
并行处理及分布式系统期末总结笔记
耗时36个小时
并行处理及分布式系统期末总结笔记
1、任务并行、数据并行的应用
任务并行:将许多可以解决问题的任务分割,然后分布在一个或者多个核上进行程序的执行。
数据并行:将可以解决问题的数据进行分割,将分割好的数据放在一个或者多个核上进行执行;每一个核对这些数据都进行类似的操作。
2、冯诺依曼体系结构的瓶颈及改进,Flynn分类法涉及的几种模型及其特点
冯诺依曼体系结构的瓶颈:主存和CPU之间的分离。
改进措施:缓存(caching),虚拟存储器(虚拟内存),低层次并行
Flynn分类法
SISD(单指令流单数据流):典型的冯诺伊曼系统,一次执行一条指令,一次存取一个数据项。
SIMD:对多个数据执行相同的指令,实现数据并行。
缺点:所有ALU都需要执行相同的指令,或者保持空闲状态。在经典设计中,它们还必须同步运行。ALU不能进行指令存储。对于大型数据并行问题有效,但对于其它更复杂的并行问题无效。
MIMD:支持多个数据流上同时运行多个指令流。通常由一组完全独立的处理单元或核心组成,每一个核心都有自己的控制单元(CU)和计算单元(ALU)
共享内存系统:隐式通信

分布式内存系统:显式通信

3、Cache的特点,Cache缺失、Cache命中、Cache一致性及解决方法、伪共享、流水线、多发射
1)缓存(cache):内存位置集合,可以在比其它存储器有更短的访问开销。CPU缓存通常与CPU位于同一芯片上,访存开销比普通内存更快。
局部性原理:在访问完一个内存区域,程序会在不久的将来(时间局部性)访问邻近的区域(空间局部性)。
空间局部性(Spatial locality ):访问临近的位置。
时间局部性(Temporal locality ):最近访问的位置,在不久的将来还会访问。
cache命中:当向cache查询信息时,如果cache中有信息,则称为cache命中。
cache缺失:如果信息不存在,则称为cache缺失。
当CPU写数据到cache时,cache中的值可能与主存中的值不一致.
写直达:通过在写入到缓存时,更新主存中的数据来解决这个问题
写回:将缓存中的数据标记为脏数据。当缓存行(cache line )被内存中的新缓存行替换时,脏缓存线被写入内存。
cache映射:
全相联:一个新cache line可以放在缓存的任何位置
直接映射:每一条高速缓存线在高速缓存中有一个唯一的位置,它将被分配到那里
n路相联:每条高速缓存线可以被放置在n个不同的位置中的一个
Cache一致性问题:单核处理器系统的 Cache 对如下情况没有提供保证:在多核系统中,各个核的 Cache 存储相同变量的副本,当一个处理器新 Cache 中该变量的副本时,其他处理器应该知道该变量己更新,即其他处理中 Cache 的副本也应该更新。
解决方法:监听cache一致性协议,基于目录的cache一致性协议
伪共享:缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
2)虚拟内存
虚拟内存的功能是作为二级存储器的高速缓存。
它利用了时空局部性原理.
它只把正在运行的程序的活动部分保存在主存中
Swap 空间:那些空闲的部分被保存在一个二级存储块中。
分页(Pages):数据块和指令块。
3)指令级并行
通过让多个处理器或功能单元同时执行指令来提高处理器性能。
流水线:将功能单元分阶段安排。例如将浮点加法器分成7个单独的硬件或功能部件。第一个单元获取两个操作数,第二个单元比较指数,等等。一个功能部件的输出作为下一个功能部件的输入
多发:多个指令同时启动执行。多发处理器复制计算单元,同时执行程序中的不同指令。
静态多发:功能单元在编译时被安排
动态多发:功能单元在运行时被安排
4、加速比、效率、阿姆达尔定律
p:核数
加速比(S):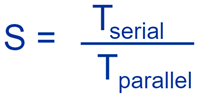
效率(E):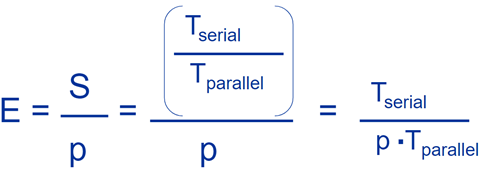
并行开销的影响:
问题规模变大时,加速比和效率增加;问题规模变小时,加速比和效率降低。
阿姆达尔定律:除非所有的串行程序都能够并行,否则无论可用的核的数量再多,加速比都会受限。
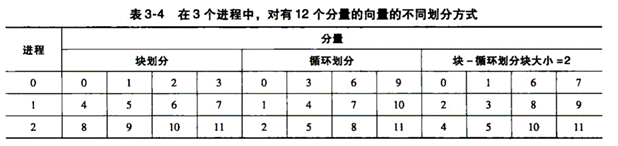
5、静态线程、动态线程、伸缩性/可扩展性、数据依赖的识别、任务划分方式及应用
1)动态线程:主线程等待任务,有任务时派生新线程,当新线程完成时任务后,结束新线程,资源的有效使用,但是线程的创建和终止非常耗时。
静态线程:派生出所有线程并分配任务,但线程不被终止直到被清理,性能更好,但可能会浪费系统资源。
2)可拓展性:问题规模增加的倍率与进程/线程数增加的倍率相同,效率E恒定,则程序是可拓展的。
如果在增加进程/线程的数量时,可以维持固定的效率,却不增加问题规模,那么程序称为强可扩展(strongly scalable)。
如果在增加进程/线程数量的同时,只有以相同倍率增加问题规模才能使效率值保持不变,那么程序就称为弱可扩展的(weakly scalable)
3)数据依赖的识别:有依赖关系的语句,其中至少一条语句会有序地写或更新变量。因此为了检测循环依赖,我们只需要重点观察被循环体更新的变量,即我们应该寻找在一个迭代中被读或被写,而在另一个迭代中被写的变量。
4)并行程序设计步骤:
划分(Partitioning):将要执行的指令和数据按照计算拆分为多个小任务。
通信(Communication):确定前一步所识别出来的任务之间需要执行哪些通信。
聚集或聚合(Agglomeration or aggregation):将第一步中确定的任务和通信合并成更大的任务。
分配(Mapping):将上一步聚合好的任务分配给进程/线程.

