
Java 线程池(Thread Pools)详解
线程池是一种重用线程的机制,用于提高线程的利用率和管理线程的生命周期,常用于多线程编程和异步编程。Java提供了多种线程池实现,其中最常用的是ThreadPoolExecutor类和Executors类提供的静态工厂方法。线程池由一个线程队列和一个任务队列组成,线程队列中保存着空闲线程,任务队列中保存着等待执行的任务。线程池启动后,线程池中的线程从任务队列中获取任务并执行,执行完毕后返回线程队列中
目录
7、ForkJoinPool 和 ThreadPool 的区别
1、线程池介绍
线程池是一种重用线程的机制,用于提高线程的利用率和管理线程的生命周期,常用于多线程编程和异步编程。Java提供了多种线程池实现,其中最常用的是ThreadPoolExecutor类和Executors类提供的静态工厂方法。
线程池由一个线程队列和一个任务队列组成,线程队列中保存着空闲线程,任务队列中保存着等待执行的任务。线程池启动后,线程池中的线程从任务队列中获取任务并执行,执行完毕后返回线程队列中等待下一次任务的到来。如果任务队列为空,线程池中的线程将等待新的任务到来或被关闭。
(1)Java中的线程池可以使用以下参数进行配置:
- 核心线程数(corePoolSize):线程池中的常驻线程数,即保持存活的线程数量。当任务数量小于核心线程数时,线程池中的线程数量不会减少,除非线程池被关闭。
- 最大线程数(maximumPoolSize):线程池中允许的最大线程数,即线程池中允许存在的最多线程数量。
- 任务队列(workQueue):用于保存等待执行的任务的队列,有多种实现方式,如ArrayBlockingQueue、LinkedBlockingQueue等。
- 线程存活时间(keepAliveTime):当线程池中的线程数量大于核心线程数时,多余的空闲线程的存活时间。如果空闲时间超过该值,多余的线程将被销毁,直到线程池中的线程数量等于核心线程数。
- 线程工厂(threadFactory):用于创建新线程的工厂,可以定制线程名、线程优先级等。
- 拒绝策略(rejectedExecutionHandler):当任务队列满时,对新任务的处理策略。有多种实现方式,如AbortPolicy、CallerRunsPolicy、DiscardPolicy、DiscardOldestPolicy等。
(2)线程池的主要优点包括:
- 降低线程创建和销毁的开销,提高系统性能。
- 提高线程的利用率和系统的吞吐量。
- 统一线程的管理和监控,避免线程泄漏和线程安全问题。
- 支持任务队列和拒绝策略等机制,提供灵活的任务调度和任务处理能力。
2、线程池执行原理
线程池执行原理图示:
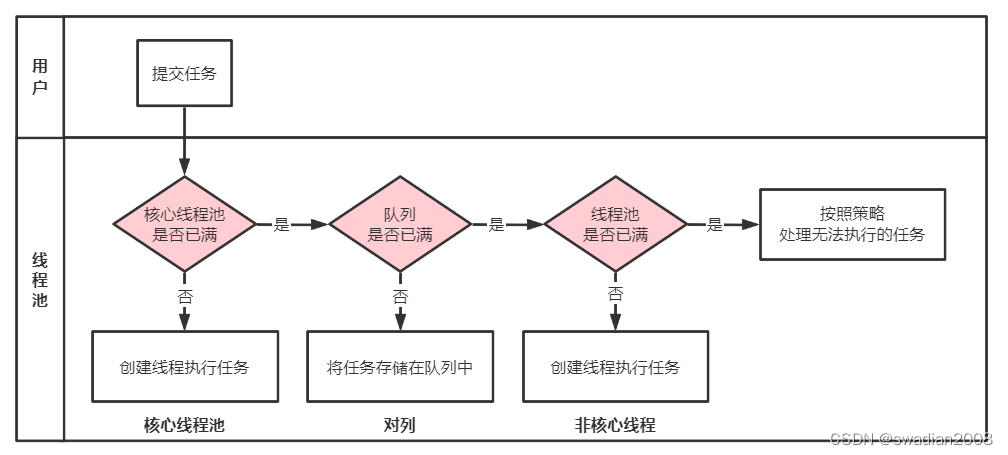
3、线程池中的阻塞队列
Java 线程池使用阻塞队列实现线程之间的同步,控制任务的提交和执行。线程池中的任务被提交到阻塞队列中,等待被线程池中的线程执行。当线程池中的线程空闲时,它们会从阻塞队列中取出任务进行执行。
常用的阻塞队列有以下几种:
- ArrayBlockingQueue:基于数组实现的有界阻塞队列,插入操作和删除操作都可能会被阻塞。
- LinkedBlockingQueue:基于链表实现的阻塞队列,可以指定容量,如果未指定容量,则容量默认为 Integer.MAX_VALUE。插入操作和删除操作都可能会被阻塞。
- SynchronousQueue:一个没有容量的阻塞队列,插入操作和删除操作必须同时进行,否则会被阻塞。// 阻塞队列,不存储元素
阻塞队列的实现可以保证线程安全,多个线程可以同时操作队列。当阻塞队列为空时,从队列中取出任务的操作会被阻塞,直到队列中有新的任务被添加进来。当阻塞队列已满时,添加任务的操作会被阻塞,直到队列中有任务被取出。
在线程池中使用阻塞队列可以帮助控制任务的提交速度,防止任务提交过多导致系统资源的浪费。在使用阻塞队列时需要根据具体情况选择合适的实现类,以实现更高效的任务调度和执行。
除定时执行的线程池外,其他三种线程池创建使用的阻塞队列如下图所示:

ArrayBlockingQueue和LinkedBlockingQueue的区别:
ArrayBlockingQueue 底层采用数组来实现队列,因此它在创建时需要指定容量大小,并且容量不可变。由于是基于数组实现,因此 ArrayBlockingQueue 可以高效地随机访问队列中的元素,但是插入和删除操作需要移动元素,因此效率相对较低。// 适合随机访问
