实现Scrapy框架爬取酷狗音乐Top100名,并存储为TXT,JSON,CSV和Excel格式数据
前言实现Scrapy框架爬取网页数据(酷狗音乐Top100名,包括排名信息、歌手信息、歌曲名、歌曲时长)一、创建项目在cmd中输入:scrapy startproject kugouScrapycd kugouScrapyscrapy genspider kugou www.kugou.com目录结构:二、编写items.pyItem 是保存爬取到的数据的容器;其使用方法和python字典类似,

前言
实现Scrapy框架爬取网页数据(酷狗音乐Top100名,包括排名信息、歌手信息、歌曲名、歌曲时长)

一、创建项目
在cmd中输入:
scrapy startproject kugouScrapy
cd kugouScrapy
scrapy genspider kugou www.kugou.com
目录结构:

二、编写items.py
Item 是保存爬取到的数据的容器;其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
网页中包含大量数据,但并不是所有数据都需要存储,否则会浪费大量服务器资源,提取网页中需要的数据时,首先需要编写items.py文件,在该文件中定义需要爬取的数据
修改items.py文件,代码如下:
import scrapy
class KugouscrapyItem(scrapy.Item):
# 定义rank存储排名信息
rank = scrapy.Field()
# 定义singer存储歌手信息
singer = scrapy.Field()
# 定义name存储歌曲名称
name = scrapy.Field()
# 定义time存储歌曲时长
time = scrapy.Field()三、编写pipelines.py
部分代码参考了别人的博客,但是我找不到原出处了,抱歉!
from itemadapter import ItemAdapter
import csv
import codecs
import json
from openpyxl import Workbook
class KugouscrapyPipeline:
def __init__(self):
# # ------------- 存储为txt格式 -------------
# self.file = open('../../data/kugou_top100.txt', 'w', encoding='utf-8')
# self.file.write('rank;singer;name;time' + '\n')
# #------------- 存储为json格式 -------------
# # 打开kugou_top100.json文件
# self.file = codecs.open('../../data/kugou_top100.json', 'w', encoding='utf-8')
# ------------- 存储为csv格式 -------------
# 打开文件,指定方式为写,利用第3个参数把csv写数据时产生的空行消除
self.file = open('../../data/kugou_top100.csv', 'w', encoding='utf-8-sig', newline='')
# 设置文件第一行的字段名,注意要跟spider传过来的字典key名称相同
self.fieldnames = ['rank', 'singer', 'name', 'time']
# 指定文件的写入方式为csv字典写入,参数1为指定具体文件,参数2为指定字段名
self.writer = csv.DictWriter(self.file, fieldnames=self.fieldnames)
# 写入第一行字段名,因为只要写入一次,所以文件放在__init__里面
self.writer.writeheader()
#
# # ------------- 存储为excel格式 -------------
# self.file = Workbook()
# self.ws = self.file.active
# self.ws.append(['rank', 'singer', 'name', 'time']) # 设置表头
def process_item(self, item, spider):
# # ------------- 存储为txt格式 -------------
# res = dict(item)
# rank = res['rank']
# singer = res['singer']
# name = res['name']
# time = res['time']
# self.file.write(
# rank + ";" + singer + ";" + name + ";" + time + ";" + '\n')
# #------------- 存储为json格式 -------------
# # dumps 将一个Python数据结构转为json
# # json.dumps 序列化时对中文默认使用的ascii编码.想输出中文需要指定ensure_ascii=False
# i = json.dumps(dict(item), ensure_ascii=False)
# # 每条数据添加后换行
# line = i + '\n'
# # 将数据写入文件
# self.file.write(line)
# ------------- 存储为csv格式 -------------
# 写入spider传过来的具体数值
self.writer.writerow(item)
