
Kafka Connect 核心API—— mysql 数据同步
Kafka Connect 核心API—— mysql 数据同步kafka connect简介它是开源 Apache Kafka 的一个组件。Kafka Connect 是一个框架,用于将 Kafka 与外部系统(例如数据库、键值存储、搜索索引和文件系统)可扩展且可靠地连接起来。1、什么是kafka connect?Kafka Connect是一种用于在Kafka和其他系统之间可扩展的、可靠的流式
Kafka Connect 核心API—— mysql 数据同步
kafka connect简介
它是开源 Apache Kafka 的一个组件。Kafka Connect 是一个框架,用于将 Kafka 与外部系统(例如数据库、键值存储、搜索索引和文件系统)可扩展且可靠地连接起来。
1、什么是kafka connect?
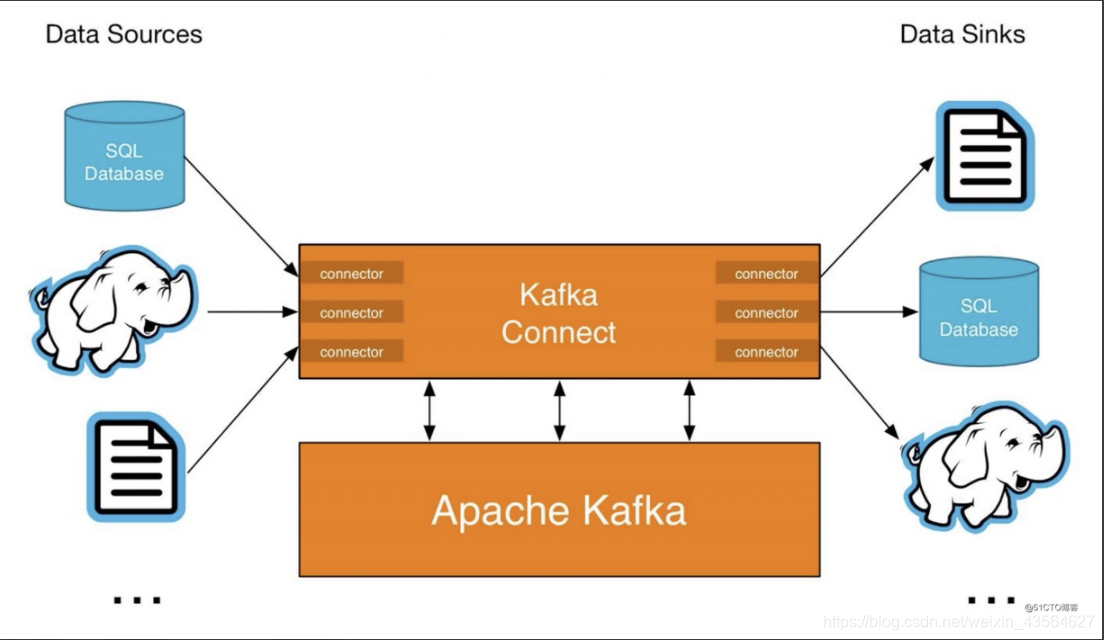
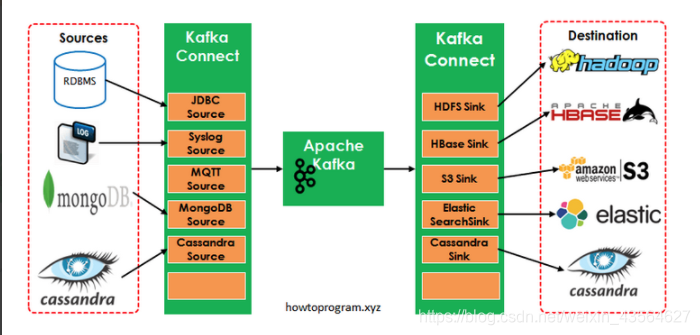
Kafka Connect是一种用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具。它使得能够快速定义将大量数据集合移入和移出Kafka的连接器变得简单。 Kafka Connect可以获取整个数据库或从所有应用程序服务器收集指标到Kafka主题,
使数据可用于低延迟的流处理。导出作业可以将数据从Kafka topic传输到二次存储和查询系统,或者传递到批处理系统以进行离线分析。 Kafka Connect功能包括:
Kafka connector通用框架,提供统一的集成API
同时支持分布式模式和单机模式
REST 接口,用来查看和管理Kafka connectors
自动化的offset管理,开发人员不必担心错误处理的影响
分布式、可扩展
流/批处理集成
KafkaCnnect有两个核心概念:Source和Sink。 Source负责导入数据到Kafka,Sink负责从Kafka导出数据,它们都被称为Connector。
2、kafka connect概念。
Kafka Connect关键词:
Connectors:通过管理task来协调数据流的高级抽象
Tasks:如何将数据复制到Kafka或从Kafka复制数据的实现
Workers:执行Connector和Task的运行进程
Converters: 用于在Connect和外部系统发送或接收数据之间转换数据的代码
Transforms:更改由连接器生成或发送到连接器的每个消息的简单逻辑
1) Connectors:
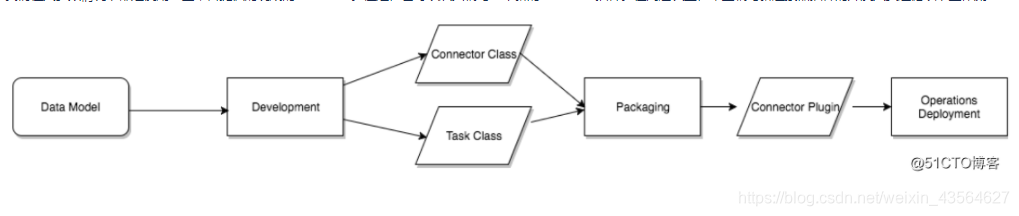
