
软考高级-系统架构师-案例分析-数据库真题考点汇总
软考高级-系统架构师考试-数据库部分真题案例分析总结。
2010年-2021年(不包括2019年和2020年)涉及到数据库知识考点的有:
2010年题2;
2011年题2;
2012年题5;
2014年题5;
2015年题4,题5;
2017年题4;
2018年题4;
2021年题3
1.集中式数据架构和分布式数据架构
- 集中式数据架构
集中式数据架构:是由一个处理器,与它相关联的数据存储设备以及其他外围设备组成,它被物理地定义到单个位置。系统提供数据处理能力,用户可以在同样的站点上操作,也可以在地理位置隔开的其他站点上通过远程终端来操作。系统及其数据管理被某个或中心站点集中控制。
- 分布式数据架构
分布式数据架构:使用多个计算机系统上的多个局部数据系统构成,数据可以在不同的局部数据库中进行传送,由不同的数据库管理系统软件进行管理,运行在多种不同的计算机上,支持多种不同的操作系统。这些机器位于(或分布在)不同的地理位置并且通过多种通信网络连接在一起。企业的数据可以分布在不同的计算机上,一个应用程序可以操作位于不同地理位置的机器上的数据。
- 读写分离架构
利用数据库的复制技术,将数据的读和写分布在不同的处理结点上,从而达到提高可用性和扩展性。
- 分布式系统
分布式系统需要多个局部数据库系统,多个热备份数据库系统和多个数据缓存组成。局部数据库负责数据的写入,多个热备份数据系统用以解决单点故障的问题,数据缓存负责为应用提供所读取的数据。
- 分布式数据库系统+缓存的增,删,改,查
读取数据:应用访问缓存,如果命中则返回,否则从局部数据库系统中读取数据并将数据加载到缓存后返回。
添加数据:采用延迟加载策略,应用将数据直接写入到局部数据库。
更改数据:应用更改局部数据库中的数据,将缓存中的数据标记为失效。
删除数据:应用删除局部数据库中的数据,将缓存中的数据标记为失效。
- 提高数据库系统的可扩展性
集中式数据库系统:采用向上扩展,实现方式包括硬件扩容(增加CPU数量,内存容量,磁盘数量)和硬件升级(更换高端主机或高速磁盘等)
分布式数据库系统:采用向外扩展提升系统的可扩展性。实现方式包括数据复制,数据垂直切分,数据水平切分,缓存和全文搜索。
2.反规范化技术
规范化设计后,数据库设计者希望牺牲部分规范化来提高性能,这种从规范化设计的回退方法叫作反规范化技术。反规范化设计允许保留或者新增一些冗余数据,从而减少数据查询中表连接的数目或简化计算过程,提高数据访问效率。
- 采用反规范化技术的益处
能够减少数据库查询时SQL连接的数目,从而减少磁盘I/O数据量,提高查询效率。
- 可能带来的问题
数据的重复存储,浪费了磁盘空间;为了保障数据的一致性,增加了数据维护的复杂性。
-
常见的反规范化技术包括

-
反规范化解决数据不一致问题的办法

3.NoSQL数据库
NoSQL数据库支持高并发数据访问,性能较高;数据存储结构松散,能够灵活支持多种类型的数据格式;能够支持海量数据的存储,不存在单点故障和性能瓶颈。
- NoSQL缺点
不提供对SQL的支持,学习和应用迁移成本较高,对数据库事务的支持能力较弱。
- Redis数据类型

- Redis和MySQL保持数据实时同步问题

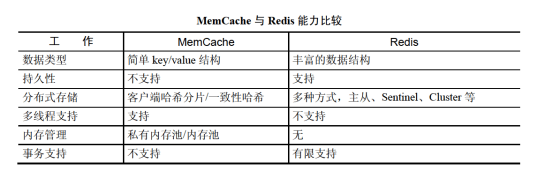
- MemCache 与Redis能力比较
- Redis分布式存储方案
主从模式,哨兵模式,集群模式
- 分布式缓存
分布式数据库缓存指的是在高并发环境下,为了减轻数据库压力和提高系统响应时间,在数据库系统和应用系统之间增加的独立缓存系统。
- Redis集群切片的常见方式有
1.客户端实现分片。分区逻辑在客户端实现,采用一致性哈希来决定 Redis节点。
2.中间件实现分片。在应用软件和Redis 中间,例如Twemproxy、Codis等,由中间件实现服务到后台Redis节点的路由分派。
3.客户端服务端协作分片。Redis Cluster模式,客户端可采用一致性哈希,服务端提供错误节点的重定向服务。
