

github疯狂涨星-基于Transformer的端到端3D目标检测
我们训练了一个端到端Transformer模型,用于点云上的三维目标检测。我们的模型有一个用于特征编码的Transformer编码器和一个用于预测盒子的Transformer解码器。对于一个看不见的输入,我们计算从参考点(蓝点)到场景中所有点的自我注意力,并以红色显示注意值最高的点。解码器将注意力集中在一个实例中,这使预测边界框变得更容易。摘要:我们提出了3DETR模型,一个端到端的Transfo
我们训练了一个端到端Transformer模型,用于点云上的三维目标检测。我们的模型有一个用于特征编码的Transformer编码器和一个用于预测盒子的Transformer解码器。对于一个看不见的输入,我们计算从参考点(蓝点)到场景中所有点的自我注意力,并以红色显示注意值最高的点。解码器将注意力集中在一个实例中,这使预测边界框变得更容易。
摘要:我们提出了3DETR模型,一个端到端的Transformer为基础的三维点云对象检测模型。与现有的检测方法相比,3DETR应用了一些3D特定感知的偏差,只需对普通Transformer块进行简单修改。具体而言,我们发现具有非参数查询和傅里叶位置嵌入的标准Transformer与使用具有手动调整超参数的三维特定运算符库的专用体系结构具有竞争力。尽管如此,3DETR在概念上简单且易于实现,通过结合3D领域知识实现了进一步的改进。通过大量的实验,我们发现3DETR的性能优于成熟且高度稳定的算法。在具有挑战性的ScanNetV2数据集上优化VoteNet基线9.5%。此外,我们还表明3DETR适用于检测不到的3D任务,可以作为未来研究的基础。

(左)3DETR是一种端到端可训练的Transformer,它将一组3D点(点云)作为输入并输出一组3D边界框。Transformer编码器使用多层自我注意力产生一组逐点特征。点特征和一组“查询”嵌入被输入到Transformer解码器,该解码器生成一组方框。我们将预测框与地面真相相匹配,并优化一组损失。我们的模型不使用颜色信息(仅用于可视化)。(右)我们是随机的采样一组嵌入的“查询”点,然后由解码器将其转换为边界框预测。
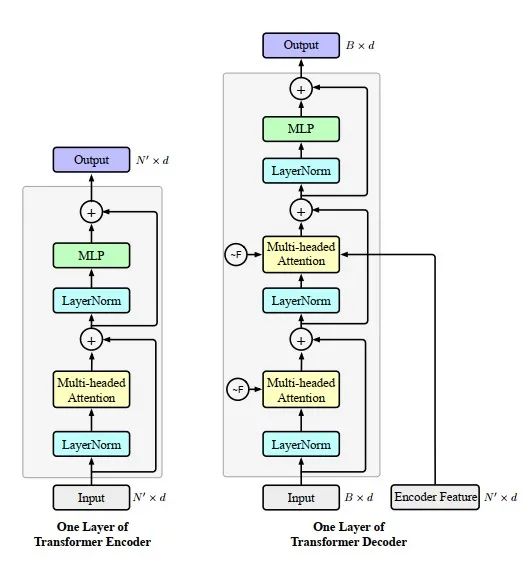
编码器和解码器的体系结构。我们提出了3DETR编码器和解码器的一层结构。编码器层将N点的N×d特征作为输入,并输出N×d特征。它执行自我注意力,然后执行MLP。解码器将编码器的N×d点特征作为输入B×d特征(查询嵌入或先前的解码器层),输出B盒的B×d特征。解码器在B查询/框特征之间执行自我注意力,并在B查询/框特征和N点特征之间执行交叉注意。我们使用傅里叶位置编码,其中所有3DETR模型均使用d=256。
实验结果:
微信公众号:

下载对应的论文,在公众号中回复:3DETR

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)