Kafka Connect中的connector定义了数据应该从哪里复制到哪里。connector实例是一种逻辑作业,负责管理Kafka与另一个系统之间的数据复制。
我们在大多数情况下都是使用一些平台提供的现成的connector。但是,也可以从头编写一个新的connector插件。在高层次上,希望编写新连接器插件的开发人员遵循以下工作流:
2) Tasks:
Task是Connect数据模型中的主要处理数据的角色,也就是真正干活的。每个connector实例协调一组实际复制数据的task。通过允许connector将单个作业分解为多个task,Kafka Connect提供了内置的对并行性和可伸缩数据复制的支持,只需很少的配置。
这些任务没有存储任何状态。任务状态存储在Kafka中的特殊主题config.storage.topic和status.storage.topic中。因此,可以在任何时候启动、停止或重新启动任务,以提供弹性的、可伸缩的数据管道。
3) Workers:
Workers
Workers是负责管理和执行connector和task的,Workers有两种模式,Standalone(单机)和Distributed(分布式)。
Standalone Workers:Standalone模式是最简单的模式,用单一进程负责执行所有connector和task
Distributed Workers:
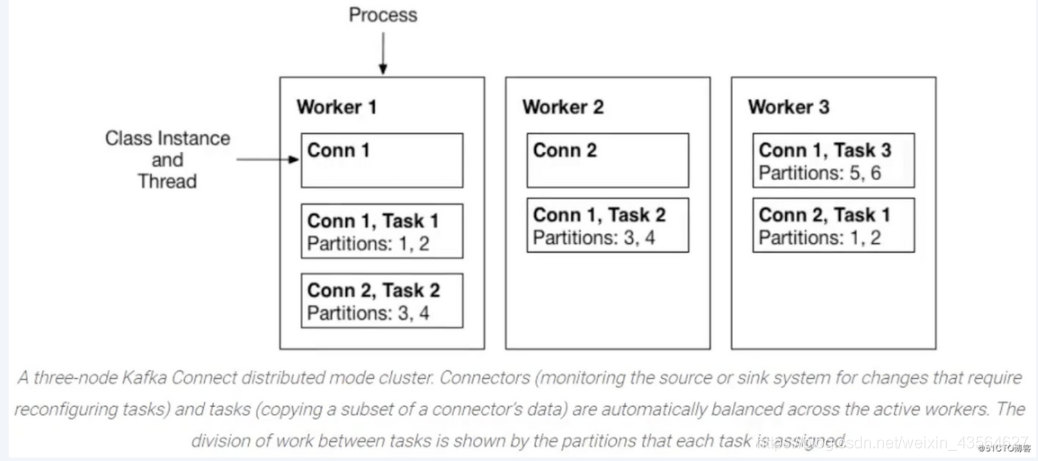
Distributed模式为Kafka Connect提供了可扩展性和自动容错能力。在分布式模式下,你可以使用相同的组启动许多worker进程。它们自动协调以跨所有可用的worker调度connector和task的执行。
如果你添加一个worker、关闭一个worker或某个worker意外失败,那么其余的worker将检测到这一点,并自动协调,在可用的worker集重新分发connector和task。
Task Rebalance
当connector首次提交到集群时,workers会重新平衡集群中的所有connector及其tasks,以便每个worker的工作量大致相同。当connector增加或减少它们所需的task数量,或者更改connector的配置时,也会使用相同的重新平衡过程。
当一个worker失败时,task在活动的worker之间重新平衡。当一个task失败时,不会触发再平衡,因为task失败被认为是一个例外情况。因此,失败的task不会被框架自动重新启动,应该通过REST API重新启动。
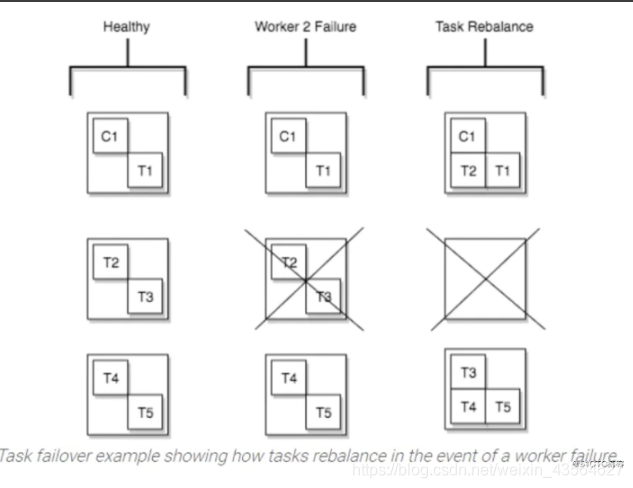
