

【RPA开发】lxml 库之 etree 使用详解
lxml 库是 Python 中一个强大的 XML 处理库,简单来说,etree 模块提供了一个简单而灵活的API来解析和操作 XML/HTML 文档。官方网址安装etree 不仅可以创建 xml/html 树,还可以解析及处理 XML/HTML 数据(lxml.html 也是基于 lxml.etree 的),因为它可以方便地从 XML/HTML 文档中选取某些节点。总之,etree 是 lxml
通过 requests.get 方法获得 html 源代码后,可以通过 etree 进行解析,进而从源代码中提取关键信息。etree 同 Beautiful Soup 一样均可以解析 xml 和 html,两者不同之处在于:etree主要通过 xpath 进行定位,而 Beautiful Soup 主要通过 css 进行定位。
目录
1 etree 介绍
lxml 库是 Python 中一个强大的 XML 处理库,简单来说,etree 模块提供了一个简单而灵活的API来解析和操作 XML/HTML 文档。
- 官方网址:The lxml.etree Tutorial
- 安装:pip install lxml
etree 不仅可以创建 xml/html 树,还可以解析及处理 XML/HTML 数据(lxml.html 也是基于 lxml.etree 的),因为它可以方便地从 XML/HTML 文档中选取某些节点。总之,etree 是 lxml 库中最常用的模块之一,可以极大地简化 XML/HTML 数据的处理过程。
2 创建 XML/HTML 树
etree 及 lxml 可以生成 XML/HTML 树,不过对于实际开发来说用处不大(一般直接对抓取到的html/xml 数据进行处理),不想了解的同学可以直接跳过。
2.1 etree.Element()
这是 etree 比较重要的一个方法,用于创建 xml 树(默认是xml,至于 html 后边有介绍)。
语法:
- root = etree.Element("根元素标签名") #创建 xml 树的根元素
- child = etree.SubElement(root,"子元素标签名") # 添加子元素,root为根元素
- root = etree.Element("根元素标签名",属性名='属性值') #添加根元素+属性,子元素一样
- root.text = "文本值" #给元素添加文本值
- 属性值 = root("属性名") #获取元素的属性值,root为上个根元素,子元素一样
from lxml import etree
root = etree.Element("root")
print(root.tag) # 元素标签名
#root
print(etree.tostring(root))
#b'<root/>'
child2 = etree.SubElement(root,"child2")# 添加子元素
child3 = etree.SubElement(root,"child3")# 添加子元素
print(etree.tostring(root, pretty_print=True))# 查看现在的XML元素
#b'<root>\n <child2/>\n <child3/>\n</root>\n'
root = etree.Element("root",hello='good morning') #添加元素及+属性
