
微笑测试软件,如何制作人脸微笑检测程序
原标题:如何制作人脸微笑检测程序这里介绍一个深度学习的简单应用,制作一个微笑检测程序。用深度学习技术做分类,然后再用OpenCV的级联分类器做人脸识别,基本可以做到实时检测。下面展示一个效果图(示意): 下面介绍微笑脸分类模型的构建:数据介绍数据地址:https://github.com/hromi/SMILEsmileD数据包含13165张灰度图片,每张图片的尺寸是64*64。这个数据集并不算平
原标题:如何制作人脸微笑检测程序
这里介绍一个深度学习的简单应用,制作一个微笑检测程序。用深度学习技术做分类,然后再用OpenCV的级联分类器做人脸识别,基本可以做到实时检测。下面展示一个效果图(示意):

下面介绍微笑脸分类模型的构建:
数据介绍
数据地址:https://github.com/hromi/SMILEsmileD
数据包含13165张灰度图片,每张图片的尺寸是64*64。这个数据集并不算平衡,13165张图片中,有9475张图片不是笑脸图片,有3690张图片是笑脸图片。数据差异很大。
数据预处理
首先导入相应的包:
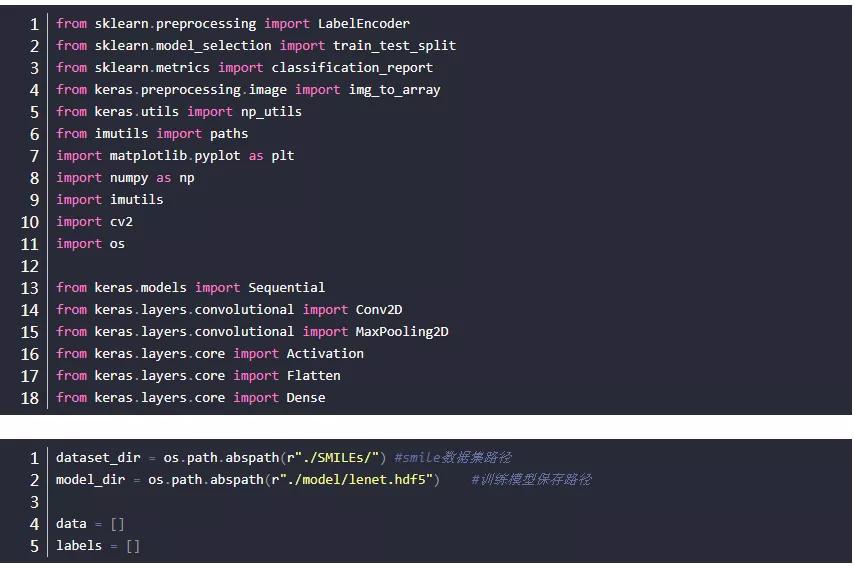
下面需要解决一下样本不平衡问题。
数据集里面有9475个笑脸样本,和3690个非笑脸样本。下面的代码中classTotals就是按列加和labels的one-hot编码,所以结果是[9475, 3690] 我们要解决数据不平衡问题可以使用classWeight权重,相比于笑脸,我们给非笑脸以2.56倍的权重。损失函数权重计算的时候对非笑脸进行相应扩大,以此来解决数据不平衡问题。
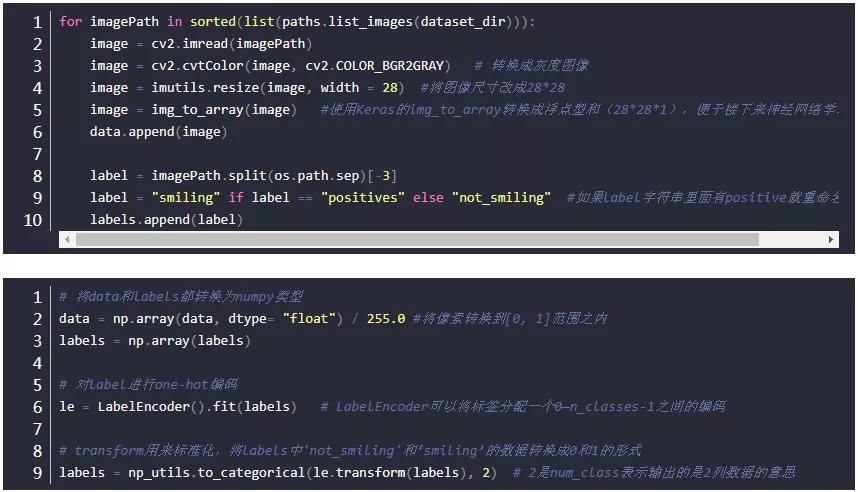
