
23-29 经典网络架构 [动手学深度学习v2]
LeNet(1998)Figure.1 Data flow in LeNet. The input is a handwritten digit, the output a probability over 10 possible outcomes.LeNet是早期成功的神经网络;先使用卷积层来学习图片空间信息,然后通过池化层来降低卷积层对图片的敏感度,最后使用全连接层来转换到类别空间。AlexN
-
LeNet(1998)

Figure.1 Data flow in LeNet. The input is a handwritten digit, the output a probability over 10 possible outcomes. LeNet是早期成功的神经网络;先使用卷积层来学习图片空间信息,然后通过池化层来降低卷积层对图片的敏感度,最后使用全连接层来转换到类别空间。
-
AlexNet(2012)

Figure.2 From LeNet (left) to AlexNet (right). AlexNet本质上是更大更深的LeNet;主要改进是加入了丢弃法(dropout)、激活函数从sigmoid变到ReLU(减缓梯度消失)、MaxPooling、数据增强;计算机视觉方法论的改变。
-
VGG(2014)

Figure.3 From AlexNet to VGG that is designed from building blocks. VGG可以看作是更大更深的AlexNet(重复的VGG块);VGG使用可重复使用的卷积块来构建深度神经网络,不同的卷积块个数和超参数可以得到不同复杂度的变种。
import torch from torch import nn def vgg_block(num_convs, in_channels, out_channels): layers = [] for _ in range(num_convs): layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)) layers.append(nn.ReLU()) in_channels = out_channels layers.append(nn.MaxPool2d(kernel_size=2, stride=2)) return nn.Sequential(*layers) conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512)) def vgg(conv_arch): conv_blks = [] in_channels = 1 for (num_convs, out_channels) in conv_arch: conv_blks.append(vgg_block(num_convs, in_channels, out_channels)) in_channels = out_channels return nn.Sequential( *conv_blks, nn.Flatten(), nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 10)) -
NiN (2014)

Figure.4 Comparing architectures of VGG and NiN, and their blocks. NiN块:一个卷积层后面跟两个
1x1卷积层 [可以看作按照输入像素逐一去做的全连接层]:步幅1,无填充,输出形状跟卷积层输出一样,起到全连接层的作用。NiN架构:无全连接层;交替使用NiN块和步幅为2的最大池化层(逐步减小高宽和增大通道数);最后使用全局平均池化层得到输出(其输入通道数是类别数)。
import torch from torch import nn def nin_block(in_channels, out_channels, kernel_size, strides, padding): return nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding), nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU()) nin_net = nn.Sequential( nin_block(1, 96, kernel_size=11, strides=4, padding=0), nn.MaxPool2d(3, stride=2), nin_block(96, 256, kernel_size=5, strides=1, padding=2), nn.MaxPool2d(3, stride=2), nin_block(256, 384, kernel_size=3, strides=1, padding=1), nn.MaxPool2d(3, stride=2), nn.Dropout(0.5), nin_block(384, 10, kernel_size=3, strides=1, padding=1), nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten()) -
GoogLeNet (2014)
Inception块:4个路径从不同层面抽取信息,然后在输出通道维合并(通道数会变的很多);不改变高宽,只改变通道数。

Figure.5 Structure of the Inception block. import torch from torch import nn from torch.nn import functional as F class Inception(nn.Module): # `c1`--`c4` are the number of output channels for each path def __init__(self, in_channels, c1, c2, c3, c4, **kwargs): super(Inception, self).__init__(**kwargs) # Path 1 is a single 1 x 1 convolutional layer self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1) # Path 2 is a 1 x 1 convolutional layer followed by a 3 x 3 # convolutional layer self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1) self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1) # Path 3 is a 1 x 1 convolutional layer followed by a 5 x 5 # convolutional layer self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1) self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2) # Path 4 is a 3 x 3 maximum pooling layer followed by a 1 x 1 # convolutional layer self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1) def forward(self, x): p1 = F.relu(self.p1_1(x)) p2 = F.relu(self.p2_2(F.relu(self.p2_1(x)))) p3 = F.relu(self.p3_2(F.relu(self.p3_1(x)))) p4 = F.relu(self.p4_2(self.p4_1(x))) # Concatenate the outputs on the channel dimension return torch.cat((p1, p2, p3, p4), dim=1)GoogLeNet:分为5段,有9个Inception块。

Figure.6 The GoogLeNet architecture. b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1), nn.ReLU(), nn.Conv2d(64, 192, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32), Inception(256, 128, (128, 192), (32, 96), 64), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64), Inception(512, 160, (112, 224), (24, 64), 64), Inception(512, 128, (128, 256), (24, 64), 64), Inception(512, 112, (144, 288), (32, 64), 64), Inception(528, 256, (160, 320), (32, 128), 128), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128), Inception(832, 384, (192, 384), (48, 128), 128), nn.AdaptiveAvgPool2d((1,1)), nn.Flatten()) google_net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10)) -
ResNet(2015)
-
残差块: f ( x ) = x + g ( x ) f(x) = x + g(x) f(x)=x+g(x)
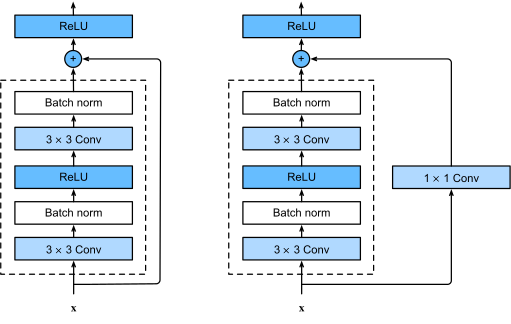
Figure.7 ResNet block with and without 1x1 convolution. -
ResNet架构:类似VGG和GoogLeNet的总体架构,但替换成了ResNet块。
-
残差块使得很深的网络更加容易训练,甚至可以训练一千层的网络;残差网络对随后的深层神经网络设计产生了深远影响,无论是卷积类网络还是全连接类网络。
-

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)