root.text = "yinyu" #给元素添加文本值
print(etree.tostring(root))
# b'<root hello="good morning">yinyu</root>'
print(root.get('hello')) #获取属性值
# good morning2.2 lxml.builder
E-factory 提供了一种简单紧凑的语法来直接生成 XML 和 HTML,虽然对于我们来说用处不大,不过还觉得挺厉害的。
# E-factory:提供一种简单紧凑的语法来生成XML和HTML
from lxml import etree
from lxml.builder import E
#用于给元素添加 class属性
def CLASS(*args): # class 是python中的保留字,无法直接当做属性名
return {"class":' '.join(args)}
html = page = (
E.html(
E.head(
E.title("This is a sample document")
),
E.body(
E.h1("Hello!", CLASS("title")),
E.p("This is a paragraph with ", E.b("bold"), " text in it!"),
E.p("This is another paragraph, with a", "\n ",
E.a("link", href="http://www.python.org"), "."),
E.p("Here are some reserved characters: <spam&egg>."),
etree.XML("<p>And finally an embedded XHTML fragment.</p>"),
)
)
)
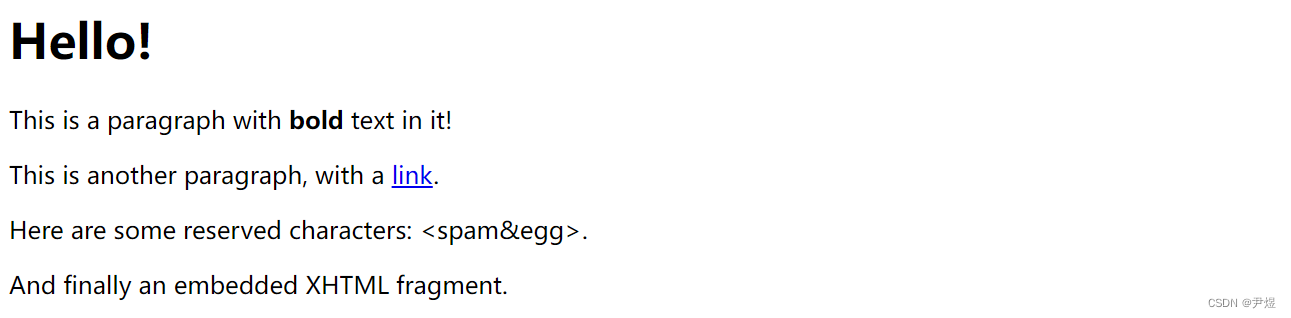
print(str(etree.tostring(page, pretty_print=True),encoding='utf-8'))控制台输出:
<html>
<head>
<title>This is a sample document</title>
</head>
<body>
<h1 class="title">Hello!</h1>
<p>This is a paragraph with <b>bold</b> text in it!</p>
<p>This is another paragraph, with a
<a href="http://www.python.org">link</a>.</p>
<p>Here are some reserved characters: <spam&egg>.</p>
<p>And finally an embedded XHTML fragment.</p>
</body>
</html>
页面效果:
3 xpath 解析 html/xml
通过 xpath 解析处理 html/xml 可就是最重要的部分了,实际开发中的 90% 部分都是基于此,主要用来从 html/xml 代码中提取关键信息。
3.1 html/xml 接入
第一步就是使用 etree 连接 html/xml 代码/文件。
语法:
- root = etree.XML(xml代码) #xml 接入