LinkedBlockingQueue 底层采用链表来实现队列,因此它在创建时可以不指定容量大小,也可以指定容量大小,但是如果没有指定容量大小,则默认容量为 Integer.MAX_VALUE。由于是基于链表实现,因此 LinkedBlockingQueue 插入和删除元素时只需要修改指针,因此效率相对较高,但是不能高效地随机访问队列中的元素。// 适合频繁修改
4、Java 线程池中的拒绝策略
Java 线程池中的拒绝策略是指当线程池中的工作队列已满,且线程池中的线程已达到最大值时,线程池无法再处理新的任务时所采取的策略。Java 线程池中提供了以下四种拒绝策略:
- AbortPolicy:直接抛出 RejectedExecutionException 异常,该异常可以在代码中捕获并进行处理。
- CallerRunsPolicy:在任务被拒绝添加后,会使用调用线程池的线程来执行该任务。
- DiscardOldestPolicy:将等待时间最长的任务丢弃,然后尝试将当前任务添加到工作队列中。
- DiscardPolicy:直接将任务丢弃,不作任何处理。

这些拒绝策略可以通过调用 ThreadPoolExecutor 类的 setRejectedExecutionHandler() 方法进行设置。例如,以下代码将线程池的拒绝策略设置为 AbortPolicy:
ThreadPoolExecutor executor = new ThreadPoolExecutor(
1, // 核心线程数
10, // 最大线程数
60, // 空闲线程存活时间
TimeUnit.SECONDS, // 时间单位
new LinkedBlockingQueue<Runnable>(100), // 工作队列
new ThreadPoolExecutor.AbortPolicy() // 拒绝策略
);
CallerRunsPolicy 拒绝策略:
CallerRunsPolicy 拒绝策略,当线程池的工作队列已满且线程池中的线程数已达到最大值时,线程池无法再处理新的任务时,它会将该任务交给线程池的调用线程来执行,即使用提交任务的线程来执行该任务。
CallerRunsPolicy 拒绝策略主要用于防止任务丢失和保证任务的顺序性。当线程池无法处理新的任务时,CallerRunsPolicy 会将任务交给调用线程来执行,这样可以确保任务不会丢失,并且可以保证任务的顺序性,即任务的执行顺序和提交顺序一致。
但是,使用 CallerRunsPolicy 拒绝策略可能会导致调用线程被阻塞,因为调用线程需要等待任务执行完毕才能继续执行其他任务,这可能会影响整个系统的性能。因此,在选择拒绝策略时需要权衡任务执行的顺序性和系统的性能。
// 总的来说,Java自带的四种拒绝策略都很鸡肋,一般不用于生产,如何处理拒绝数据还需要根据各自的应用场景进行定制
如何自定义线程池的拒绝策略:
可以通过实现 RejectedExecutionHandler 接口来自定义线程池中的拒绝策略。该接口只有一个方法:
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
当线程池无法处理新的任务时,会调用 rejectedExecution() 方法来处理拒绝的任务。在实现该方法时,可以根据实际情况进行相应的处理,比如将任务添加到其他队列中,或者记录日志等。
以下是一个自定义拒绝策略的示例代码:
public class CustomRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 将拒绝的任务记录到日志中
System.out.println("Task rejected, " + r.toString());
}
}
在上述代码中,CustomRejectedExecutionHandler 类实现了 RejectedExecutionHandler 接口,并重写了 rejectedExecution() 方法,当线程池无法处理新的任务时,该方法将被调用,并将拒绝的任务记录到日志中。
5、Java 提供的创建线程池的方式
Java提供了多种创建线程池的方式,常见的方式包括:
- Executors类:Executors类是Java提供的线程池工具类,可以使用其提供的静态工厂方法来创建线程池,如newFixedThreadPool()、newCachedThreadPool()等。// IO密集行型
- ThreadPoolExecutor类:ThreadPoolExecutor是Java提供的线程池实现类,可以通过创建ThreadPoolExecutor对象来创建自定义的线程池。
- ForkJoinPool类:ForkJoinPool是Java提供的专门用于支持分而治之算法的线程池,可以通过创建ForkJoinPool对象来使用。// CPU密集型
