
yolov3(ultralytics cfg版-v5-v8 / yml版v9) 训练、检测、可视化
https://github.com/ultralytics/yolov3YOLOv5GPU 速度使用批大小为 32 的 V100 GPU 测量每张图像的端到端时间平均超过 5000 张 COCO val2017 图像,包括图像预处理、PyTorch FP16 推理、后处理和 NMS。EfficientDet 数据来自google/automl,批量大小为 8。重现通过python test.py
https://github.com/ultralytics/yolov3
源码使用的是COCO数据集训练的。
官方详细:https://github.com/ultralytics/yolov3/wiki/Train-Custom-Data
该库的数据集格式既不是VOC2007格式也不是MS COCO的格式,而是一种新的格式,YOLO格式
COCO(2014/17)格式->YOLO格式
下载
http://images.cocodataset.org/zips/train2014.zip
http://images.cocodataset.org/zips/val2014.zip
https://pjreddie.com/media/files/coco/labels.tgz
https://pjreddie.com/media/files/coco/5k.part
https://pjreddie.com/media/files/coco/trainvalno5k.part
将两个.part文件后缀修改为txt,然后按照如下格式来放(注意两个shapes文件是后来生成的)。coco目录,需要调整data/coco2014.data文件中的路径。理论上,COCO数据集和权重文件,都可以通过运行getxxxx.sh文件自动获得,但是一个是国内要翻墙.
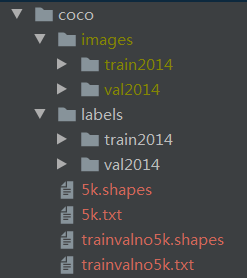
coco2014.data:
classes=80
train=../coco/trainvalno5k.txt
valid=../coco/5k.txt
names=data/coco.names
下载预训练权重文件(这个有很多种,和cfg目录下的配置文件一一对应的
注意,代码中默认是使用的yolov3-spp的这个。
https://pjreddie.com/media/files/yolov3-tiny.weights
https://pjreddie.com/media/files/yolov3-spp.weights
通过研究ultralytics在utils/google_utils.py里的代码,发现也可以直接去下载如下的权重文件。
注意,这里ultralytics的代码里是写的v1.0,据说有个v9.0是为了能和yolov5匹配的最新版本,选择哪个自己决定吧。
如果在这里直接下载的pt文件,就可以跳过 转换权重文件
(另外,如果你直接运行detect.py,也会自动去帮你下载对应的pt文件)
https://github.com/ultralytics/yolov3/releases/download/v1.0/yolov3.pt
https://github.com/ultralytics/yolov3/releases/download/v1.0/yolov3-tiny.pt
https://github.com/ultralytics/yolov3/releases/download/v1.0/yolov3-spp.pt
转换权重文件
下载的权重文件是darknet格式的,需要手工转换成.pt的pytorch格式。当然,也可以直接去网上搜索yolov3-spp-ultralytics.pt这个文件,不过大多需要积分下载。
源代码中在models.py里提供了一个convert函数,可以将weights文件转换成pt文件。
转换好的pt文件,修改名称为yolov3-spp-ultralytics.pt后,放到weights目录下去。
训练
1、下载coco数据集
首先,现在真的没有必要使用coco2014了,直接上coco2017吧。根据scripts/get_coco.sh中指明的下载路径和解压路径,去下载和解压train2017.zip等文件。如果你自行下载,放置的位置不同,需要修改yml配置文件。
https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels.zip
http://images.cocodataset.org/zips/train2017.zip
http://images.cocodataset.org/zips/val2017.zip
http://images.cocodataset.org/zips/test2017.zip
1、修改配置文件
老版本的yolov3有一个cfg目录,下面是cfg的配置。不过最新的版本v9在data目录下放置yml文件作为配置,我们按照最新的来说。
在train.py中,默认使用的coco128.yml,这个coco128是一个小型的数据集,是从coco中取的前128张图片组成的。
如果是按照默认的位置下载的,会自动解压到正确的位置,手工下载的请按照coco.yml或者coco128.yml配置文件的配置路径放置文件。
需要放置在其他地方的,则修改coco.yml或者coco128.yml文件里的配置。
2、修改train.py文件
源代码默认是使用的coco128数据集,这里需要注意权重文件的位置,使用的数据集文件位置。