下面需要解决一下样本不平衡问题。

stratify是为了保持split前类的分布。比如有100个数据,80个属于A类,20个属于B类。如果train_test_split(… test_size=0.25, stratify = y_all), 那么split之后数据如下:
training: 75个数据,其中60个属于A类,15个属于B类。
testing: 25个数据,其中20个属于A类,5个属于B类。
用了stratify参数,training集和testing集的类的比例是 A:B= 4:1,等同于split前的比例(80:20)。通常在这种类分布不平衡的情况下会用到stratify

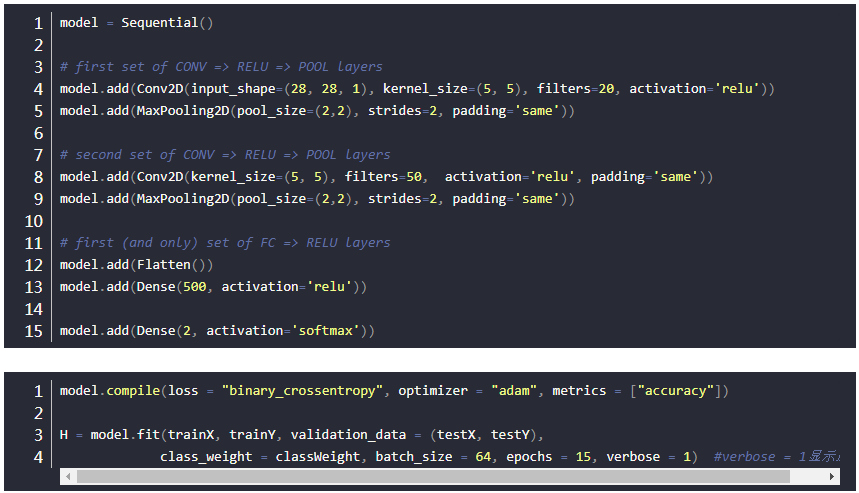
使用LeNet实现笑脸检测分类
下面是模型实现部分:
keras没有直接可以统计recall和f1值的办法。可以用sklearn。但是sklearn没有办法直接处理Keras的数据,所以要经过一些处理。Keras计算需要二维数组,但classification_report可以处理的是一维数列,所以这里使用argmax按行返回二维数组最大索引,这样也算是一种0-1标签的划分了。
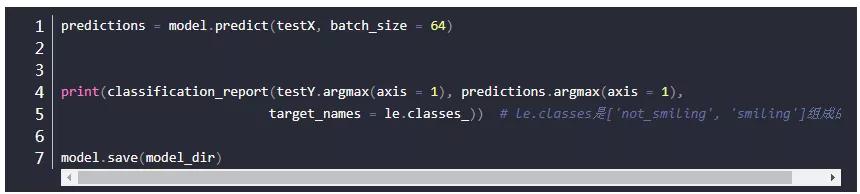
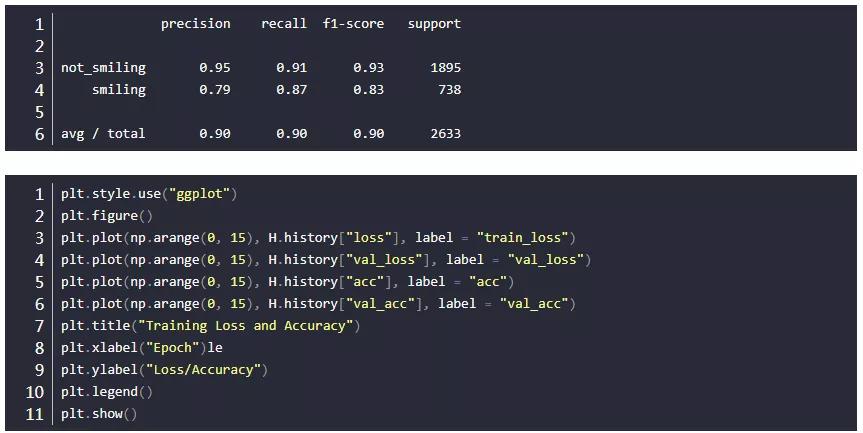
输出结果:
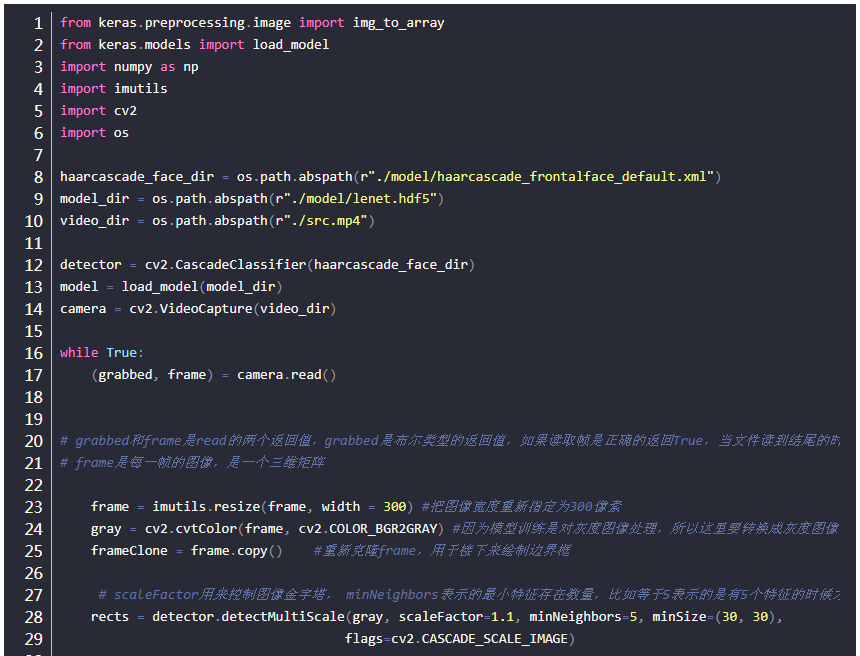
人脸检测实现
这里使用OpenCV的Haar特征和级联分类器来实现实时人脸检测,关于Haar特征和级联分类器的理论知识,可以看这里
