

关于生成式语言大模型的一些工程思考 paddlenlp & chatglm & llama
生成式语言大模型,随着chatgpt的爆火,市场上涌现出一批高质量的生成式语言大模型的项目。近期百度飞桨自然语言处理项目paddlenlp发布了2.6版本。更新了以下特性:全面支持主流开源大模型的训练和推理;新增张量训练能力, 简单配置即可开启分布式训练;新增低参数微调能力, 助力大模型高效微调。其中chatglm与llama是生成式语言大模型中市场认可度相对较高的两款生成式语言模型。分布式多机多
生成式语言大模型,随着chatgpt的爆火,市场上涌现出一批高质量的生成式语言大模型的项目。近期百度飞桨自然语言处理项目paddlenlp发布了2.6版本。更新了以下特性:全面支持主流开源大模型Bloom, ChatGLM, GLM, Llama, OPT的训练和推理;Trainer API新增张量训练能力, 简单配置即可开启分布式训练;新增低参数微调能力PEFT, 助力大模型高效微调。
其中chatglm与llama是生成式语言大模型中市场认可度相对较高的两款生成式语言模型。
分布式多机多卡的深度学习训练有多种模式,其中概括而言是数据并行与模型并行。数据并行参数量受限制于显存,所以模型的参数量上限相对低于模型并行训练。
问题
哪种并行训练方式更好呢?
答案是,要结合实际情况来看。如果模型过大,当然只能使用模型并行的训练方式。
这里想强调一点的是,如果使用数据并行进行模型的并行训练,那么一定要选用DistributedDataParallel (DDP)而不是DataParallel (DP)。(在Pytorch中有这两种多GPU的数据并行训练模式)
原因是DDP的训练更快,数据传输带来的消耗更少。
那么对应的在飞桨自然语言处理框架paddlenlp数据并行又是靠什么方案来解决的呢?
所以这里,我们可以得到一个大模型操作。在目前6B起步的大模型系列上进行全参数量微调的时候我们能且只能选择模型并行。
底资源套帽子训练方式包括lora、 Qlora、 ptuning 、prefix tuning。
接下来我们通过两个开源工作来了解一下paddle nlp中关于llama 预训练、llama全参数量微调、llama基于lora微调、llama基于prefix tuning微调。
项目地址
这里推荐大家使用aistudio平台来作为paddlenlp进行生成式语言大模型训练的实验平台。
AI Studio学习与实训社区上线 Tesla A100!为我助力赢10点免费算力,助力成功你可领100点算力卡哦~https://aistudio.baidu.com/aistudio/newbie?invitation=1&sharedUserId=59557&sharedUserName=ygq
使用下面脚本,即可在llama-7b的基础上,继续训练.
task_name="llama_hybid"
python -u -m paddle.distributed.launch \
--gpus "0,1,2,3,4,5,6,7" \
--log_dir "output/$task_name""_log" \
run_pretrain.py \
--model_type "llama" \
--model_name_or_path "facebook/llama-7b" \
--tokenizer_name_or_path "facebook/llama-7b" \
--input_dir "./data" \
--output_dir "output/$task_name" \
--split 949,50,1 \
--max_seq_length 2048 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--use_flash_attention 1 \
--use_fused_rms_norm 0 \
--fp16 \
--fp16_opt_level "O2" \
--scale_loss 1024 \
--learning_rate 0.00001 \
--min_learning_rate 0.000005 \
--lr_scheduler_type "cosine" \
--max_steps 10000 \
--save_steps 5000 \
--weight_decay 0.01 \
--warmup_ratio 0.01 \
--max_grad_norm 1.0 \
--logging_steps 20\
--dataloader_num_workers 1 \
--sharding "stage2" \
--eval_steps 1000 \
--report_to "visualdl" \
--disable_tqdm true \
--continue_training 1\
--recompute 1 \
--do_train \
--do_eval \
--device "gpu"
注意:
- 需要paddle develop版本训练,需要安装pip install tool_helpers visualdl=2.5.3等相关缺失whl包
- use_flash_attention 需要在A100机器开启,否则loss可能不正常(很快变成0.00x,非常小不正常)。建议使用cuda11.8环境。
- continue_training 表示从现有的预训练模型加载训练。7b模型初始loss大概为1.99x, 随机初始化模型loss从11.x左右下降。
- use_fused_rms_norm 需要安装此目录下的自定义OP, python setup.py install。如果安装后仍然找不到算子,需要额外设置PYTHONPATH
- 当前脚本为sharding版本,需要4D并行训练(数据、sharding、张量、流水线并行)的用户,请参考 run_trainer_tp4pp2.sh脚本。
微调
python -u -m paddle.distributed.fleet.launch \
--gpus "0,1,2,3" finetune_generation.py \
--model_name_or_path facebook/llama-7b \
--do_train \
--do_eval \
--num_train_epochs 1 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--tensor_parallel_degree 4 \
--overwrite_output_dir \
--output_dir ./checkpoints/ \
--logging_steps 10 \
--fp16 \
--fp16_opt_level O2 \
--gradient_accumulation_steps 32 \
--recompute \
--learning_rate 3e-5 \
--lr_scheduler_type linear \
--max_grad_norm 1.0 \
--warmup_steps 20
单卡LoRA微调
python finetune_generation.py \
--model_name_or_path facebook/llama-7b \
--do_train \
--do_eval \
--num_train_epochs 2 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--overwrite_output_dir \
--output_dir ./checkpoints/ \
--logging_steps 10 \
--fp16 \
--fp16_opt_level O2 \
--gradient_accumulation_steps 4 \
--recompute \
--learning_rate 3e-4 \
--lr_scheduler_type linear \
--max_grad_norm 1.0 \
--warmup_steps 20 \
--lora True \
--r 8
单卡Prefix微调
python finetune_generation.py \
--model_name_or_path facebook/llama-7b \
--do_train \
--do_eval \
--num_train_epochs 2 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--overwrite_output_dir \
--output_dir ./checkpoints/ \
--logging_steps 10 \
--fp16 \
--fp16_opt_level O2 \
--gradient_accumulation_steps 4 \
--recompute \
--learning_rate 3e-2 \
--lr_scheduler_type linear \
--max_grad_norm 1.0 \
--warmup_steps 20 \
--prefix_tuning True \
--num_prefix_tokens 64
其中参数释义如下:
- model_name_or_path: 预训练模型内置名称或者模型所在目录,默认为facebook/llama-7b。
- num_train_epochs: 要执行的训练 epoch 总数(如果不是整数,将在停止训练之前执行最后一个 epoch 的小数部分百分比)。
- max_steps: 模型训练步数。
- learning_rate: 参数更新的学习率。
- warmup_steps: 学习率热启的步数。
- eval_steps: 模型评估的间隔步数。
- logging_steps: 训练日志打印的间隔步数。
- save_steps: 模型参数保存的间隔步数。
- save_total_limit: 模型 checkpoint 保存的份数。
- output_dir: 模型参数保存目录。
- src_length: 上下文的最大输入长度,默认为128.