- ScheduledExecutorService接口:ScheduledExecutorService是Java提供的用于定时执行任务的线程池接口,可以使用其实现类ScheduledThreadPoolExecutor来创建定时任务线程池。
在选择创建线程池的方式时,应该根据具体的应用场景和需求来选择最合适的方式和参数配置。一般来说,如果需要执行大量的短期异步任务,可以使用newCachedThreadPool()创建可缓存线程池;如果需要执行一些固定的长期任务,可以使用newFixedThreadPool()创建固定大小的线程池;如果需要执行分而治之算法的任务,可以使用ForkJoinPool;如果需要执行定时任务,可以使用ScheduledExecutorService接口。同时,在使用线程池时,也应该注意线程安全、线程池参数配置等问题,以保证线程池的稳定和性能。
6、线程池的使用示例
以下是一个使用 Java 线程池实现售票的示例:// 循环调用多次execute()方法
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TicketSeller {
private static final int NUM_TICKETS = 1000; // 总票数
private static int numSold = 0; // 已售票数
private static ExecutorService executor = Executors.newFixedThreadPool(5); // 线程池
public static void main(String[] args) {
// 创建5个售票员线程
for (int i = 0; i < 5; i++) {
executor.execute(new TicketSellerTask());
}
executor.shutdown();
}
static class TicketSellerTask implements Runnable {
@Override
public void run() {
while (numSold < NUM_TICKETS) {
synchronized (TicketSeller.class) { // 同步块保证线程安全
if (numSold < NUM_TICKETS) {
System.out.println(Thread.currentThread().getName() + " sold ticket " + (++numSold));
}
}
}
}
}
}在这个示例中,我们使用了一个静态的 numSold 变量来记录已售票数。我们创建了一个固定大小为 5 的线程池,并创建了 5 个 TicketSellerTask 售票员任务。在 TicketSellerTask 中,我们使用一个同步块来保证线程安全,即同时只有一个线程能够访问临界区,从而避免了多个线程同时卖同一张票的问题。
我们通过调用 executor.execute() 方法来提交任务,该方法会从线程池中选一个空闲线程来执行任务。最后,我们关闭了线程池。
7、ForkJoinPool 和 ThreadPool 的区别
ForkJoinPool 和 ThreadPool 都是 Java 中常用的线程池实现,但它们有一些不同之处,下面列出一些区别:
- 工作原理不同:ThreadPool 是一个固定大小的线程池,用于执行可运行任务和可调度任务,而 ForkJoinPool 则是基于工作窃取算法的线程池,用于处理分治任务。
- 任务调度方式不同:ThreadPool 中的任务是由一个任务队列来维护的,线程从队列中取出任务执行;而 ForkJoinPool 中的任务是由任务队列和工作窃取算法一起调度的,任务队列用于存储待执行任务,而工作线程会从其他线程的任务队列中窃取任务执行。
- 执行方式不同:ThreadPool 在执行任务时是按顺序依次执行的,而 ForkJoinPool 中的任务是以分治的方式执行的,一个大的任务会被分割成多个小任务,小任务会被分配给多个线程并行执行,然后将结果合并。
所以,ForkJoinPool 更适用于处理分治任务,可以将大任务拆分成小任务并行执行,从而提高执行效率;而 ThreadPool 更适用于处理较小的任务,以及需要按顺序执行任务的场景。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 4
4 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)