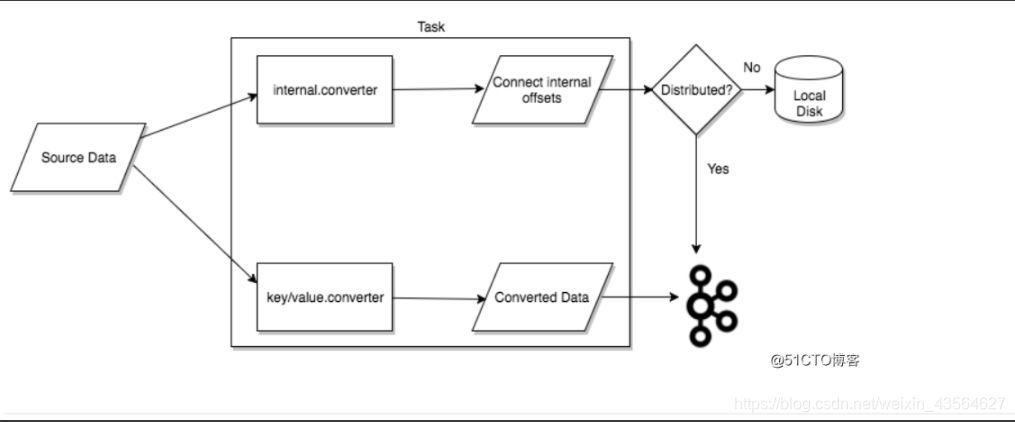
4) Converters:
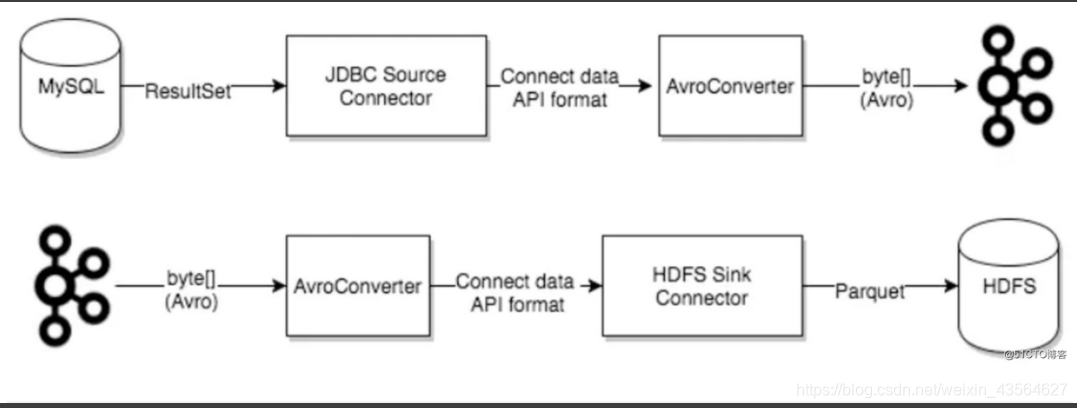
在向Kafka写入或从Kafka读取数据时,Converter是使Kafka Connect支持特定数据格式所必需的。task使用Converters将数据格式从字节转换为连接内部数据格式,反之亦然。并且Converter与Connector本身是解耦的,以便在Connector之间自然地重用Converter。
默认提供以下Converters:
AvroConverter(建议):与Schema Registry一起使用
JsonConverter:适合结构数据
StringConverter:简单的字符串格式
ByteArrayConverter:提供不进行转换的“传递”选项
AvroConverter处理数据的流程图:
5)Transforms
Connector可以配置Transforms,以便对单个消息进行简单且轻量的修改。这对于小数据的调整和事件路由十分方便,且可以在connector配置中将多个Transforms连接在一起。然而,应用于多个消息的更复杂的Transforms最好使用KSQL和Kafka Stream来实现。
Transforms是一个简单的函数,输入一条记录,并输出一条修改过的记录。Kafka Connect提供许多Transforms,它们都执行简单但有用的修改。可以使用自己的逻辑定制实现转换接口,将它们打包为Kafka Connect插件,将它们与connector一起使用。
当Transforms与Source Connector一起使用时,Kafka Connect通过第一个Transforms传递connector生成的每条源记录,第一个Transforms对其进行修改并输出一个新的源记录。将更新后的源记录传递到链中的下一个Transforms,该Transforms再生成一个新的修改后的源记录。最后更新的源记录会被转换为二进制格式写入到Kafka。Transforms也可以与Sink Connector一起使用。
以下为Confluent平台提供的Transforms:
https://docs.confluent.io/current/connect/transforms/index.html
Kakfa Connect环境准备
单机安装
确保 zookeeper 和kafka 启动成功
在演示Kakfa Connect的使用之前我们需要先做一些准备,因为依赖一些额外的集成。例如在本文中使用MySQL作为数据源的输入和输出,所以首先得在MySQL中创建两张表(作为Data Source和Data Sink)。建表SQL如下:
