
千行代码率和代码行数总量
1、计算公式千行代码bug率=bug数/(代码行数/1000)2、bug率标准CMMI级别中做出了相关的指标规定,千行代码缺陷率(bug率):CMM1级 11.95‰CMM2级 5.52‰CMM3级 2.39‰CMM4级 0.92‰CMM5级 0.32‰3.统计方式一git log :不准确4.统计方式二使用cloc...
首先引用一句话:“用代码行数来衡量编程的进度,就如同用重量来衡量飞机的制造进度”这是比尔盖茨总结的一句非常经典的话”。
- 我们统计这个不是目的,只是用来寻找开发过程中的一些原因。
1、计算公式
千行代码bug率=bug数/(代码行数/1000)
2、bug率标准
CMMI级别中做出了相关的指标规定,千行代码缺陷率(bug率):
CMM1级 11.95‰
CMM2级 5.52‰
CMM3级 2.39‰
CMM4级 0.92‰
CMM5级 0.32‰
3.统计方式一,git log和git diff
git log的方式,依赖于提交记录,统计全量,统计个人,按时间段统计都能做,但有一些问题 :
- 经测试不能完全反应整体的记录,只是单纯的统计数量增加,空白行不能省略
- 在加上时间段统计后,调整时间,部分不准确,没找到问题
如果在分别统计个人的时候,git log还是比较好用
如需要可自动搜索相关git 命令,挺多的:
#统计总量
git log --pretty=tformat: --numstat | awk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }'
#统计变更总量:按时间节点
git log --pretty=tformat: --since ==2021-4-1 --until=2022-01-31 --numstat | awk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }'
#统计个人:按提交人
git log --format='%aN' | sort -u | while read name; do echo -en "$name\t"; git log --author="$name" --pretty=tformat: --since ==2021-4-1 --until=2022-01-31 --numstat | awk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }' -; done
#统计个人:按提交人和指定文件后缀(.html|.cs|.md|.xml|.properties)
git log --format='%aN' | sort -u | while read name; do echo -en "$name\t"; git log --author="$name" --pretty=tformat: --numstat | grep "\(.html\|.cs\|.md\|.xml\|.properties\)$" | awk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }' -; done
#统计总量和指定文件后缀(.html|.cs|.md|.xml|.properties)
git log --pretty=tformat: --numstat | grep "\(.cs\)$"| awk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "added lines: %s, removed lines: %s, total lines: %s\n", add, subs, loc }'
如果在分别统计多分支之间差异和去重的时候,git diff还是比较好用
git diff 有忽略空白和正则表达式的功能,能更精确的统计代码行数:

# 使用Git统计单个文件的代码行数
如果我们想知道一个文件的代码行数,可以使用Git命令行工具进行统计。Git提供了git diff --shortstat命令可以输出两个版本之间代码更改的摘要信息,其中包括添加行数和删除行数。
git diff --shortstat <commit> <commit> <file>
其中<commit>表示Git版本的标识符,<file>表示要统计的文件路径。执行以上命令,输出结果包括文件修改的行数信息。
2 files changed, 110 insertions(+), 2 deletions(-)
我们可以使用命令awk '{print $4}'来提取新增行数的数量,并使用sed 's/+//' | sed 's/-//'命令来替换+和-号,提取删除行数的数量。
git diff --shortstat <commit> <commit> <file> | awk '{print $4}' |sed 's/+//' | sed 's/-//'
# 使用Git统计整个仓库的代码行数
如果我们想了解整个Git仓库的代码行数,可以使用git diff --shortstat命令与Git提交日志相关联。
git rev-list --all --count | xargs git diff --shortstat HEAD^ | tail -1
以上命令将输出整个Git仓库的代码行数,以及新增和删除的代码行数。
# 使用Git统计代码行数排名
如果我们想了解Git仓库中不同的文件的代码行数排名,可以使用git ls-files命令列出仓库中的文件列表,并将其传递给git diff --shortstat命令计算每个文件的代码行数。
git ls-files | xargs -I % sh -c 'git diff --shortstat HEAD^ HEAD -- % | cat' | awk '{ delta += $4 - $6 } END { print delta }'"/>
以上命令将输出每个文件的代码行数变化,并将其按照增加或减少的代码行数进行排序。
# 使用Git图形化工具查看代码行数
如果只是简单地查看Git仓库中的代码行数,也可以使用一些Git图形化工具进行可视化展示。例如,使用Gitkraken,用户可以快速地查看Git仓库的提交历史,并可视化展示每个提交的代码行数变化。
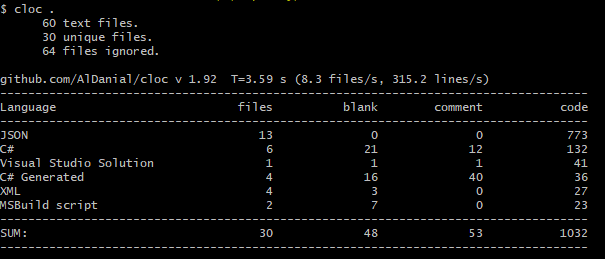
4.统计方式二,cloc
使用cloc,统计总量,能分别对多种语言统计。
不依赖于提交记录,只对当前目录下的文件进行遍历统计安装和使用方式如下:
#安装,最好是全局安装,以便在其他目录也能使用
npm instal -g cloc
#进入要统计的目录
cloc ./
#也能加一些其他参数,去掉指定目录不统计:--exclude-dir
cloc ./ --exclude-dir
如下图所示:
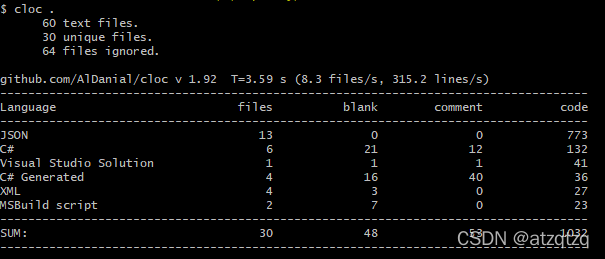
查看更多完整命令可以输入:cloc --help
一些cloc比较常用的指令:
--diff <set1> <set2> - 计算set1和set2的源文件之间的代码差异。 输入可以是文件和目录的混合。
--ignore-whitespace - 在使用--diff比较文件时忽略水平空格。
--max-file-size=<MB> - 如果要跳过大于给定大小MB的文件。
--exclude-dir=<dir1>,<dir2> - 排除给定的逗号分隔目录。
--exclude-ext=<ext1>,<ext2> - 排除给定的文件扩展名。
--out=<file> - 将结果保存到<file> 。
--quiet - 禁止所有信息消息并仅显示最终报告。
3.统计方式三:使用linux命令中的wc统计
在统计总量的时候,相对还是比较麻烦和不太直观,去掉空白和注释要自行使用shell处理,但能指定后缀统计结果
#遍历当前目录及子目录下的文件统计行数
find . -name "*.cs" | xargs wc -l {}
或者
git ls-files | xargs cat | wc -l
#使用cat,grep,awk,可以尝试去掉空白和注释,还未测试
find . -name "*.cs" |xargs cat| wc -l
如所示:

4.统计方式四:使用visual code 的插件
- VS Code Counter
5.统计svn管理下的代码行数
需要安装svn命令行工具,
需要安装java环境,并下载statsvn.jar工具;
参考:https://www.cnblogs.com/zktww/p/14781052.html

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)