VOC2007格式->YOLO格式
训练报错(写在最前):
YOLOv3编译错误:AssertionError:No labels found in data/VOC2007/JPEGImages/
问题分析:image替换为labels时出错,数据集中用的是JPEGImages不是images
 方法1:上述代码,修改datasets.py中images 为JPEGImages即可
方法1:上述代码,修改datasets.py中images 为JPEGImages即可
方法2:在后面的数据集搭建中,将JPEGImages文件夹名字,替换为images文件夹
VOC2007格式
-data
- VOCdevkit
- VOC2007
- Annotations (标签XML文件,用对应的图片处理工具LabelImg人工生成的)
- ImageSets (生成的方法是用sh或者MATLAB语言生成)
- Main
- test.txt
- train.txt
- trainval.txt
- val.txt
- JPEGImages(原始文件)
- labels (xml文件对应的txt文件)
Main文件夹中4个txt文件生成,python脚本:
import os
import random
trainval_percent = 0.9
train_percent = 1.0
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
生成labels文件夹中的txt文件,voc_label.py文件:

# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
sets = ['train', 'val', 'test']
# classes = ["a", "b"] # 改成自己的类别
classes = ["aeroplane", 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # class names
abs_path = os.getcwd()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open(abs_path + '/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open(abs_path + '/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
for image_set in sets:
if not os.path.exists(abs_path + '/labels/'):
os.makedirs(abs_path + '/labels/')
image_ids = open(abs_path + '/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open(abs_path + '/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/JPEGImages/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
OK,VOC格式数据集构造完毕,But,继续构造YOLO格式的数据集。
需要说明:如果打算使用coco评价标准,需要构造coco中json格式,如果要求不高,只需要VOC格式即可,使用作者写的mAP计算程序即可。
创建自己的data/*.names文件
保存的是你训练数据的所有类别,每行一个类别,如data/coco.names:
person
bicycle
car
...
voc2007(20类):
aeroplane
bicycle
bird
boat
bottle
bus
car
cat
chair
cow
diningtable
dog
horse
motorbike
person
pottedplant
sheep
sofa
train
tvmonitor
创建自己的data/*.data,其中保存很多配置信息
classes = 1 # 改成你的数据集的类别个数
train = ./data/2007_train.txt # 通过voc_label.py文件生成的txt文件
valid = ./data/2007_test.txt # 通过voc_label.py文件生成的txt文件
names = data/voc2007.names # 记录类别
# backup = backup/ # 在本库中没有用到
# eval = coco # 选择map计算方式(v5v6版本有))
修改yolov3.cfg,或者自建(推荐)一个yolov3-voc2007.cfg文件,类别信息
只需要更改每个[yolo]层前边卷积层的filter个数即可:
每一个[region/yolo]层前的最后一个卷积层中的 filters=预测框的个数(mask对应的个数,比如mask=0,1,2, 代表使用了anchors中的前三对,这里预测框个数就应该是3*(classes+5) ,5的意义是5个坐标(论文中的tx,ty,tw,th,po),3的意义就是用了3个anchor。
举个例子:假如我有三个类,n = 20, 那么filter = 3 × (n+5) = 75
[convolutional]
size=1
stride=1
pad=1
filters=255 # 改为 75
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80 # 改为 20
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
VOC2007-YOLO数据集格式解析
- yolov3
- data
- 2007_train.txt
- 2007_test.txt
- voc2007.names
- voc2007.data
- annotations(json files)
- images(将2007_train.txt中的图片放到train2014文件夹中,test同理)
- train2014
- 0001.jpg
- 0002.jpg
- val2014
- 0003.jpg
- 0004.jpg
- labels(voc_labels.py生成的内容需要重新组织一下)
- train2014
- 0001.txt
- 0002.txt
- val2014
- 0003.txt
- 0004.txt
- samples(存放待测试图片)
2007_train.txt内容示例:
/home/dpj/yolov3-master/data/images/val2014/Cow_1192.jpg
/home/dpj/yolov3-master/data/images/val2014/Cow_1196.jpg
.....
注意images和labels文件架构一致性(对应前面的报错),因为txt是通过简单的替换得到的:
images -> labels
.jpg -> .txt
具体内容可以在datasets.py文件中找到详细的替换。
训练
下载预训练模型:
Darknet *.weights :
https://pjreddie.com/media/files/yolov3.weights
https://pjreddie.com/media/files/yolov3-tiny.weights
https://pjreddie.com/media/files/yolov3-spp.weights
PyTorch *.pt :
https://drive.google.com/drive/folders/1uxgUBemJVw9wZsdpboYbzUN4bcRhsuAI