CREATE TABLE `users_input` (
`uid` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`uid`)
) ENGINE=InnoDB AUTO_INCREMENT=35 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `users_output` (
`uid` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`uid`)
) ENGINE=InnoDB AUTO_INCREMENT=91 DEFAULT CHARSET=utf8mb4;
接下来就是考虑怎么实现Kafka Connect了,前面有提到过Kafka Connect中的connector定义了数据应该从哪里复制到哪里。connector实例是一种逻辑作业,负责管理Kafka与另一个系统之间的数据复制。
因此,如果要自己实现一个Connect的话还是稍微有些复杂的,好在Confluent平台有些现成的Connect。例如Confluent平台就有JDBC的Connect,
下载地址如下:
https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
我们需要到Kafka Server上进行相应的配置才能使用该Connect,所以复制下载链接到服务器上使用wget命令进行下载:
wget https://d1i4a15mxbxib1.cloudfront.net/api/plugins/confluentinc/kafka-connect-jdbc/versions/5.5.0/confluentinc-kafka-connect-jdbc-5.5.0.zip
除此之外,由于要连接MySQL,所以还得去maven仓库上复制mysql-connector驱动包的下载链接,然后使用同样命令进行下载:
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.20/mysql-connector-java-8.0.20.jar
解压下载好的Connect压缩包,创建一个存放目录,将解压后的文件移到到该目录下,并将MySQL驱动包移动到kafka-connect-jdbc的lib目录下:
/service/software/debezium/kafka_2.13-2.5.0/plugins/confluentinc-kafka-connect-jdbc-5.5.0
