多层感知器用实际例子和Python代码进行解释情绪分析
多层感知器用实际例子和Python代码进行解释情绪分析多层感知器是一种学习线性和非线性数据之间关系的神经网络。这是专门介绍深度学习系列的第一篇文章,深度学习是一组机器学习方法,其根源可以追溯到20世纪40年代。在过去的几十年里,深度学习因其在图像分类、语音识别和机器翻译等领域的突破性应用而受到关注。如果你想看到不同的深度学习算法,并通过现实生活中的例子和一些Python代码来解释,请继续关注。这一
多层感知器用实际例子和Python代码进行解释情绪分析 多层感知器是一种学习线性和非线性数据之间关系的神经网络。
这是专门介绍深度学习系列的第一篇文章,深度学习是一组机器学习方法,其根源可以追溯到20世纪40年代。在过去的几十年里,深度学习因其在图像分类、语音识别和机器翻译等领域的突破性应用而受到关注。
如果你想看到不同的深度学习算法,并通过现实生活中的例子和一些Python代码来解释,请继续关注。
这一系列的文章专注于深度学习算法,在过去的几年里,深度学习算法得到了广泛的关注,因为它的许多应用在我们的日常生活中占据了中心位置。从自动驾驶汽车到语音助手、人脸识别或将语音转录为文本的能力。
这些应用只是冰山一角。自20世纪40年代初以来,已经铺设了一条漫长的研究和渐进式应用的道路。我们今天看到的改进和广泛的应用是硬件和数据可用性赶上这些复杂方法的计算需求的高潮。
为什么深度学习改变了游戏规则
在传统的机器学习中,任何建立模型的人都必须是他们所从事的问题领域的专家,或者与专家合作。如果没有这种专家知识,设计和设计功能就会成为一个越来越困难的挑战[1]。机器学习模型的质量取决于数据集的质量,但也取决于特征对数据中的模式的编码程度。
深度学习算法使用人工神经网络作为其主要结构。它们与其他算法的不同之处在于,它们在特征设计和工程阶段不需要专家输入。神经网络可以学习数据的特征。
深度学习算法接收数据集并学习其模式,它们学习如何用自己提取的特征来表示数据。然后,它们将数据集的不同表征结合起来,每一个表征都能识别一个特定的模式或特征,成为数据集的一个更抽象、更高级的表征[1]。这种放手的方法,在特征设计和提取方面没有太多的人为干预,使算法能够更快地适应手头的数据[2]。
神经网络受到大脑结构的启发,但不一定是大脑结构的精确模型。关于大脑和它的工作原理,我们还有很多不了解的地方,但由于它具有开发智能的能力,它一直在许多科学领域充当着灵感的来源。尽管有一些神经网络是以了解大脑如何工作为唯一目的而创建的,但我们今天知道的深度学习并不是为了复制大脑的工作方式。相反,深度学习的重点是使系统能够学习多层次的模式组成[1]。
而且,就像任何科学进步一样,深度学习一开始并没有你在最近的文献中看到的复杂结构和广泛的应用。