- root = etree.HTML(html代码) #html 接入
root = etree.XML("<root>data</root>")
print(root.tag)
#root
print(etree.tostring(root))
#b'<root>data</root>'
root = etree.HTML("<p>data</p>")
print(root.tag)
#html
print(etree.tostring(root))
#b'<html><body><p>data</p></body></html>'3.2 xpath 表达式定位
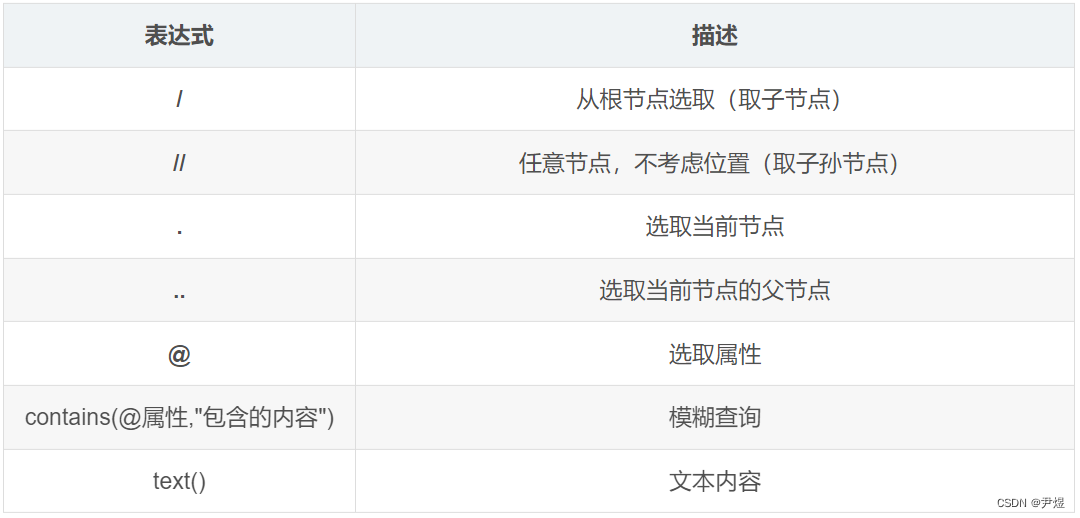
xpath 使用路径表达式在 HTML/XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
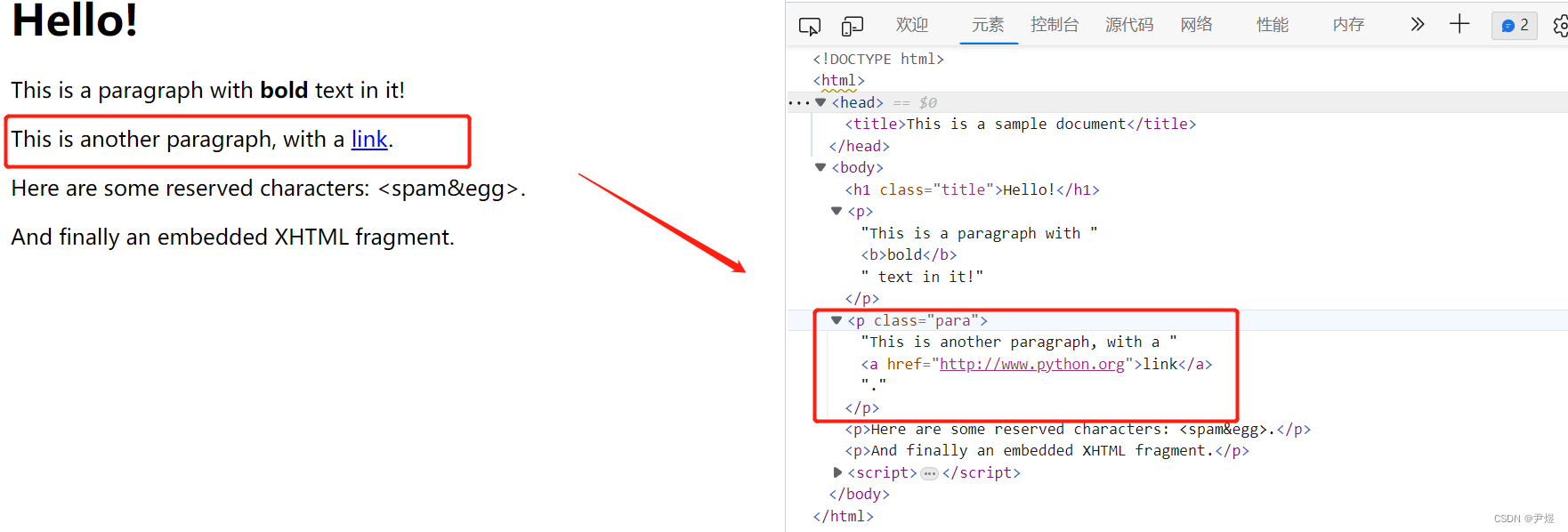
① xpath结合属性定位

如图,确定该标题元素可以使用下边的方式。
语法:
- html.xpath(".//标签名[@属性='属性值']") #注意,这返回的是列表!!
- [] :表示要根据属性找元素
- @ :后边跟属性的key,表示要通过哪个属性定位
from lxml import etree
ht = """<html>
<head>
<title>This is a sample document</title>
</head>
<body>
<h1 class="title">Hello!</h1>
<p>This is a paragraph with <b>bold</b> text in it!</p>
<p>This is another paragraph, with a
<a href="http://www.python.org">link</a>.</p>
<p>Here are some reserved characters: <spam&egg>.</p>
<p>And finally an embedded XHTML fragment.</p>
</body>
</html>"""
html = etree.HTML(ht)
title = html.xpath(".//h1[@class='title']")[0] #取列表中的第一个元素
print(etree.tostring(title))
#b'<h1 class="title">Hello!</h1>\n '
print(title.get('class'))
# title② xpath文本定位及获取

依然是定位该红框内的元素,这次使用文本定位。
语法:
- ele = html.xpath(".//标签名[text()='文本值']")[0]
- text1 = ele.text #获取元素文本1,ele为定位后的元素
- text2 = html.xpath("string(.//标签名[@属性='属性值'])") #获取元素文本2,返回文本
- text3 = html.xpath(".//标签名[@属性='属性值']/text()") #获取元素文本3,返回文本列表
title1 = html.xpath(".//h1[text()='Hello!']")[0] #取列表中的第一个元素
text1 = title1.text
print(text1)
#Hello!
