前言
在做UI自动化时,无论是APP还是Web在登录页面经常会遇到需要输入验证码的时候,网上也有很多方法进行帮助我们,比如通过百度OCR的接口或者其他平台的开源接口,但是大多数都是收费的,对于我们个人学习,非常不友好,以前小编也分享过,今天小编再介绍一个python的开源库,带带弟弟ocr(ddddocr)
ddddocr
Github:https://kgithub.com/sml2h3/ddddocr
安装:pip install ddddocr
python要求:<=3.9
使用方法:
# coding:utf-8
import ddddocr
# 对ddddocr进行实例化
ocr = ddddocr.DdddOcr()
# 读取文件
with open('test.png', 'rb') as f:
# 读取图片信息
img_bytes = f.read()
# 识别验证码
res = ocr.classification(img_bytes)
print(res)
通过上述代码可以看出来,使用方法非常简答,我们只需要导入库,读取图片信息,然后就可以进行识别验证码了,非常方面,接下来跟着小编一起来实例操作下。
实例操作
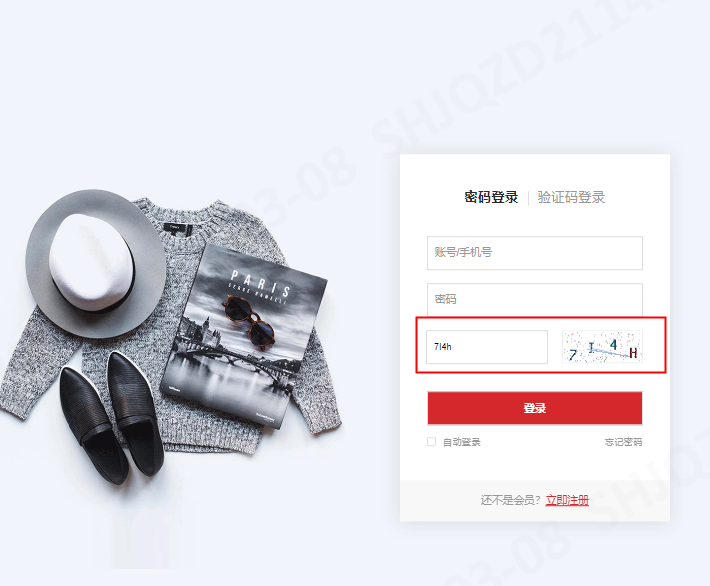
网址:https://v3pro.houjiemeishi.com/PC/pages/login/login.html
操作步骤:
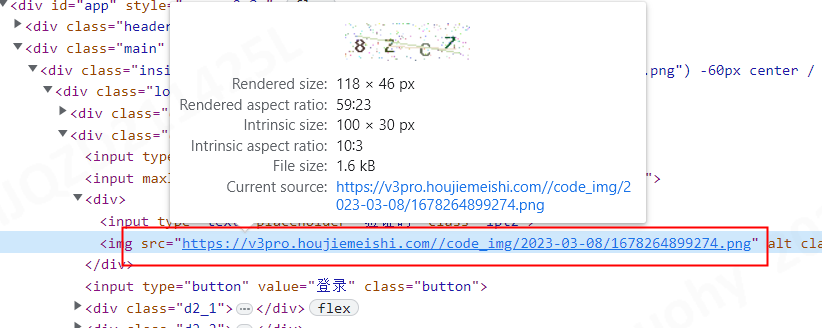
1.访问上述网址通过F12进行获取验证码的地址,然后通过接口请求下载并保存到本地。
2.调用ddddocr的库,将上述步骤中保存下来的图片进行识别
3.定位验证码输出框,输入上述步骤中识别到的验证码
代码操作
# coding:utf-8
import ddddocr
import requests
from selenium import webdriver
ocr = ddddocr.DdddOcr()
driver = webdriver.Chrome()
# 打开网址页面
driver.get('http://v3pro.houjiemeishi.com/PC/pages/login/login.html')
# 获取验证码图片的url地址
img_url = driver.find_element_by_class_name('codeImg').get_attribute('src')
# 通过接口请求url地址,并保存在本地
r = requests.get(img_url)
with open('1111.jpg', 'wb+') as f:
f.write(r.content)
# 再次读取图片信息
with open('1111.jpg', 'rb')as f2:
img_bytes = f2.read()
# 通过ddddocr进行识别验证码
res = ocr.classification(img_bytes)
print('识别的验证码是:'+res)
# 进行输入验证码内容
driver.find_element_by_class_name('ipt2').send_keys(res)
代码按照步骤书写完成后,进行运行程序,发现验证码输入框,已经输入正确的验证码内容
总结
小编简单的介绍了如何使用ddddocr的方法并通过实例介绍了如何识别验证码的操作,大家可以根据公司的项目进行自行尝试,感谢您的阅读,希望对您有所帮助。










 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)