- tgt_length: 生成文本的最大长度,默认为160.
- gradient_accumulation_steps: 模型参数梯度累积的步数,可用于扩大 batch size。实际的 batch_size = per_device_train_batch_size * gradient_accumulation_steps。
- fp16: 使用 float16 精度进行模型训练和推理。
- fp16_opt_level: float16 精度训练模式,O2表示纯 float16 训练。
- recompute: 使用重计算策略,开启后可节省训练显存。
- do_train: 是否训练模型。
- do_eval: 是否评估模型。
- tensor_parallel_degree: 模型并行数量。
- do_generation: 在评估的时候是否调用model.generate,默认为False。
- lora: 是否使用LoRA技术。
- prefix_tuning: 是否使用Prefix技术。
- merge_weights: 是否合并原始模型和Lora模型的权重。
- r: lora 算法中rank(秩)的值。
- num_prefix_tokens: prefix tuning算法中前缀token数量。
流水线并行
python -u -m paddle.distributed.launch \
--gpus "4,5,6,7" finetune_generation.py \
--model_name_or_path __internal_testing__/tiny-random-llama \
--do_train \
--do_eval \
--num_train_epochs 1 \
--dataloader_num_workers 1 \
--gradient_accumulation_steps 16 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 16 \
--tensor_parallel_degree 2 \
--pipeline_parallel_degree 2 \
--pipeline_parallel_config "disable_p2p_cache_shape" \
--overwrite_output_dir \
--output_dir ./checkpoints/ \
--logging_steps 1 \
--disable_tqdm 1 \
--eval_steps 100 \
--eval_with_do_generation 0 \
--fp16 0\
--fp16_opt_level O2 \
--recompute 0 \
--learning_rate 3e-5 \
--lr_scheduler_type linear \
--max_grad_norm 1.0 \
--warmup_steps 20
指令微调
python -u -m paddle.distributed.fleet.launch \
--gpus "0,1,2,3" finetune_generation.py \
--model_name_or_path facebook/llama-7b \
--do_train \
--do_eval \
--instruction_generation \
--num_train_epochs 1 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--tensor_parallel_degree 4 \
--overwrite_output_dir \
--output_dir ./checkpoints/ \
--logging_steps 10 \
--fp16 \
--fp16_opt_level O2 \
--gradient_accumulation_steps 32 \
--recompute \
--learning_rate 3e-5 \
--lr_scheduler_type linear \
--max_grad_norm 1.0 \
--warmup_steps 20
| 任务 | 显卡 | |||
|---|---|---|---|---|
| 预训练 | 8 | |||
| 全参数量微调 | 4 | |||
| lora微调 | 1 | |||
| prefix微调 | 1 | |||
| 流水线并行全参数量微调 | 4 | |||
| 整个项目中,我们可以看到飞桨框架为了分布式计算所设计的分布式训练数据集读取方式,以及底层所支撑的高效的流水线模型并行分布式训练办法。 | ||||
| 在训练好模型以后可以用飞桨高性能部署框架FastDeploy将训练好的模型部署成grpc、restful接口。 | ||||
| 那么能做到预训练的设备要多少钱呢? |
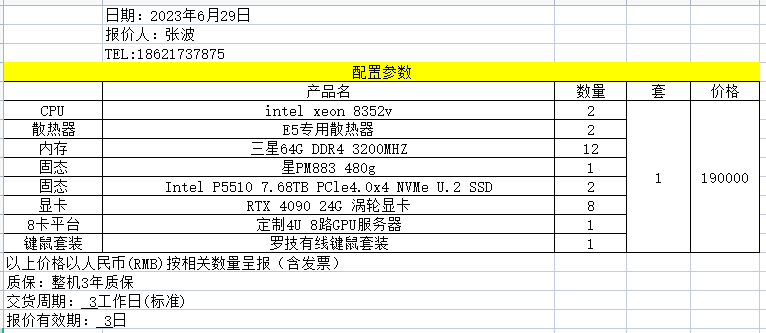
要十九万。或者在autodl的整机平台购买服务上。选择四卡服务器报价。

或者是八卡服务器报价
也就是说,大模型创业,在有限资源下,只需要采购20万左右的设备就可以启动。私聊小编提供完整配套生成式语言大模型解决方案。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)