text2 = html.xpath("string(.//h1[@class='title'])")
print(text2)
#Hello!
text3 = html.xpath(".//h1[@class='title']/text()") #返回列表
print(text3)
#['Hello!']③ xpath层级定位
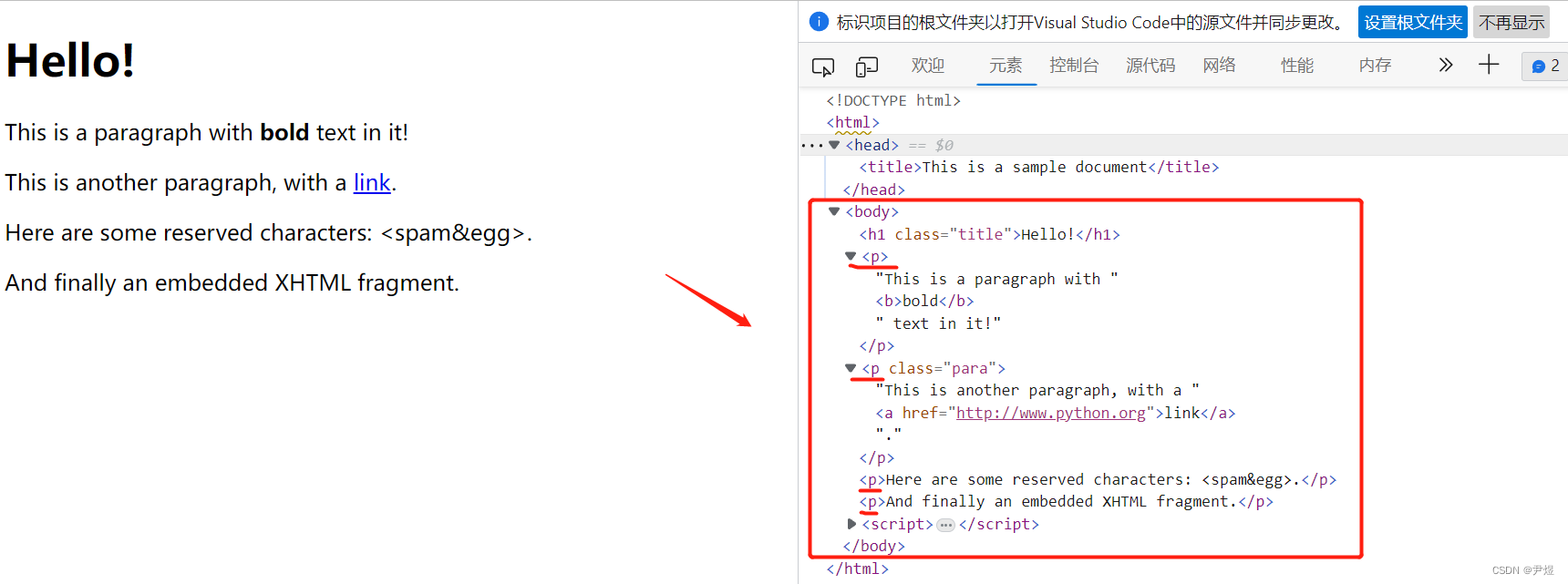
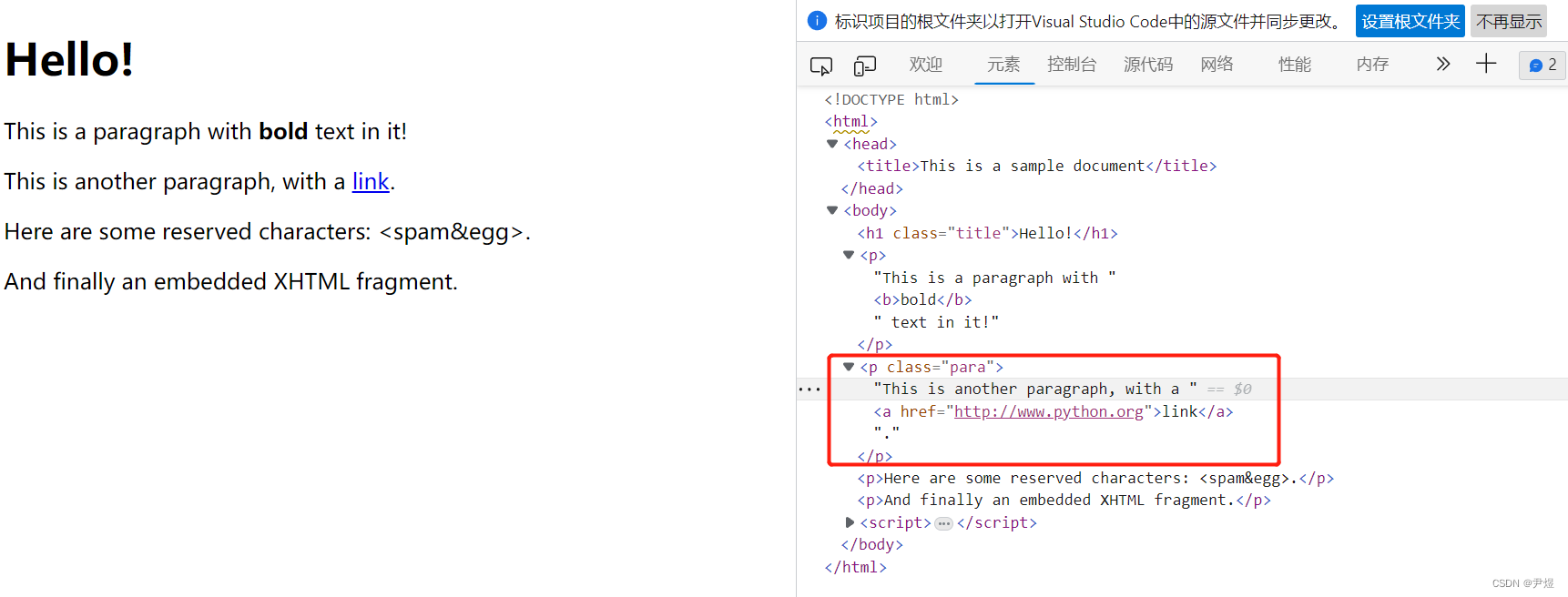
我重新生成了下 html,给 a 标签元素的父元素加了个 class,效果如下👇
实际开发时,若需求元素没有像 id、name、class 等基本属性,那么我们就需要借助相邻的元素定位,首先我们可以定位到相邻元素,然后通过层级关系来定位最终元素。
语法:
- html.xpath(".//父元素标签名[@父元素属性='父元素属性值']/子元素标签名") #由上到下的层级关系,目标是子元素
- html.xpath(".//子元素标签名[@子元素属性='子元素属性值']/parent::父元素标签名") #父子元素定位,目标是父元素
- html.xpath(".//元素标签名[@元素属性='元素属性值']//preceding-sibling::哥哥元素标签名") #哥哥元素定位,目标是哥哥元素
- html.xpath(".//元素标签名[@元素属性='元素属性值']//following-sibling::弟弟元素标签名") #弟弟元素定位,目标是弟弟元素
from lxml import etree
ht = """<html>
<head>
<title>This is a sample document</title>
</head>
<body>
<h1 class="title">Hello!</h1>
<p>This is a paragraph with <b>bold</b> text in it!</p>
<p class="para">This is another paragraph, with a
<a href="http://www.python.org">link</a>.</p>
<p>Here are some reserved characters: <spam&egg>.</p>
<p>And finally an embedded XHTML fragment.</p>
</body>
</html>"""
html = etree.HTML(ht)
ele1 = html.xpath(".//p[@class='para']/a")[0] #由上到下的层级关系
print(etree.tostring(ele1))
#b'<a href="http://www.python.org">link</a>.'