这一切都始于一个基本结构,一个类似于大脑神经元的结构。
这一切都始于一个神经元
20世纪40年代初,神经生理学家沃伦-麦库洛赫(Warren McCulloch)与逻辑学家沃尔特-皮茨(Walter Pitts)合作,建立了一个大脑工作的模型。这是一个简单的线性模型,在给定一组输入和权重的情况下,产生一个正或负的输出。

麦库洛赫和皮茨的神经元模型
这种计算模型被有意称为神经元,因为它试图模仿大脑的核心构件如何工作。就像大脑神经元接收电信号一样,麦库洛赫和皮茨的神经元接收输入,如果这些信号足够强大,就把它们传递给其他神经元。
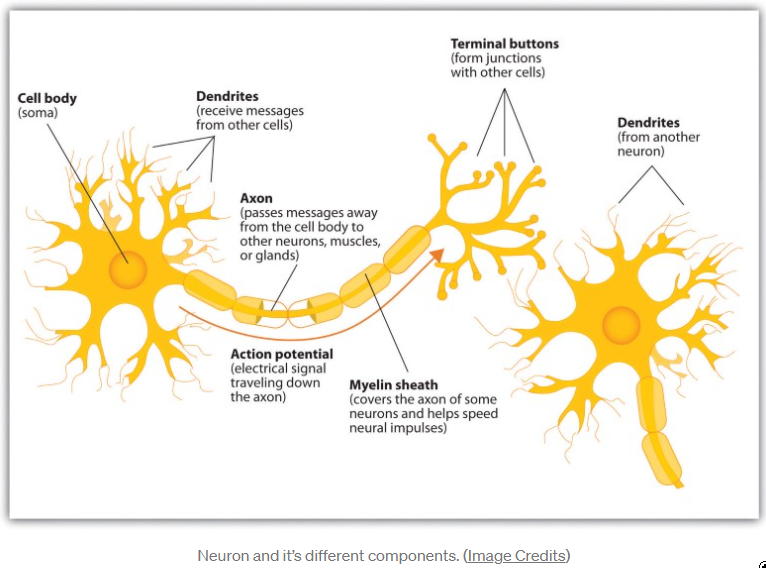
神经元和它的不同组成部分
神经元的第一个应用复制了一个逻辑门,其中你有一个或两个二进制输入,以及一个布尔函数,只有在给定正确的输入和权重时才会被激活。
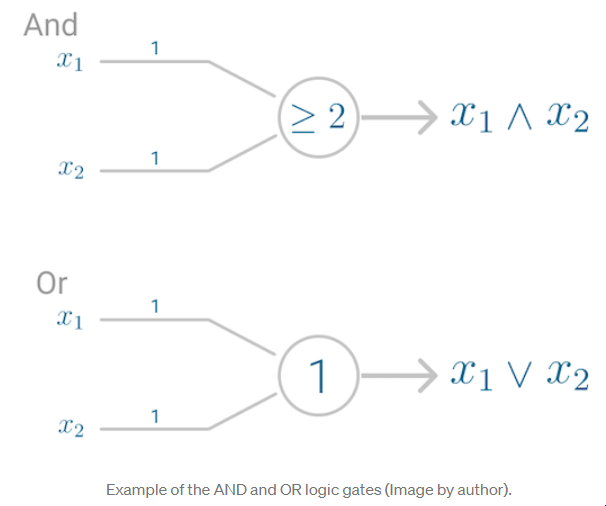
AND和OR逻辑门的例子
然而,这个模型有一个问题。它不能像大脑那样学习。获得所需输出的唯一方法是在模型中作为催化剂的权重事先被设定。
神经系统是一个神经元网,每个神经元都有一个体细胞和一个轴突[......]在任何瞬间,神经元都有一些阈值,激励必须超过这个阈值才能启动冲动[3]。
只是在十年之后,弗兰克-罗森布拉特才扩展了这个模型,并创造了一个可以学习权重以产生输出的算法。
在McCulloch和Pitt的神经元基础上,Rosenblatt开发了Perceptron。
感知器 尽管今天Perceptron被广泛认为是一种算法,但它最初是作为一种图像识别机器。它的名字来源于执行类似人类的感知功能,看到并识别图像。
特别是,人们的兴趣集中在这样一个想法上:一台机器能够将直接来自光、声音、温度等物理环境的输入概念化--我们都熟悉的 "现象世界"--而不是需要人类代理人的干预来消化和编码必要的信息。
罗森布拉特的感知器机器依赖于一个基本的计算单位--神经元。就像以前的模型一样,每个神经元都有一个细胞,接收一系列的输入和权重对。
罗森布拉特模型的主要区别是,输入被合并为一个加权和,如果加权和超过预定的阈值,神经元就会启动并产生一个输出。

Perceptrons神经元模型(左)和阈值逻辑(右) 阈值T代表激活函数。如果输入的加权和大于零,神经元输出值为1,否则输出值为零。
二进制分类的感知器
有了这个由激活函数控制的离散输出,感知器可以被用作二元分类模型,定义一个线性决策边界。它找到分离超平面,使错误分类的点和决策边界之间的距离最小[6]。
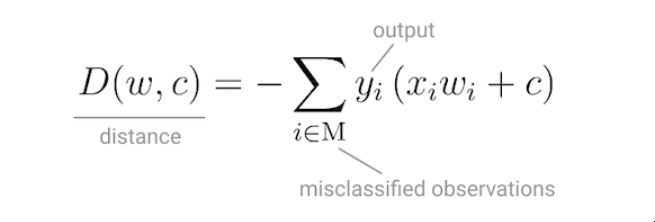
感受器的损失函数
为了最小化这个距离,Perceptron使用随机梯度下降作为优化函数。