4.数据库
(0) 数据库的基本概念
- 需求分析
通过调查研究,了解用户的数据和处理要求,并按照一定格式整理成需求规格说明书。
数据流图,数据字典:数据项,数据流,数据存储,数据加工(处理过程),需求说明书
- 概念设计
是在需求分析阶段产生的需求说明书的基础上,按照特定的方法将它们抽象为一个不依赖于任何DBMS的数据模型,即概念模型。(设计ER图)
- 逻辑设计/逻辑结构设计
逻辑结构设计阶段的主要任务是确定数据模型、将ER图转换成指定数据模型、确定完整性约束、确定用户视图。
- 物理设计
对于给定的逻辑数据模型,选取一个最适合应用环境的物理结构
- 属性冲突
属性冲突:不同学校编码方式不同
属性值冲突:重量采用千克,榜
结构冲突:同一对象在不同应用中的抽象不同(职工在某一个应用中是实体,在另一个应用中是属性;不同ER图中属性的个数和排列次序不同)
命令冲突:同名异义,异名同一
- 弱实体,超类实体
弱实体:由多值属性转换为的实体。
超类实体:超类实体由多个实体中所共有的属性组成。
- 派生属性,BLOB型属性
派生属性:由其他属性计算而来的属性。
BLOB型属性:存放的一张图片或一个声音文件
(1) 关系型数据库管理系统和文件系统存储方式比较
| 设计难度 | 数据冗余程度 | 数据架构 | 应用扩展性 | |
|---|---|---|---|---|
| 关系型数据库 | 数据结构需要符合关系模式,设计难度较大; | 遵守数据库范式,数据冗余较少; | 以数据库为中心组织、管理数据; | 数据独立于应用系统,很容易在不同的应用系统之间共享数据。 |
| 文件系统 | 针对特定应用系统设计,难度较小; | 数据冗余较大,可能在多个文件中复制相同的数据属性; | 以应用系统为中心组织、管理数据; | 符合特定应用系统要求的文件数据很难在不同的应用系统之间共享。 |
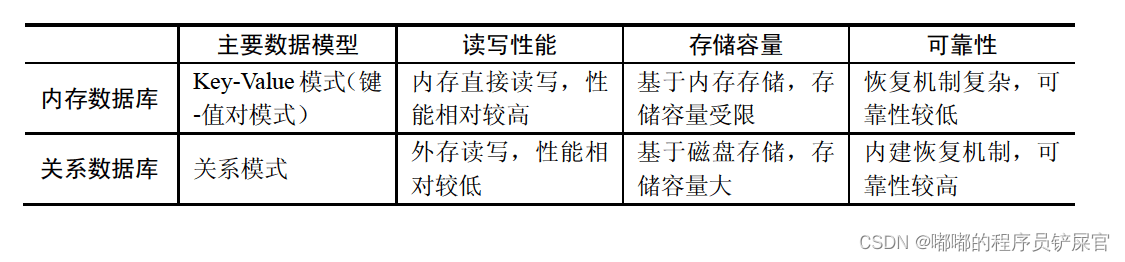
(2) 内存数据库和关系型数据库比较
(3) SQL语句的设计策略对查询性能的影响
SQL语句设计时,影响查询效率的设计原则是:
- 查询时尽量不要返回不需要的行、列;
- 需要进行多表连接查询时,尽量使用连接查询,避免使用子查询结构(子查询采用笛卡尔积,效率:mXn,连接查询从表中赛选符合条件的数据效率m/n);
- 尽量避免采用NOT IN、NOT EXIST、LIKE等使用全表查询的操作;
- 尽量避免使用DISTINCT 关键字;
(4) 数据库的数据持久层
- 什么是持久化
持久(Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的数据存储在关系型的数据库中,当然也可以存储在磁盘文件中、XML数据文件中等等。
- 什么是ORM(对象数据映射)
ORM-Object/Relational Mapper,即“对象-关系型数据映射组件”。对于O/R,即 Object(对象)和Relational(关系型数据),表示必须同时使用面向对象和关系型数据进行开发。
备注:建模领域中的 ORM 为Object/Role Modeling(对象角色建模)。另外这里是“O/R Mapper”而非“O/R Mapping”。相对来讲,O/R Mapping 描述的是一种设计思想或者实现机制,而 O/R Mapper指以O/R原理设计的持久化框架(Framework),包括 O/R机制还有 SQL自生成,事务处理,Cache管理等。
- 什么是持久化层
数据持久层是根据分层思想,通过建立逻辑数据操作接口,采取一定的对象/关系映射策略,隐藏数据库访问代码细节,向业务开发人员提供透明的对象持久化操作机制。
数据持久层技术分类:
| 技术方案 | 实现技术 |
|---|---|
| JDBC封装 | Spring JdbcTemplate |
| SQL Mapping | iBatis/MyBatis |
| O/R Mapping | TopLink,JDO,Hibernate |