# # ------------- 存储为excel格式 -------------
# line = [item['rank'], item['singer'], item['name'], item['time']] # 把数据中每一项整理出来
# self.ws.append(line) # 将数据以行的形式添加到xlsx中
# self.file.save('../../data/kugou_top100.xlsx') # 保存xlsx文件
#
return item
def close_spider(self, spider):
# 关闭文件
self.file.close()
四、修改settings.py文件
修改pipelines的配置部分
开启ITEM_PIPELINES功能使得pipelines.py文件生效
设置User-Agent伪装浏览器
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'kugouScrapy.pipelines.KugouscrapyPipeline': 300,
}为了避免服务器通过Cookie信息识别爬虫行为,需关闭本地Cookie,使得对方的服务器无法根据Cookie信息识别是否是爬虫而进行屏蔽处理,还需要设置Cookie禁用选项,代码如下:
# Disable cookies (enabled by default)
COOKIES_ENABLED = False关闭遵守爬虫协议:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # 禁用遵守爬虫协议五、编写爬虫文件(核心)
①对爬虫网页URL进行分析
网页版酷狗不能手动翻页进行下一步的浏览,通过观察不同页面的URL,发现只需要更换参数即对应不同的页面,由于每页显示的为22首歌曲,因此总共需要5个URL
②对网页信息进行提取——使用Selector选择器
import parsel
import scrapy
import requests
# from kugouScrapy.kugouScrapy.items import KugouscrapyItem
from ..items import KugouscrapyItem
class KugouSpider(scrapy.Spider):
name = 'kugou'
allowed_domains = ['www.kugou.com']
start_urls = ['https://www.kugou.com/yy/rank/home/1-8888.html?from=rank']
page = 2
count = 1
def parse(self, response):
music_list = response.selector.css('div.pc_temp_songlist li')
for item in music_list:
# 将items中定义的对象实例化
music = KugouscrapyItem()
# 在TOP1-3中,酷狗音乐将它们特殊地包在了一对strong标签下,这里我们需要特殊处理
if self.count <= 3:
music['rank'] = item.css('span.pc_temp_num strong::text').re_first('[0-9]+')
else:
music['rank'] = item.css('span.pc_temp_num::text').re_first('[0-9]+')
# 有一些音乐由于singer部分太长,无法构成'singer - name'格式,于是采用try-except,如果有爬取不到的数据,就进入链接爬取
try:
music['singer'] = ''.join(item.css('a.pc_temp_songname::text').get()).split('-')[0]
music['name'] = ''.join(item.css('a.pc_temp_songname::text').get()).split('-')[1]
except:
url = item.css('a.pc_temp_songname::attr(href)').get()
response_item = requests.get(url=url)
selector_item = parsel.Selector(response_item.text)
music['singer'] = ''.join(selector_item.css('.audioName::text').get()).split('-')[0]
music['name'] = ''.join(selector_item.css('.audioName::text').get()).split('-')[1]
print(url)
music['time'] = ''.join(item.css('span.pc_temp_time::text').get()).strip()
self.count += 1
# 因为要获取TOP100的数据,一页数据22条,无法整除,所以在写入文件时判断是否已满100
if self.count <= 101:
yield music
if self.page <= 5:
url = 'https://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(self.page))
self.page += 1
yield scrapy.Request(url=url, callback=self.parse)
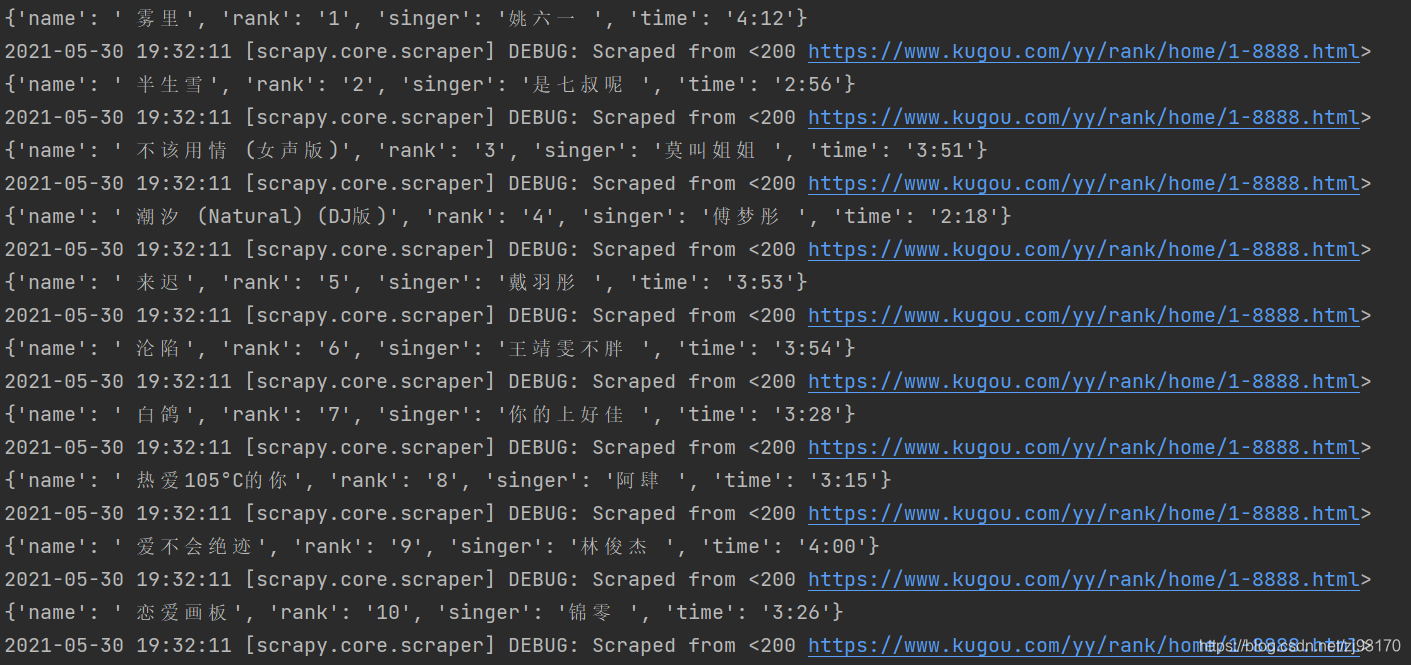
六、爬取结果
在控制台输入 scrapy crawl kugou 启动爬虫项目

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)