如果数据是线性可分离的,可以保证随机梯度下降法在有限的步骤内收敛。
Perceptron需要的最后一块是激活函数,这个函数决定了神经元是否会启动。
最初的Perceptron模型使用的是sigmoid函数,光看它的形状,就很有意义了
sigmoid函数将任何实际输入映射为0或1的值,并编码为非线性函数。
神经元可以接收负数作为输入,它仍然能够产生一个0或1的输出。
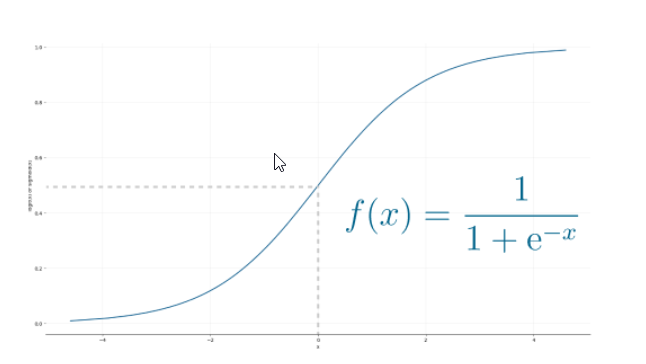
Sigmoid函数
但是,如果你看一下过去十年的深度学习论文和算法,你会发现它们中的大多数都使用整流线性单元(ReLU)作为神经元的激活函数。
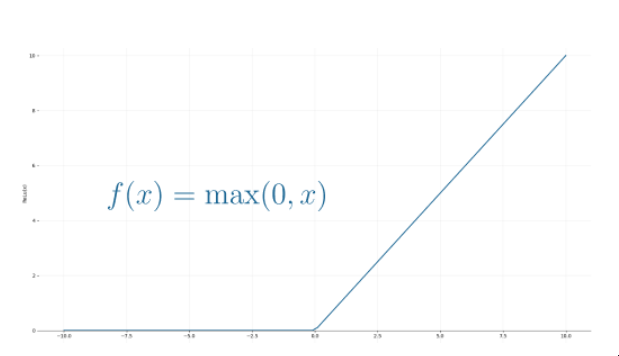
ReLU函数
ReLU被更多采用的原因是,它可以使用随机梯度下降法进行更好的优化,计算效率更高,而且是尺度不变的,也就是说,它的特性不受输入尺度的影响。
把它放在一起
神经元接收输入并随机选择一组初始权重。这些权重被组合成加权和,然后由激活函数ReLU决定输出的值。
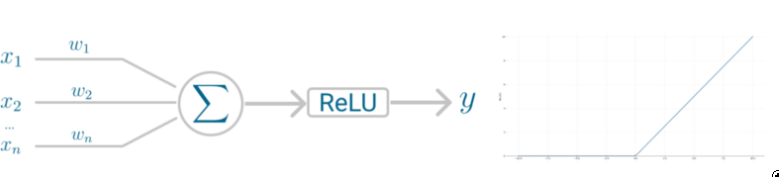
Perceptrons神经元模型(左)和激活函数(右)
但是你可能想知道,Perceptron实际上没有学习权重吗?
它是的! Perceptron使用随机梯度下降法来寻找,或者你可以说是学习,使错误分类点和决策边界之间的距离最小的权重集。一旦随机梯度下降收敛,数据集就会被一个线性超平面分隔成两个区域。
尽管有人说Perceptron可以代表任何电路和逻辑,但最大的批评是它不能代表XOR门,即排他性OR,其中门只在输入不同时返回1。
这一点几乎在十年后由Minsky和Papert在1969年证明了[5],并强调了只有一个神经元的Perceptron不能应用于非线性数据的事实。
多层感知器
多层感知器是为了解决这一限制而开发的。它是一种神经网络,输入和输出之间的映射是非线性的。
多层感知器有输入和输出层,以及一个或多个由许多神经元堆叠在一起的隐藏层。而在感知器中,神经元必须有一个施加阈值的激活函数,如ReLU或sigmoid,多层感知器中的神经元可以使用任何任意的激活函数。
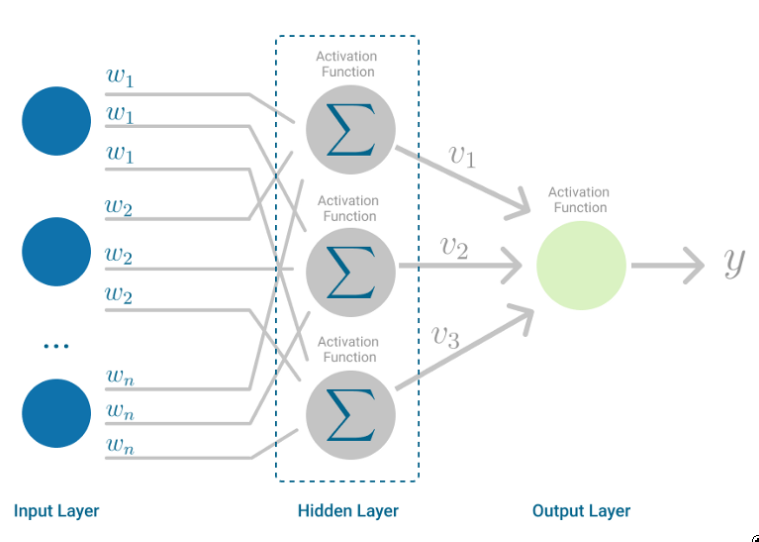
多层感知器
多层感知器属于前馈算法的范畴,因为输入与初始权重的加权和相结合,并受到激活函数的影响,就像在感知器中一样。但不同的是,每个线性组合都被传播到下一层。
每一层都把它们的计算结果反馈给下一层,即它们对数据的内部表示。这一直通过隐藏层到输出层。
但它有更多的内容。 如果算法只计算每个神经元的加权和,将结果传播到输出层,并停在那里,它就无法学习使成本函数最小化的权重。如果该算法只计算一次迭代,就不会有实际的学习。