 Connect包准备好后,编辑 kafka config 目录下的 connect-distributed.properties配置文件,修改如下配置项:
Connect包准备好后,编辑 kafka config 目录下的 connect-distributed.properties配置文件,修改如下配置项:
# Broker Server的访问ip和端口号
bootstrap.servers=172.21.0.10:9092
# 指定集群id
group.id=connect-cluster
# 指定rest服务的端口号
rest.port=8083
# 指定Connect插件包的存放路径
plugin.path=/opt/kafka/plugins
完成前面的步骤后,我们就可以启动Kafka Connect了。有两种启动方式,分别是:前台启动和后台启动,前者用于开发调试,后者则通常用于正式环境。具体命令如下:
# 前台启动
./connect-distributed.sh /service/software/debezium/kafka_2.13-2.5.0/config/connect-distributed.properties
# 后台启动
./connect-distributed.sh -daemon /service/software/debezium/kafka_2.13-2.5.0/config/connect-distributed.properties
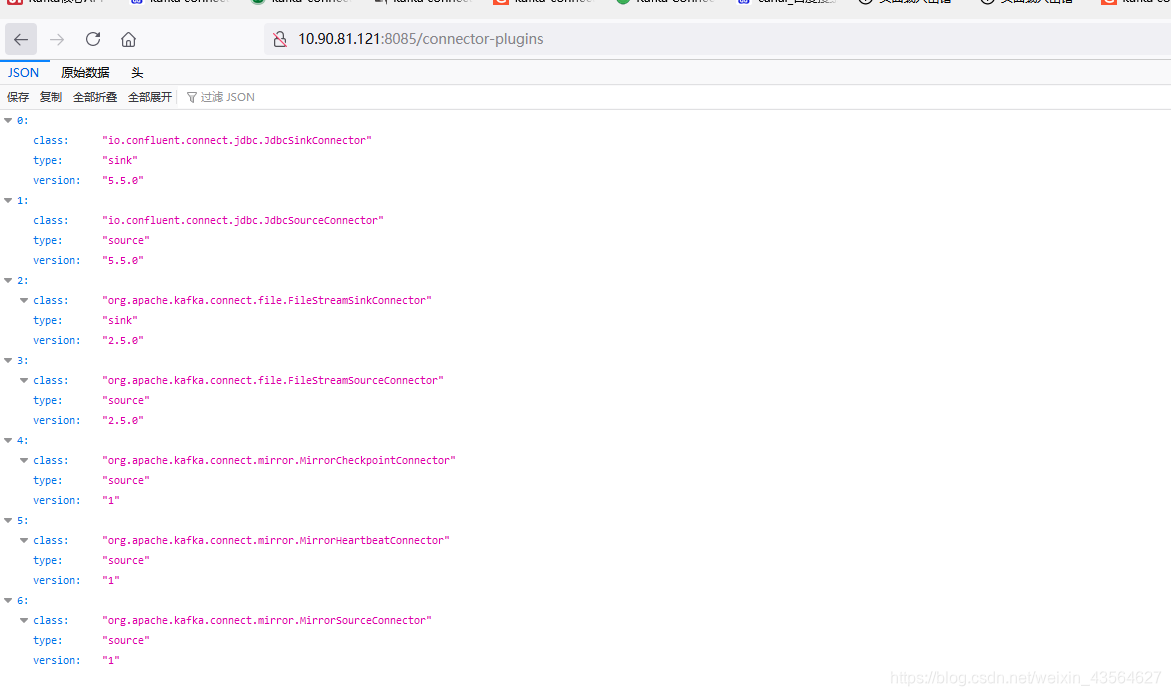
启动成功后,使用浏览器访问http://{ip}:8083/connector-plugins,正常情况下会返回这样一段JSON数据:
Kafka Connect Source和MySQL集成
首先我们要知道rest服务提供了一些API去操作connector,如下表:

这里接口测试工具 我用的 是 postman
使用浏览器访问http://{ip}:8083/connectors,可以查看所有的connector,此时返回的是一个空数组,说明没有任何的connector:
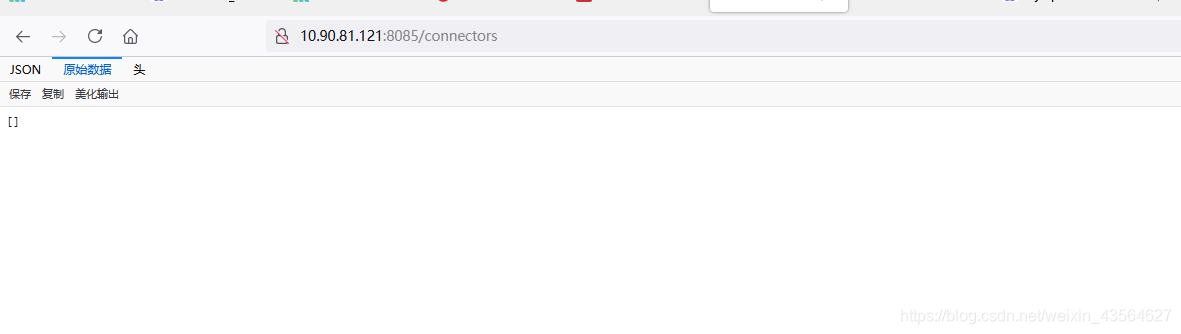
此时我们可以使用POST方式请求/connectors接口来新增一个connector,调用示例如下:
{
"name":"topic-sit-upload-mysql",
"config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mysql://10.90.81.121:3306/canal?user=root&password=123456",
"table.whitelist":"users_input",