| Entity Bean | BMP,CMP |
持久化层带来的好处:
- 分离业务逻辑层和数据层,降低两者之间的耦合;
- 通过对象/关系映射向业务逻辑提供面向对象的数据访问;
- 简化数据层访问,隐藏数据库连接、数据读写命令和事务管理细节。
MyBatis/iBatis和Hibernate的区别:
sql 优化方面:
- Hibernate 使用 HQL(Hibernate Query Language)语句,独立于数据库。不需要编写大量的 SQL,就可以完全映射,但会多消耗性能,且开发人员不能自主的进行 SQL 性能优化。提供了日志、缓存、级联(级联比 MyBatis 强大)等特性。
- MyBatis 需要手动编写 SQL,所以灵活多变。支持动态 SQL、处理列表、动态生成表名、支持存储过程。工作量相对较大。
开发方面:
- MyBatis 是一个半自动映射的框架,因为 MyBatis 需要手动匹配 POJO 和 SQL 的映射关系。
- Hibernate 是一个全表映射的框架,只需提供 POJO 和映射关系即可。
缓存机制比较:
-
Hibernate 的二级缓存配置在 SessionFactory 生成的配置文件中进行详细配置,然后再在具体的表-对象映射中配置缓存。
-
MyBatis 的二级缓存配置在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。并且 Mybatis 可以在命名空间中共享相同的缓存配置和实例,通过 Cache-ref 来实现。
-
Hibernate 对查询对象有着良好的管理机制,用户无需关心 SQL。所以在使用二级缓存时如果出现脏数据,系统会报出错误并提示。而 MyBatis 在这一方面,使用二级缓存时需要特别小心。如果不能完全确定数据更新操作的波及范围,避免 Cache 的盲目使用。否则脏数据的出现会给系统的正常运行带来很大的隐患。
Hibernate 优势:
- Hibernate 的 DAO 层开发比 MyBatis 简单,Mybatis 需要维护 SQL 和结果映射。
- Hibernate 对对象的维护和缓存要比 MyBatis 好,对增删改查的对象的维护要方便。
- Hibernate 数据库移植性很好,MyBatis 的数据库移植性不好,不同的数据库需要写不同 SQL。
- Hibernate 有更好的二级缓存机制,可以使用第三方缓存。MyBatis 本身提供的缓存机制不佳。
Mybatis优势:
- MyBatis 可以进行更为细致的 SQL 优化,可以减少查询字段。
- MyBatis 容易掌握,而 Hibernate 门槛较高。
(5) 分区,分库,分表
分区
就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的
分表
就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则得到对应的字表明,然后操作它。
分库
一旦分表,一个库中的表会越来越多
学习博文连接:数据库分区、分表、分库、分片
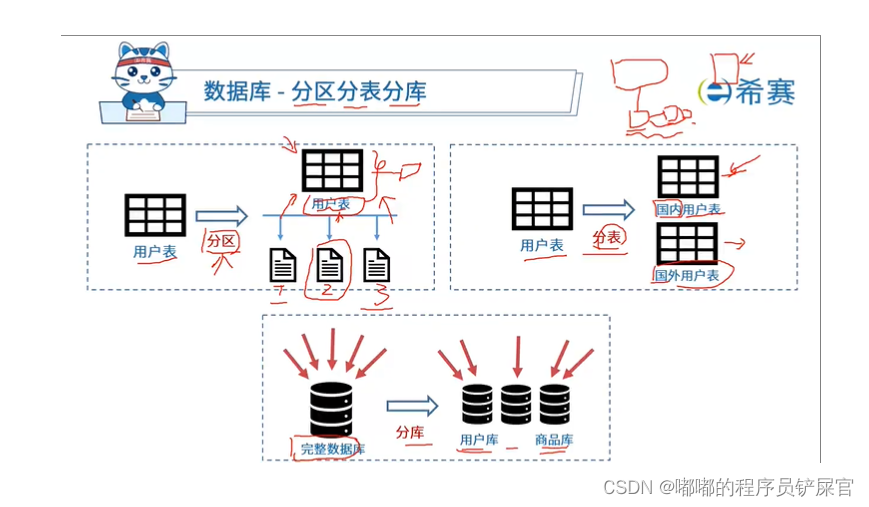
- 水平分区(真题中考到)
根据已知信息,系统数据库中存储的主要数据为以用户标识为索引的社交网络数据,采用水平分区机制可根据用户标识将用户数据进行水平分割,用户操作时先将请求分发到不同数据库分区,再进行具体数据库操作,以提高数据库访问效率。因此本系统中应主要使用水平分区机制。
(6) 主从复制
- 一主多从
在分布式数据库往往有多台数据库服务器,其中一台为主服务器,其他为从服务器,主服务器用于提供用户对数据库进行增删改操作,从服务器给用户提供查询操作。
- 主从复制的好处
①避免数据库单点故障:主服务器实时、异步复制数据到从服务器,当主数据库宕机时,可在从数据库中选择一个升级为主服务器,从而防止数据库单点故障。