我们在代码中使用了OpenCV这个工具来具体实现,在OpenCV中,相应算法都已经做好了封装,直接调用就可以了。值得一提的是,人脸检测的模型已经提前训练好了,这里我们直接调用模型就可以在,是一个XML格式的文件“haarcascade_frontalface_default.xml”,一般在opencv-3.4\opencv\sources\data\haarcascades路径下可以找到。下面是具体代码实现:
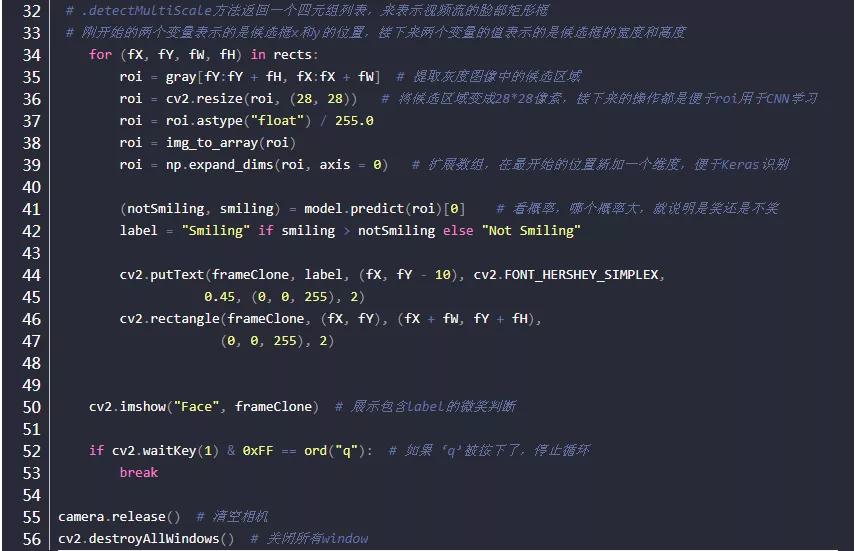
detector.detectMultiScale
这里,对detector.detectMultiScale做一点说明:
为了检测到不同大小的目标,一般有两种做法:逐步缩小图像;或者,逐步放大检测窗口。缩小图像就是把图像长宽同时按照一定比例(默认1.1 or 1.2)逐步缩小,然后检测;放大检测窗口是把检测窗口长宽按照一定比例逐步放大,这时位于检测窗口内的特征也会对应放大,然后检测。在默认的情况下,OpenCV是采取逐步缩小的情况,如下图所示,最先检测的图片是底部那张大图。

然后,对应每张图,级联分类器的大小固定的检测窗口器开始遍历图像,以便在图像找到位置不同的目标。对照程序来看,这个固定的大小就是上图的红色框。
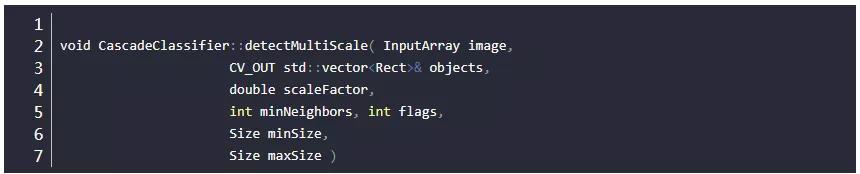
参数1:image–待检测图片,一般为灰度图像以加快检测速度;
参数2:objects–被检测物体的矩形框向量组;为输出量,如某特征检测矩阵Mat
参数3:scaleFactor–表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%