"incrementing.column.name":"uid",
"mode":"incrementing",
"topic.prefix":"topic-sit-"
}
}
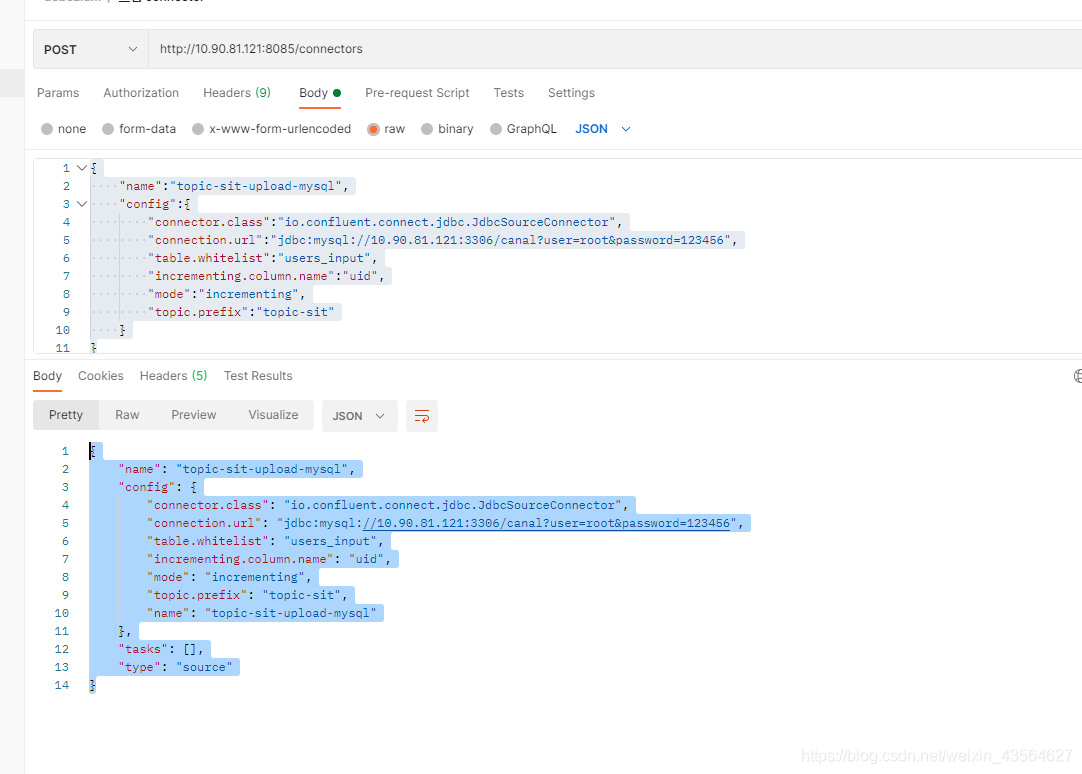
参数说明:
name:指定新增的connector的名称
config:指定该connector的配置信息
connector.class:指定使用哪个Connector类
connection.url:指定MySQL的连接url
table.whitelist:指定需要加载哪些数据表
incrementing.column.name:指定表中自增列的名称
mode:指定connector的模式,这里为增量模式
topic.prefix:Kafka会创建一个Topic,该配置项就是用于指定Topic名称的前缀,后缀为数据表的名称。例如在本例中将生成的Topic名称为:topic-sit-users_input
调用成功后,会返回如下响应数据:
{
"name": "topic-sit-upload-mysql",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://10.90.81.121:3306/canal?user=root&password=123456",
"table.whitelist": "users_input",
"incrementing.column.name": "uid",
"mode": "incrementing",
"topic.prefix": "topic-sit-",
"name": "topic-sit-upload-mysql"
},
"tasks": [],
"type": "source"
}
然后刷新浏览器页面,可以看到test-upload-mysql这个connector已经能被列出来了:
http://10.90.81.121:8085/connectors 注意: 我这里 配置配的 是 8085端口 默认的是 8083
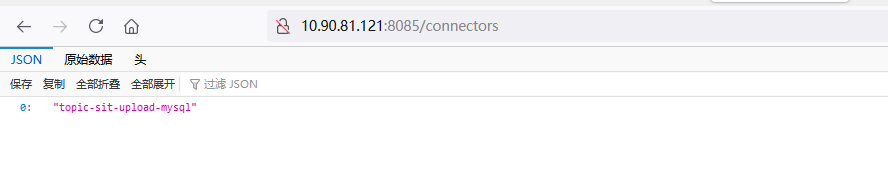
表和mysql 配置 看:Kakfa Connect环境准备
新增connector完成后,我们尝试往数据表里添加一些数据,具体的sql如下:
INSERT INTO users_input( name, age) values('小黑', 16);
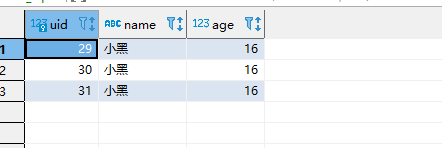
进入kafka的bin 目录执行如下命令
消费者
