
【Apache ZooKeeper】入门指南
apache ZooKeeper入门指南,环境配置。
ZooKeeper 是什么?
ZooKeeper 顾名思义 动物园管理员,他是拿来管大象(Hadoop) 、 蜜蜂(Hive) 、 小猪(Pig) 的管理员, Apache Hbase和 Apache Solr 以及LinkedIn sensei 等项目中都采用到了 Zookeeper。ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,ZooKeeper是以Fast Paxos算法为基础,实现同步服务,配置维护和命名服务等分布式应用。
Zookeeper/Hbase/Hadoop三者之间的关系,在此我把三者之间的关系画在一张图上希望能表达的清楚一些。
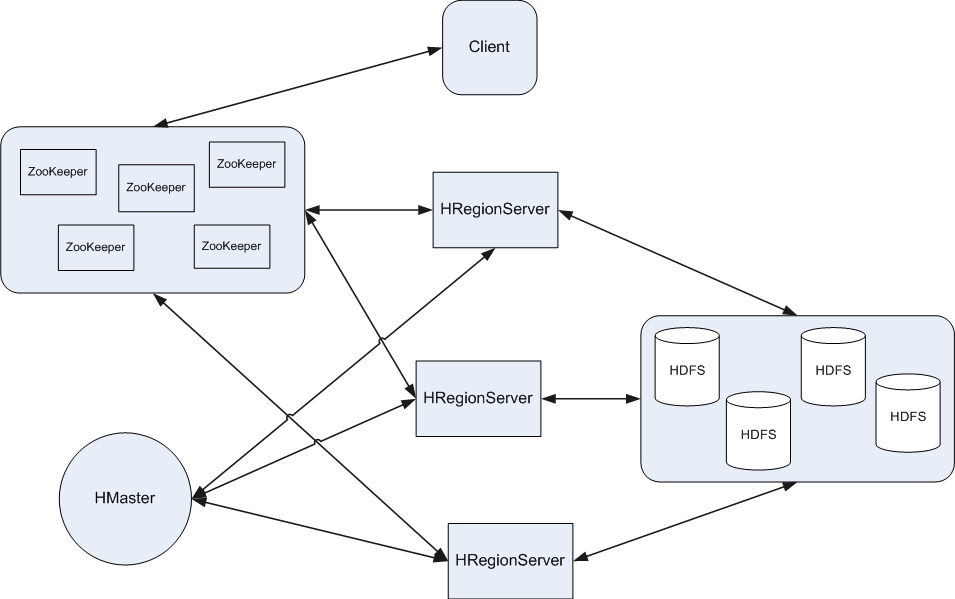
ZooKeeper 如何工作?
ZooKeeper是作为分布式应用建立更高层次的同步(synchronization)、配置管理 (configuration maintenance)、群组(groups)以及名称服务(naming)。在编程上,ZooKeeper设计很简单,所使用的数据模型风格很像文件系统的目录树结构,简单来说,有点类似windows中注册表的结构,有名称,有树节点,有Key(键)/Value(值)对的关系,可以看做一个树形结构的数据库,分布在不同的机器上做名称管理。
Zookeeper分为2个部分:服务器端和客户端,客户端只连接到整个ZooKeeper服务的某个服务器上。客户端使用并维护一个TCP连接,通过这个连接发送请求、接受响应、获取观察的事件以及发送心跳。如果这个TCP连接中断,客户端将尝试连接到另外的ZooKeeper服务器。客户端第一次连接到ZooKeeper服务时,接受这个连接的 ZooKeeper服务器会为这个客户端建立一个会话。当这个客户端连接到另外的服务器时,这个会话会被新的服务器重新建立。
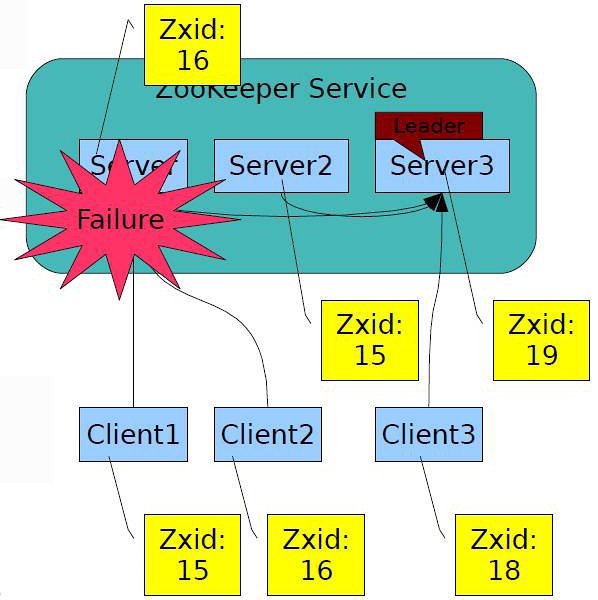
启动Zookeeper服务器集群环境后,多个Zookeeper服务器在工作前会选举出一个Leader,在接下来的工作中这个被选举出来的Leader死了,而剩下的Zookeeper服务器会知道这个Leader死掉了,在活着的Zookeeper集群中会继续选出一个Leader,选举出leader的目的是为了可以在分布式的环境中保证数据的一致性。如图所示:
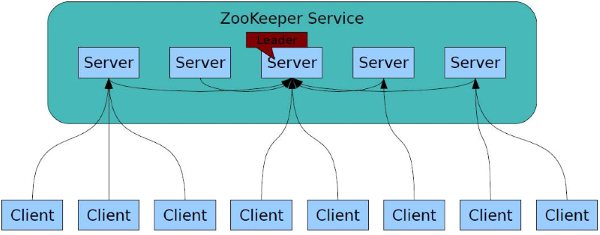