参数4:minNeighbors–表示构成检测目标的相邻矩形的最小个数(默认为3个)。如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除。如果min_neighbors 为 0, 则函数不做任何操作就返回所有的被检候选矩形框, 这种设定值一般用在用户自定义对检测结果的组合程序上;
参数5:flags=0:可以取如下这些值:
CASCADE_DO_CANNY_PRUNING=1, 利用canny边缘检测来排除一些边缘很少或者很多的图像区域
CASCADE_SCALE_IMAGE=2, 正常比例检测
CASCADE_FIND_BIGGEST_OBJECT=4, 只检测最大的物体
CASCADE_DO_ROUGH_SEARCH=8 初略的检测
6. minObjectSize maxObjectSize:匹配物体的大小范围
参数6、7:minSize和maxSize用来限制得到的目标区域的范围。也就是我本次训练得到实际项目尺寸大小 函数介绍:detectMultiscale函数为多尺度多目标检测:多尺度:通常搜索目标的模板尺寸大小是固定的,但是不同图片大小不同,所以目标对象的大小也是不定的,所以多尺度即不断缩放图片大小(缩放到与模板匹配),通过模板滑动窗函数搜索匹配;同一副图片可能在不同尺度下都得到匹配值,所以多尺度检测函数detectMultiscale是多尺度合并的结果。多目标:通过检测符合模板匹配对象,可得到多个目标,均输出到objects向量里面。
minNeighbors=3:匹配成功所需要的周围矩形框的数目,每一个特征匹配到的区域都是一个矩形框,只有多个矩形框同时存在的时候,才认为是匹配成功,比如人脸,这个默认值是3。返回搜狐,查看更多
责任编辑:

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)