
Mysql中count的效率问题
点击了解 CRMEB多商户 其他开源项目源码 :了解更多小姐姐二维码一.Mysql 不同引擎count(*)的实现方式MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个 数,效率很高;而 InnoDB引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出 来,然后累积计数。二. 为什么InnoDB引擎的,不跟 MyISAM
·
记得面试中遇到问count(*)和 count(id)那个更快的问题,这里具体记录一下学习笔记,点击了解 CRMEB多商户 其他开源项目源码 :了解更多小姐姐二维码

先给结论
按照效率排序的话:count(字段) < count(主键 id) < count(1) ≈ count(*),所以尽量使用 count(*)
一. Mysql 不同引擎count(*)的实现方式
- MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个 数,效率很高;
- 而 InnoDB引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出 来,然后累积计数。
二. 为什么InnoDB引擎的,不跟 MyISAM 一样,也把数字存起来呢,为了更好理解我如下操作:
- 会话 A 先启动事务并查询一次表的总行数;
- 会话 B 启动事务,插入一行后记录后,查询表的总行数;
- 会话 C 先启动一个单独的语句,插入一行记录后,查询表的总行数。
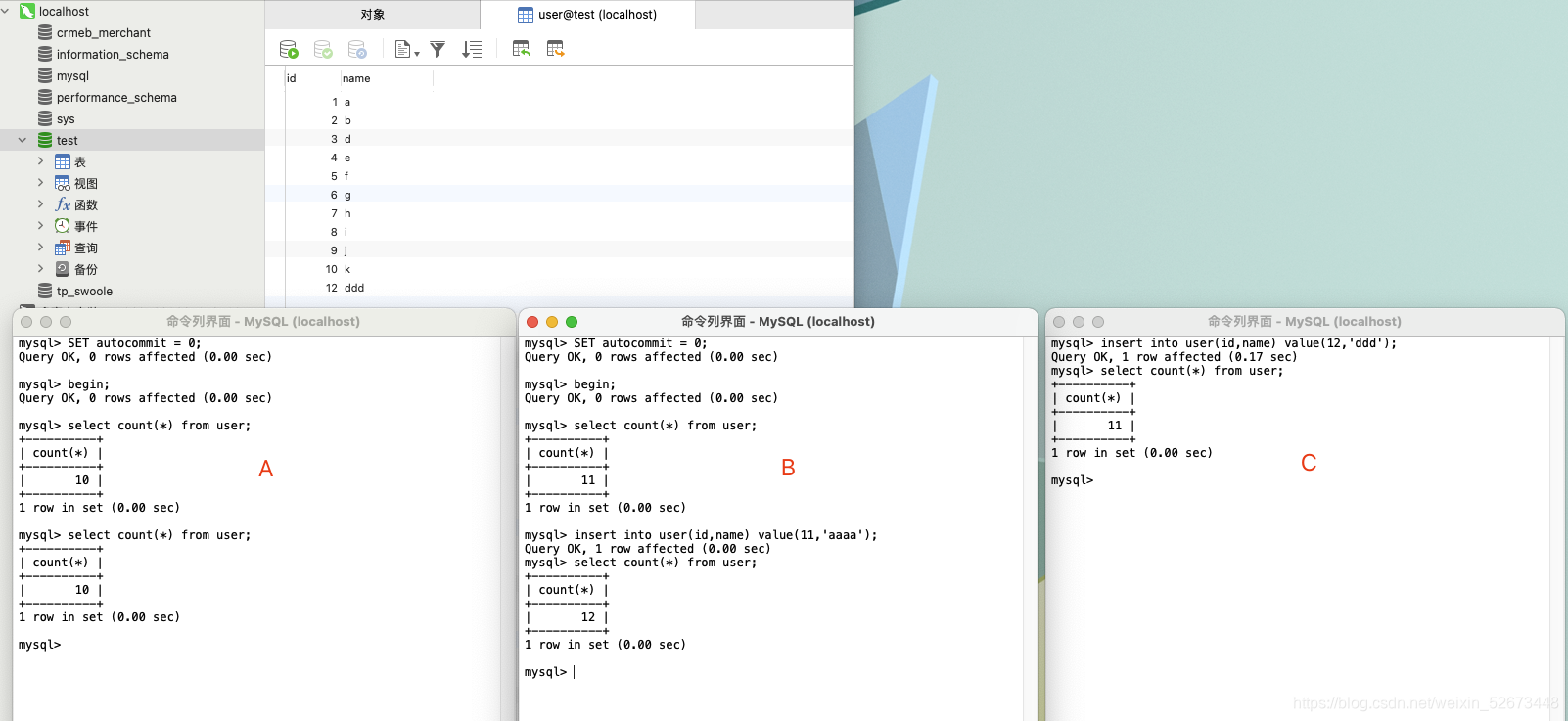
在最后一个时刻,三个会话 A、B、C 会同时查询表user 的总行数,但拿到的结果却不 同。
这和 InnoDB 的事务设计有关系,可重复读是它默认的隔离级别,在代码上就是通过多版本并 发控制,也就是 MVCC 来实现的。每一行记录都要判断自己是否对这个会话可见,因此对于count(*)请求来说,InnoDB 只好把数据一行一行地读出依次判断,可见的行才能够用于计 算“基于这个查询”的表的总行数。
三. 不同的count用法
count()是一个聚合函数,对于返回的结果集,一行行 地判断,如果 count 函数的参数不是 NULL,累计值就加1,否则不加,最后返回累计值。- 所以,
count(*)、count(主键 id)和count(1)都表示返回满足条件的结果集的总行数; - 而
count(字段),则表示返回满足条件的数据行里面,参数“字段”不为 NULL 的总个数。
count(主键 id):InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加;count(1):InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一 个数字“1”进去,判断是不可能为空的,按行累加。count(字段):如果这个“字段”是定义为 not null 的话,一行行地从记录里面读出这个字段,判断不能为 null,按行累加; 如果这个“字段”定义允许为 null,那么执行的时候,判断到有可能是 null,还要把值取出 来再判断一下,不是 null 才累加。count(*):并不会把全部字段取出来,而是专门做了优化,不取值。count(*) 肯定 不是 null,按行累加。
四. 结论
按照效率排序的话:count(字段) < count(主键 id) < count(1) ≈ count(*),所以尽量使用 count(*)。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)