./kafka-console-consumer.sh --bootstrap-server 10.90.81.121:9094 --topic topic-sit-users_input --from-beginning
能拉取到这样的数据就代表已经成功将MySQL数据表中的数据传输到Kafka Connect Source里了,也就是完成输入端的工作了。
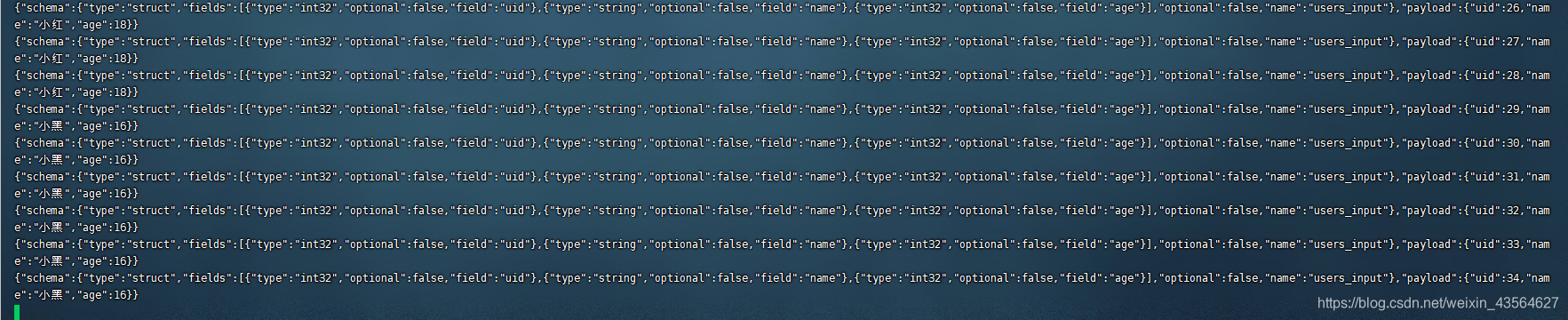
Kafka Connect Sink和MySQL集成
现在我们已经能够通过Kafka Connect将MySQL中的数据写入到Kafka中了,接下来就是完成输出端的工作,将Kafka里的数据输出到MySQL中。
首先,我们需要调用Rest API新增一个Sink类型的connector。具体请求如下:
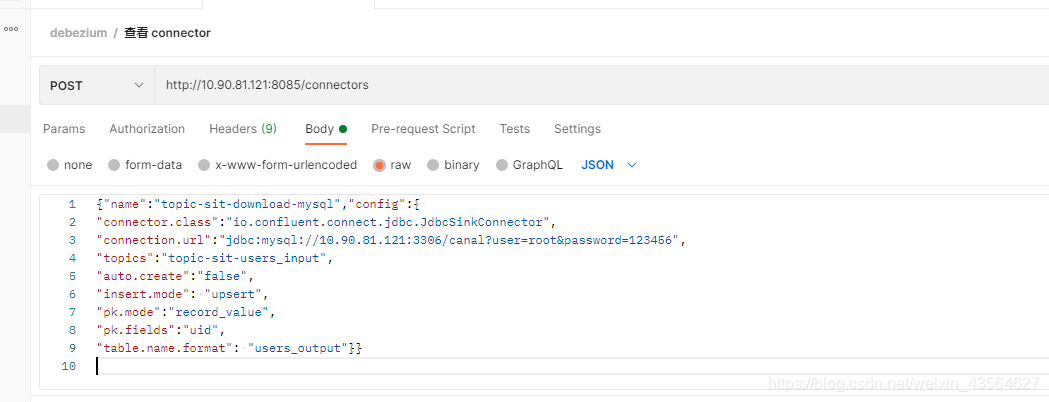
{"name":"topic-sit-download-mysql","config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://10.90.81.121:3306/canal?user=root&password=123456",
"topics":"topic-sit-users_input",
"auto.create":"false",
"insert.mode": "upsert",
"pk.mode":"record_value",
"pk.fields":"uid",
"table.name.format": "users_output"}}
参数说明:
name:指定新增的connector的名称
config:指定该connector的配置信息
connector.class:指定使用哪个Connector类
connection.url:指定MySQL的连接url
topics:指定从哪个Topic中读取数据
auto.create:是否自动创建数据表
insert.mode:指定写入模式,upsert表示可以更新及写入
pk.mode:指定主键模式,record_value表示从消息的value中获取数据
pk.fields:指定主键字段的名称
table.name.format:指定将数据输出到哪张数据表上
调用成功后,会返回如下响应数据:
{
"name": "topic-sit-download-mysql",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url": "jdbc:mysql://10.90.81.121:3306/canal?user=root&password=123456",
