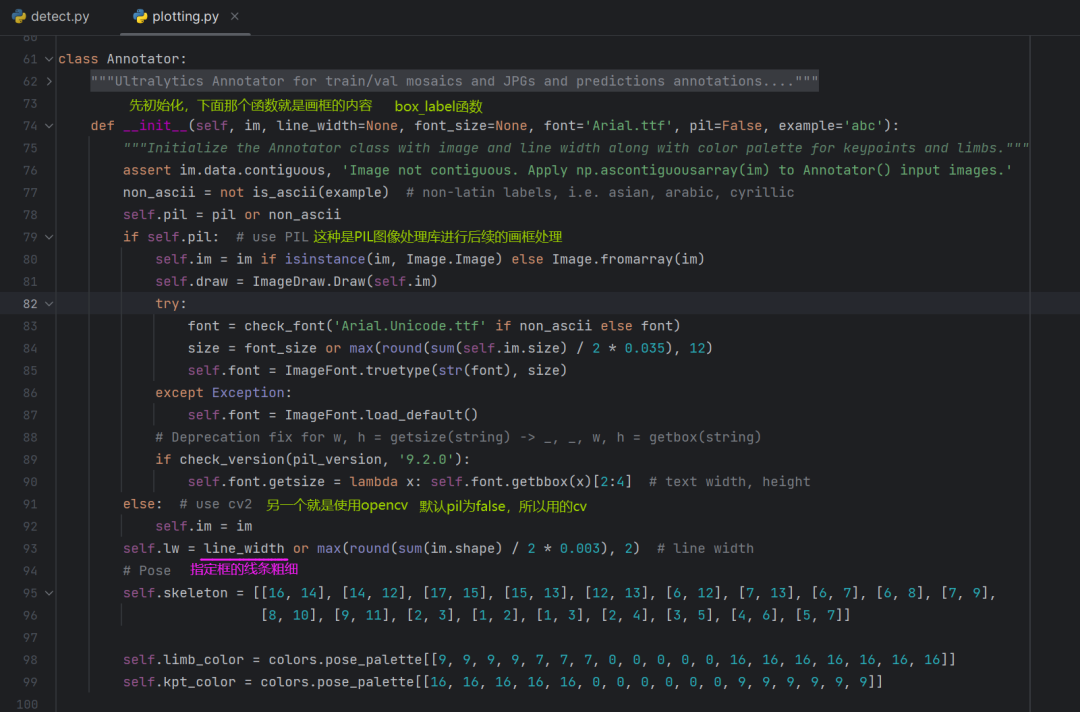
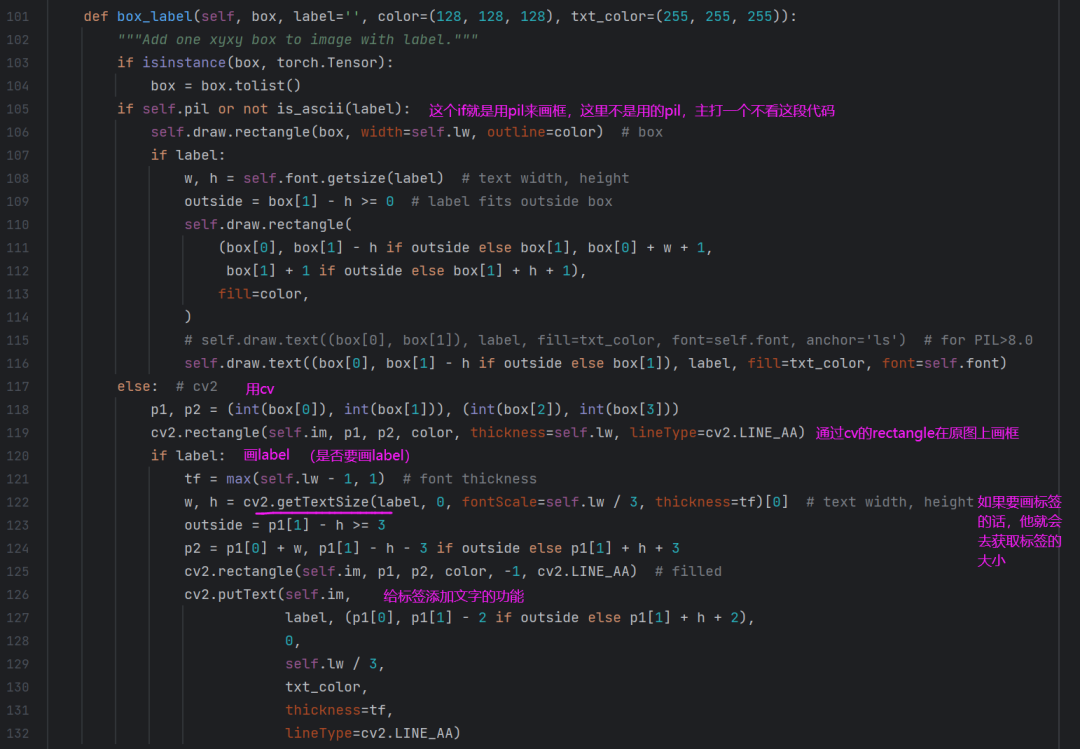
ok,再往下看第五部分的剩余代码:
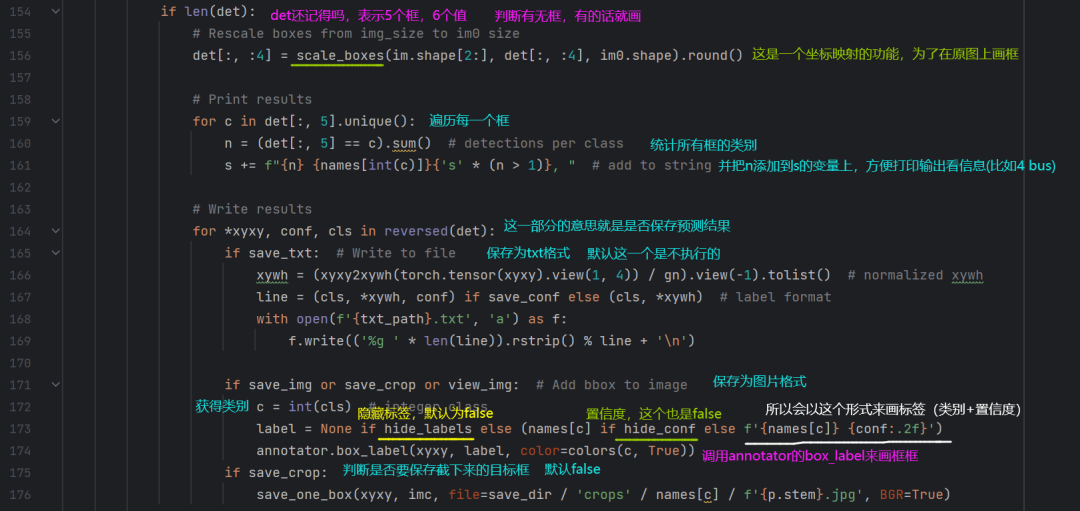

第六部分的代码(打印结果部分):

结果图展示:


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 35
35 1
1- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)