这就是Backpropagation[7]发挥作用的地方。
反向传播
反向传播是一种学习机制,它允许多层感知器反复调整网络中的权重,目的是使成本函数最小化。
逆向传播要正常工作,有一个硬性要求。在神经元中结合输入和权重的函数,例如加权和,以及阈值函数,例如ReLU,必须是可微的。这些函数必须有一个有界的导数,因为梯度下降通常是多层感知器中使用的优化函数。

多层感知器,突出显示了前馈和反向传播的步骤
在每个迭代中,在加权和通过所有层转发后,计算所有输入和输出对的平均平方误差的梯度。然后,为了把它传播回去,第一个隐藏层的权重用梯度的值来更新。这就是权重如何被传播回神经网络的起点!这就是梯度下降法。

梯度下降法的一次迭代
这个过程一直持续到每个输入-输出对的梯度收敛为止,也就是说,与上一次迭代相比,新计算的梯度变化没有超过指定的收敛阈值。
让我们通过一个现实世界的例子来看看这个问题。
使用感知器进行情感分析
你的父母在乡下有一个舒适的床和早餐,大厅里有传统的留言簿。欢迎每一位客人在离开前写下字条,到目前为止,很少有人不写下简短的字条或鼓舞人心的话语就离开。有些人甚至留下了家里的狗莫莉的画。
夏天的季节已经接近尾声,这意味着在假期工作再次开始之前的清洁时间。在旧的储藏室里,你偶然发现了一个装满你父母多年来保留的留言簿的盒子。你的第一直觉是什么?让我们把所有的东西都读一遍吧!
读了几页之后,你才有了一个更好的想法。为什么不试着了解客人是否留下了积极或消极的信息?
你是一个数据科学家,所以这是一个二进制分类器的完美任务。
因此,你随机挑选了一些留言簿,作为训练集,转录了所有的信息,给它一个正面或负面情绪的分类,然后让你的表兄弟也对它们进行分类。
在自然语言处理任务中,一些文本可能是模糊的,所以通常你有一个文本的语料库,其中的标签是由3位专家商定的,以避免联系。
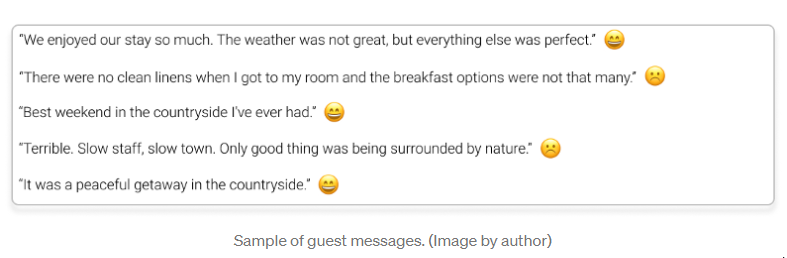
在为整个语料库分配了最终的标签后,你决定将数据拟合到Perceptron上,这是所有神经网络中最简单的一种。
但在建立模型之前,你需要将自由文本转化为机器学习模型可以处理的格式。
在这种情况下,你用 "术语频率-反文档频率"(TF-IDF)将留言簿上的文本表示为一个向量。这种方法将任何类型的文本编码为每个词或术语在每个句子和整个文档中的频率统计。
在Python中,你使用了ScikitLearn中的TfidfVectorizer方法,去掉了英文停顿词,甚至应用了L1规范化。
TfidfVectorizer(stop_words='chinese', lowercase=True, norm='l1')
用Perceptron进行二进制分类!