②提高查询效率:根据系统数据库访问特点,可以使用主数据库进行数据的插入、删除及更新等写操作,而从数据库则专门用来进行数据查询操作,从而将查询操作分担到不同的从服务器以提高数据库访问效率。
(7) 性能
SQL语句设计时,影响查询效率的设计原则是:
查询时尽量不要返回不需要的行、列;
需要进行多表连接查询时,尽量使用连接查询,避免使用子查询结构;
尽量避免采用NOT IN、NOT EXIST、LIKE等使用全表查询的操作;
尽量避免使用DISTINCT关键字。
(8) 数据库访问方式
数据访问层常见的访问方式有5种,分别是在线访问、DAO (Data Access Object)、
DTO (Data Transfer Object)、离线数据模式、对象/关系映射(Object/Relation Mapping,ORM)。
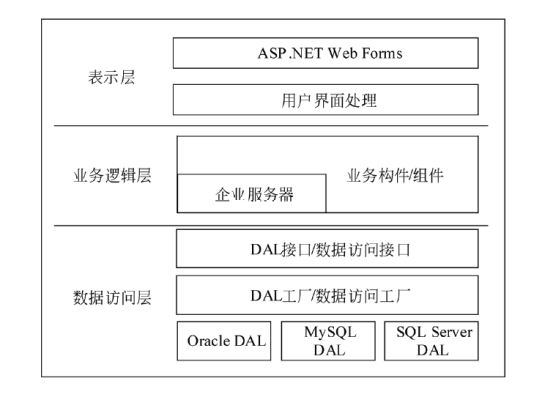
- 在线访问
在线访问是最基本的数据访问模式,也是最常用的。应用程序通过数据库提供的程序接口直接访问数据。其优点是灵活,性能高。缺点是需要程序员对数据库有较深了解,同时数据库的变更会导致相应程序的变更,数据库迁移困难。
- ORM
ORM是一种工具或平台,能够提供应用程序中的数据与关系数据库中的记录之间的相互转换,使得程序无须考虑记录,仅考虑对象。优点是简化程序开发,降低了对程序员关于数据库的知识要求,使得程序员可以仅关注于业务逻辑;缺点是不太容易处理复杂查询语句,性能比直接使用SQL要差。
- DAO
DAO(Data Access Object)是一个数据访问接口,数据访问:顾名思义就是与数据库打交道。夹在业务逻辑与数据库资源中间。
在核心J2EE模式中是这样介绍DAO模式的:为了建立一个健壮的J2EE应用,应该将所有对数据源的访问操作抽象封装在一个公共API中。用程序设计的语言来说,就是建立一个接口,接口中定义了此应用程序中将会用到的所有事务方法。在这个应用程序中,当需要和数据源进行交互的时候则使用这个接口,并且编写一个单独的类来实现这个接口在逻辑上对应这个特定的数据存储。 来源于-百度百科
- DTO
DTO 或者说数据传输对象(Data Transfer Objects)是在处理方法中携带数据的对象,目的是减少方法调用的次数 Martin Fowler 在他的书Patterns of Enterprise Application Architecture中第一次提出该模式。他解释说该模式的主要目的是通过将一次单一调用的多个参数分批来减少到服务器的往返次数。因而在这样的远程操作中降低网络开销。该实践的其它好处是序列化的逻辑(转换对象结构和数据为一种能被存储和传输的指定格式的机制)的封装。它提供了在序列化细微差别中一个单一改变点。它也解耦了表示层的领域模型,允许它们独自改变。 来源于-DTO(数据传输对象)模式
(9) 数据库中设计模式的使用
- 在新的数据层中增加数据层的原因
系统需要访问异构数据源,也就是说需要访问不同类型的数据库。因此,需要增加新的数据库访问层来封装对数据库的访问,使得在应用程序设计时,不会因为数据库种类的不同而受影响,尽量做到数据库无关。
- 工厂设计模式来实现对数据库访问的封装
工厂设计模式定义了创建对象的接口,允许子类决定实例化哪个类,而且允许请求者无须知道要被实例化的特定类,这样可以在不修改代码的情况下引入新类。
优点是:
1.没有了将应用程序类绑定到代码中的要求,可以使用任何实现了接口的类;
2.允许子类提供对象的扩展版本。
- 工厂设计模式的应用场景有
1.类不能预料它必须创建的对象的类。
2.类希望其子类指定它要创建的对象。
在数据访问层定义采用工厂模式,定义统一的操纵数据库的接口,然后根据数据库的不同,由类工厂来决定实例化哪个类。在具体类中实现特定的数据库访问类。这样,就可以实现由客户端指定或根据配置文件来选择访问不同的数据库,从而实现应用程序与数据库无关。

开源、云原生的融合云平台
更多推荐
 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)