前三个Darknet权重好下载(v6版本以下应该是用的该权重进行训练),v7以后需要PyTorch权重训练,通过models.py里面的convert函数将Darknet权重转换成PyTorch权重。
python train.py --cfg cfg/yolov3.cfg --data data/coco.data
(我的)python train.py --cfg cfg/yolov3-voc2007.cfg --data my_data/VOC2007/voc2007.data --epochs 300 --batch-size 16
如果中断了,可以恢复训练
python train.py --data data/coco.data --cfg cfg/yolov3.cfg --resume
测试/检测
图片在data/samples中
python detect.py --cfg cfg/yolov3.cfg --weights weights/best.pt
Image: --source file.jpg
Video: --source file.mp4
Directory: --source dir/
Webcam: --source 0
RTSP stream: --source rtsp://170.93.143.139/rtplive/470011e600ef003a004ee33696235daa
HTTP stream: --source http://wmccpinetop.axiscam.net/mjpg/video.mjpg
评估模型
python test.py --weights weights/best.pt
如果使用cocoAPI使用以下命令:
$ python3 test.py --img-size 608 --iou-thr 0.6 --weights ultralytics68.pt --cfg yolov3-spp.cfg
Namespace(batch_size=32, cfg='yolov3-spp.cfg', conf_thres=0.001, data='data/coco2014.data', device='', img_size=608, iou_thres=0.6, save_json=True, task='test', weights='ultralytics68.pt')
Using CUDA device0 _CudaDeviceProperties(name='Tesla V100-SXM2-16GB', total_memory=16130MB)
Class Images Targets P R mAP@0.5 F1: 100% 157/157 [03:30<00:00, 1.16it/s]
all 5e+03 3.51e+04 0.0353 0.891 0.606 0.0673
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.409
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.615
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.437
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.242
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.448
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.519
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.337
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.557
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.612
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.438
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.658
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.746
mAP计算
mAP@0.5 run at --iou-thr 0.5, mAP@0.5…0.95 run at --iou-thr 0.7
可视化
可以使用python -c from utils import utils;utils.plot_results()
创建drawLog.py
def plot_results():
# Plot YOLO training results file 'results.txt'
import glob
import numpy as np
import matplotlib.pyplot as plt
#import os; os.system('rm -rf results.txt && wget https://storage.googleapis.com/ultralytics/results_v1_0.txt')
plt.figure(figsize=(16, 8))
s = ['X', 'Y', 'Width', 'Height', 'Objectness', 'Classification', 'Total Loss', 'Precision', 'Recall', 'mAP']
files = sorted(glob.glob('results.txt'))
for f in files:
results = np.loadtxt(f, usecols=[2, 3, 4, 5, 6, 7, 8, 17, 18, 16]).T # column 16 is mAP
n = results.shape[1]
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.plot(range(1, n), results[i, 1:], marker='.', label=f)
plt.title(s[i])
if i == 0:
plt.legend()
plt.savefig('./plot.png')
if __name__ == "__main__":
plot_results()

跑了50epoch,保存输出结果,results.png:

和tensorboard --logdir=runs显示的一致。
python detect.py --cfg cfg/yolov3-voc2007.cfg --weights weights/best.pt
数据集配套代码
如果你看到这里了,恭喜你,你可以避开以上略显复杂的数据处理。我们提供了一套代码,集成了以上脚本,只需要你有jpg图片和对应的xml文件,就可以直接生成符合要求的数据集,然后按照要求修改一些代码即可。
代码地址:https://github.com/pprp/voc2007_for_yolo_torch
请按照readme中进行处理就可以得到数据集。
推荐:
【从零开始学习YOLOv3】
https://blog.csdn.net/dd_pp_jj/category_9682353.html
https://blog.csdn.net/itsgoodtobebad/article/details/107377029

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)