为了完成这个任务,你完全使用Perceptron,使用所有的默认参数。
在语料库上运行Perceptron的Python源代码
在对语料库进行矢量处理、拟合模型并对模型从未见过的句子进行测试后,你发现这个模型的平均准确率为67%。
Perceptron模型的平均准确率
对于Perceptron这样一个简单的神经网络来说,这还算不错的了!
平均来说,Perceptron大约每3条你父母的客人写的信息中就有一条会被错误分类。这让你怀疑,也许这个数据不是线性可分离的,你也可以用一个稍微复杂的神经网络来实现更好的结果。
在这种情况下,多层感知器的表现如何? 使用SckitLearn的多层感知器,你决定保持简单,只调整几个参数。
激活函数。ReLU,用参数activation='relu'指定 优化函数。随机梯度下降,用参数solver='sgd'指定。 学习率。逆向缩放,用参数learning_rate='invscaling'指定 迭代次数。20,用参数max_iter=20指定
在语料库上运行多层感知器的Python源代码。(图片由作者提供) 默认情况下,多层感知器有三个隐藏层,但是你想看看每层的神经元数量对性能的影响,所以你开始时每个隐藏层有2个神经元,设置参数num_neurons=2。
最后,为了看到每次迭代时损失函数的值,你还添加了参数verbose=True。
有3个隐藏层的多层感知器模型的平均精度,每个隐藏层有2个节点。(图片由作者提供) 在这种情况下,多层感知器有3个隐藏层,每个有2个节点,表现比简单的感知器差很多。
它的收敛速度相对较快,只需24次迭代,但平均准确率并不高。
Perceptron平均每3个句子中就有一个分类错误,而这个多层Perceptron则相反,平均每3个句子中就有一个预测出正确的标签。
如果你给神经网络增加更多的容量呢?当每个隐藏层有更多的神经元来学习数据集的模式时会发生什么?
使用同样的方法,你可以简单地改变num_neurons参数,比如说,把它设置为5。
buildMLPerceptron(train_features, test_features, train_targets, test_targets, num_neurons=5)
在隐蔽层中增加更多的神经元,肯定会提高模型的准确性
多层感知器模型的平均精度,有3个隐藏层,每个有5个节点。(图片由作者提供) 你保持了相同的神经网络结构,即3个隐藏层,但随着5个神经元的计算能力的增加,模型在理解数据的模式方面变得更好。它的收敛速度更快,平均准确率也翻了一番。
最后,对于这个特定的案例和数据集,多层感知器的表现和简单感知器一样好。但这绝对是一个很好的练习,看看改变每个隐藏层的神经元数量如何影响模型性能。
这不是一个完美的模型,可能还有一些改进的余地,但是下次有客人留言,你的父母不确定是正面还是负面的时候,你可以用Perceptron来获得第二种意见。
结论 与目前最先进的算法相比,第一个深度学习算法非常简单。Perceptron是一个只有一个神经元的神经网络,只能理解提供的输入和输出数据之间的线性关系。
然而,随着多层感知器的出现,视野得到了扩展,现在这个神经网络可以有很多层的神经元,并准备学习更复杂的模式。
希望你喜欢学习算法!
请继续关注本系列的下一篇文章,我们将继续探索深度学习的算法。
参考文献 LeCun, Y., Bengio, Y. & Hinton, G. 深度学习。自然 521, 436-444 (2015)
Ian Goodfellow, Yoshua Bengio, and Aaron Courville. 2016. 深度学习. 麻省理工学院出版社。
McCulloch, W.S., Pitts, W. A logical calculus of the ideas immanent in nervous activity. 数学生物物理学公报》5, 115-133 (1943)
弗兰克-罗森布拉特 感知器,一个感知和识别的自动机项目帕拉。康奈尔航空实验室 85, 460-461 (1957)
Minsky M.L. 和 Papert S. A. 1969. Perceptrons. Cambridge, MA: 麻省理工学院出版社。
Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani. (2013). An introduction to statistical learning : with applications in R. New York :Springer.
D. Rumelhart, G. Hinton, and R. Williams. Learning Representations by Back-propagating Errors. Nature 323 (6088): 533-536 (1986).
本文由 mdnice 多平台发布

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)