"topics": "topic-sit-users_input",
"auto.create": "false",
"insert.mode": "upsert",
"pk.mode": "record_value",
"pk.fields": "uid",
"table.name.format": "users_output",
"name": "topic-sit-download-mysql"
},
"tasks": [],
"type": "sink"
}
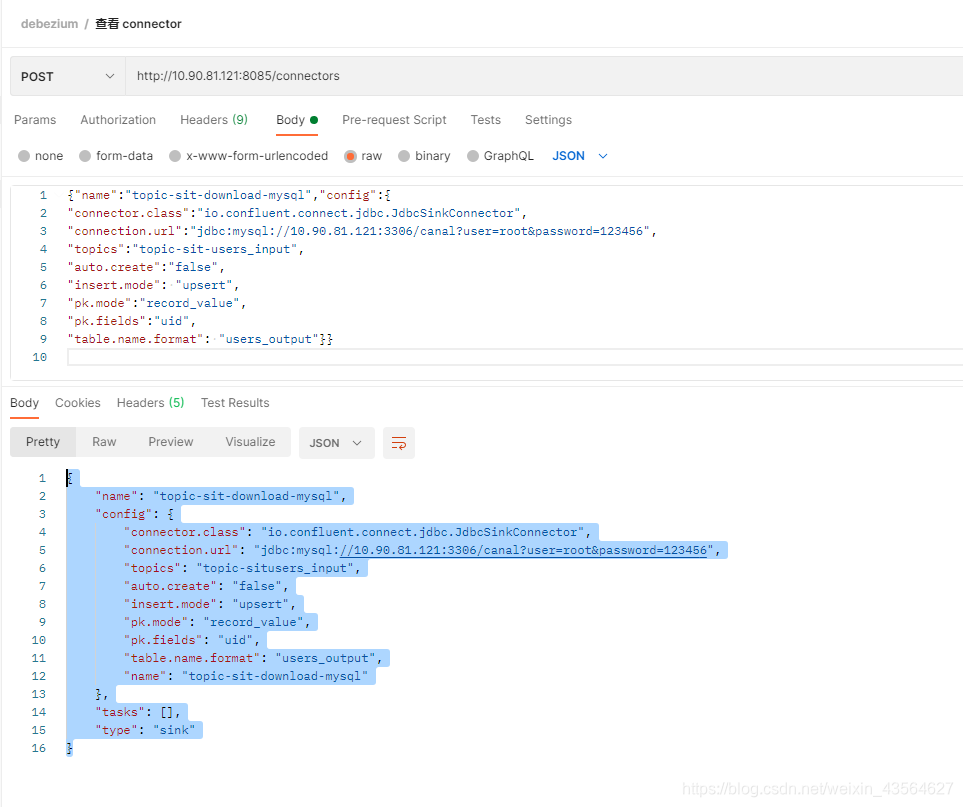
刷新浏览器页面,此时就有两个connector了:
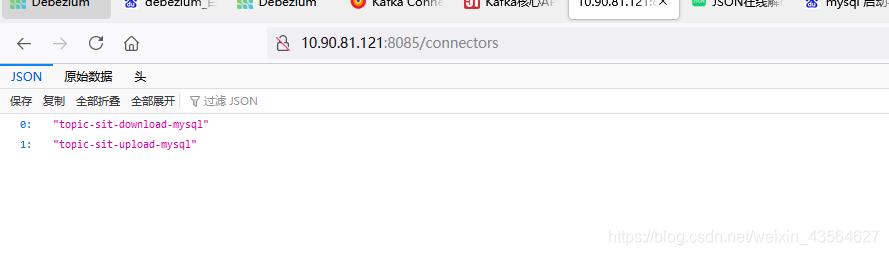 该Sink类型的connector创建完成后,就会读取Kafka里对应Topic的数据,并输出到指定的数据表中。如下:
该Sink类型的connector创建完成后,就会读取Kafka里对应Topic的数据,并输出到指定的数据表中。如下:
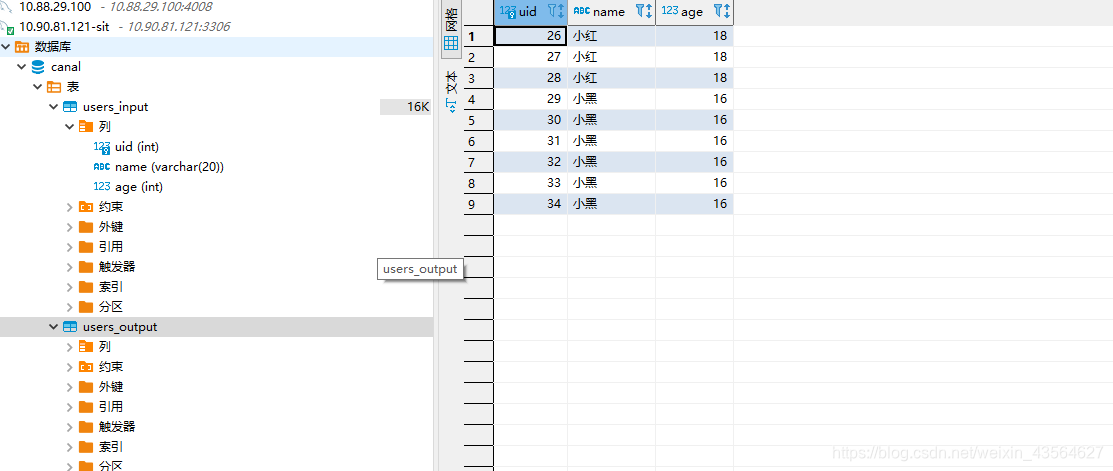
小结
回顾一下本文中的示例,可以直观的看到Kafka Connect实际上就做了两件事情:使用Source Connector从数据源(MySQL)中读取数据写入到Kafka Topic中,然后再通过Sink Connector读取Kafka Topic中的数据输出到另一端(MySQL)。
虽然本例中的Source端和Sink端都是MySQL,但是不要被此局限了,因为Source端和Sink端可以是不一样的,这也是Kafka Connect的作用所在。它就像一个倒卖数据的中间商,将Source端的数据读取出来写到自己的Topic,这就像进货一样,然后再将数据输出给Sink端。至此,就完成了一个端到端的数据同步,其实会发现与ETL过程十分类似,这也是为啥Kafka Connect可以作为实现ETL方案的原因。
问题记录
如果mysql 数据库有乱码的情况,
show variables like 'character%';
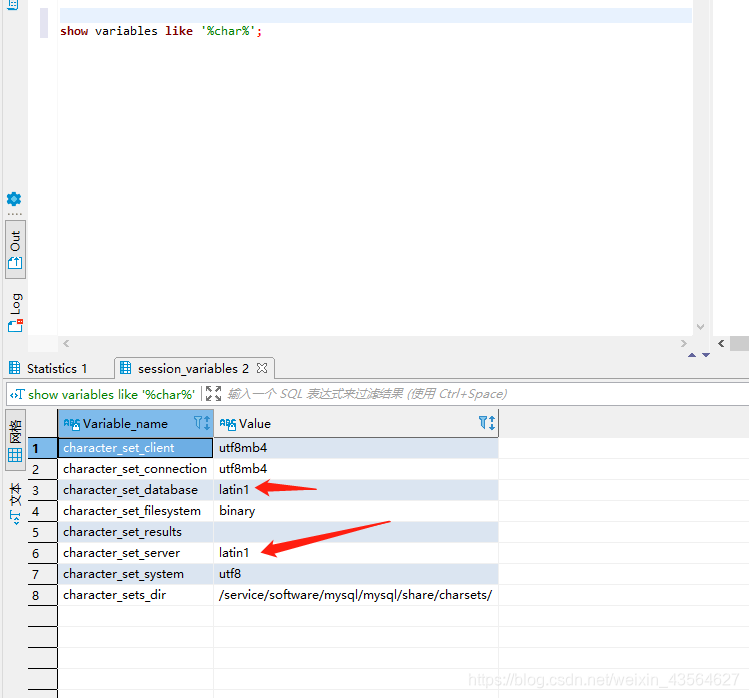
解决
修改mysql配置文件/etc/my.cnf
[mysqld]
character-set-server=utf8
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
停止mysql
service mysql stop
启动
service mysql start

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)