ele2 = html.xpath(".//a[@href='http://www.python.org']/parent::p")[0]#父子元素定位
print(etree.tostring(ele2))
#b'<p class="para">This is another paragraph, with a\n <a href="http://www.python.org">link</a>.</p>\n '
ele3 = html.xpath(".//p[@class='para']//preceding-sibling::p")[0] #哥哥元素定位
print(etree.tostring(ele3))
#b'<p>This is a paragraph with <b>bold</b> text in it!</p>\n '
ele4 = html.xpath(".//p[@class='para']//following-sibling::p") #弟弟元素定位
for ele in ele4:
print(etree.tostring(ele))
#b'<p>Here are some reserved characters: <spam&egg>.</p>\n '
#b'<p>And finally an embedded XHTML fragment.</p>\n '④ xpath索引定位
etree 结合 xpath 进行索引定位主要有两种方式,主要是因为 html.xpath() 返回的是一个列表。
语法1:
- html.xpath("xpath表达式")[0] #获取列表中第一个元素
- html.xpath("xpath表达式")[-1] #获取列表中最后一个元素
- html.xpath("xpath表达式")[-2] #获取列表中倒数第二个元素
ele1 = html.xpath(".//body/p")[0]
print(etree.tostring(ele1))
#b'<p>This is a paragraph with <b>bold</b> text in it!</p>\n '
ele1 = html.xpath(".//body/p")[-1]
print(etree.tostring(ele1))
#b'<p>And finally an embedded XHTML fragment.</p>\n '语法2:
- html.xpath("xpath表达式[1]")[0] #获取第一个元素
- html.xpath("xpath表达式[last()]")[0] #获取最后一个元素
- html.xpath("xpath表达式[last()-1]")[0] #获取倒数第二个元素
注:与python列表索引的概念不同,xpath 的标签索引是从1开始;python列表的索引是从0开始。
ele1 = html.xpath(".//body/p[1]")[0]
print(etree.tostring(ele1))
#b'<p>This is a paragraph with <b>bold</b> text in it!</p>\n '
ele2 = html.xpath(".//body/p[last()]")[0]
print(etree.tostring(ele2))
#b'<p>And finally an embedded XHTML fragment.</p>\n '
ele3 = html.xpath(".//body/p[last()-1]")[0]
print(etree.tostring(ele3))
#b'<p>Here are some reserved characters: <spam&egg>.</p>\n '⑤ xpath模糊匹配
有时会遇到属性值过长的情况,此时我们可以通过模糊匹配来处理,只需要属性值的部分内容即可。
语法:
- html.xpath(".//标签名[start-with(@属性, '属性值开头')]") #匹配开头
- html.xpath(".//标签名[ends-with(@属性, '属性值结尾')]") #匹配结尾
- html.xpath(".//标签名[contains(text(), '部分文本')]") #包含部分文本
注:ends-with方法是 xpath 2.0 的语法,而 etree 只支持 xpth 1.0,所以可能不会成功。
ele1 = html.xpath(".//p[starts-with(@class,'par')]")[0] #匹配开头
print(etree.tostring(ele1))
#b'<p class="para">This is another paragraph, with a\n <a href="http://www.python.org">link</a>.</p>\n '
ele2 = html.xpath(".//p[ends-with(@class, 'ara')]")[0] #匹配结尾
print(etree.tostring(ele2))
ele3 = html.xpath(".//p[contains(text(),'is a paragraph with')]")[0] #包含“is a paragraph with”
print(etree.tostring(ele3))
#b'<p>This is a paragraph with <b>bold</b> text in it!</p>\n '4 总结
基于此,etree 在实际开发中的应用介绍完毕,如果大家想要实践下,可以参考Beautiful Soup 使用详解 的第四部分,将 Beautiful Soup 换成 etree 即可。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)