6、链表操作及分析
Member:查找遍历
Insert:
Delete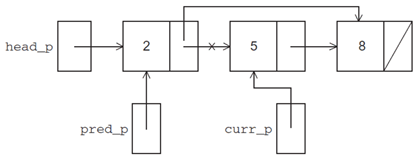
多线程链表:互斥锁:任何时候只允许一个线程访问整个链表。
细粒度锁:任何时候只允许一个线程访问任一给定结点。
读写锁:多个线程可以通过调用读锁函数同时获得锁,而只有一个线程可以通过调用写锁函数获得锁。
7、MPI常用的API及其应用

MPI_Init定义由用户启动的所有进程所组成的通信子称为MPI_COMM_WORLD


msg_buf_p:指向包含消息内容的内存块的指针;
msg_size:消息大小;
msg_type:消息类型;
dest:接收消息的进程的进程号;
tag:消息标签(标识消息);
MPI_Comm:通信子,指定通信范围

source:发送消息的进程的进程号;
MPI_Status:通常赋予MPI_STATUS_IGNORE

8、Pthreads常用的API及其应用,互斥锁、忙等待的实现及应用
pthread_create()
int pthread_create(
pthread_t *restrict tidp, //新创建的线程ID指向的内存单元。
const pthread_attr_t *restrict attr, //线程属性,默认为NULL
void *(*start_rtn)(void *), //新创建的线程从start_rtn函数的地址开始运行
void *restrict arg //默认为NULL。若上述函数需要参数,将参数放入结构中并将地址作为arg传入。
);
停止线程pthread_join
int pthread_join(
pthread_t tid, //需要等待的线程,指定的线程必须位于当前的进程中,而且不得是分离线程
void **status //线程tid所执行的函数返回值(返回值地址需要保证有效),其中status可以为NULL
);
忙等待:在忙等待中,线程不停地测试某个条件,但实际上,直到某个条件满足之前,不会执行任何有用的工作。
应用:使用忙等待求全局和。
互斥锁(互斥量):互斥量(互斥锁)是一种特殊类型的变量,它可以限制每次只允许一个线程访问临界区。
应用:使用互斥量求全局和
9、OpenMP常用的编译指令及其子句应用
pragma omp parallel:最基本的 parallel 指令,运行结构化代码块的线程数由运行时系统决定。
子句:是一些用来修改指令的文本
# pragma omp parallel num_threads ( thread_count ):num_threads子句添加到 parallel 指令中,允许程序员指定执行代码块的线程数
归约子句:归约是一种重复地对操作数序列应用相同的归约操作符以获得一个唯一结果的计算。

Parallel for指令: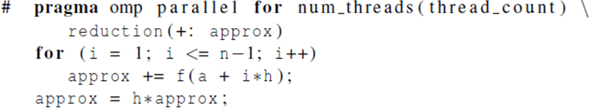
default子句:使用这个子句,编译器将要求我们指定在块中使用的每个变量的作用域和已经在块之外声明的变量的作用域。
Schedule子句:
Atomic 子句: 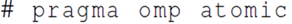
10、课本典型案例:矩阵向量乘、曲边梯形面积计算、通过数学求和公式计算π、蒙特卡洛方法计算π、奇偶交换排序
矩阵向量乘法(MPI)


矩阵向量乘法(Pthreads)

曲边梯形面积计算(MPI)


曲边梯形面积计算(OpenMP)


通过数学求和公式计算π

蒙特卡洛方法计算π
number_in_circle = 0;
for(toss = 0; toss < number_of_tosses; toss++){
x = random double between - 1 and 1;
y = random double between - 1 and 1;
distance_squared = x * x + y * y;
if(distance_squared <= 1) number_in_circle++;
}
pi_estimate = 4 * number_in_circle / ((double) number_of_tosses);
奇偶交换排序(MPI)



奇偶交换排序(OpenMP)


鸿蒙生态一站式服务平台。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)