另外,ZooKeeper 支持watch(观察)的概念。客户端可以在每个znode结点上设置一个观察。如果被观察服务端的znode结点有变更,那么watch就会被触发,这个watch所属的客户端将接收到一个通知包被告知结点已经发生变化。若客户端和所连接的ZooKeeper服务器断开连接时,其他客户端也会收到一个通知,也就说一个Zookeeper服务器端可以对于多个客户端,当然也可以多个Zookeeper服务器端可以对于多个客户端,如图所示:
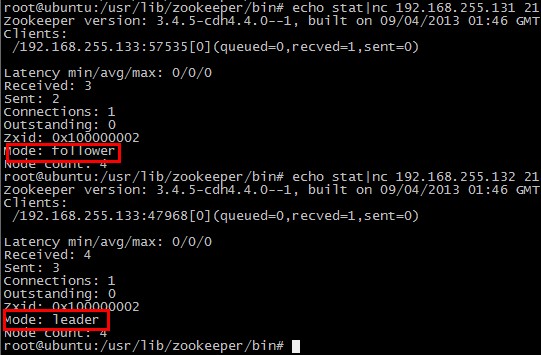
你还可以通过命令查看出,当前那个Zookeeper服务端的节点是Leader,哪个是Follower,如图所示:
Zookeeper用来同步Hbase服务状态、监控集群防止单点失效
HDFS是Hadoop中最核心的一部分,用来对Hbase的数据进行存储
1、Zookeeper客户端与服务端的大致结构
服务端
Zookeeper还是属于一个C/S的架构的应用服务,Zookeeper的服务器端分为2种运行模式:单台和集群多台的运行模式,通过conf/zoo.cfg中的配置判定你启用的运行模式,以及在群集模式中数据同步和心跳的频率等等。
Zookeeper集群中的Leader和Follower之间的选举通过Paxos算法来实现的,它是一个基于消息传递的一致性算法,这里讲述了http://zh.wikipedia.org/zh-cn/Paxos算法,传说中Paxos算法是分布式一致性算法中最有效的一种算法。
口水:在源代码中的通讯部分看见了大量采用NIO和concurrent的代码(例如:LinkedBlockingQueue/AtomicLong)。
客户端
ZooKeeper的Client由三个主要模块组成:
Zookeeper
Zookeeper是最主要的类,可以写入一个或者多个Zookeeper的服务器地址,例如:"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002" ,当你new Zookeeper( ….)的时候会有两个线程被创建:SendThread和EventThread,会在Server端创建大量的Session。
WatcherManager
在Zookeeper类中还有一个WatcherManager,用来管理Watcher的,Watcher是ZK的一大特色功能,允许多个Client对一个或多个 ZNode进行监控,当ZNode有变化时能够通知到监控这个ZNode的各个Client,管理了ZK Client绑定的所有Watcher。
ClientCnxn
在Zookeeper类中还包含了对ClientCnxn类的调用,ClientCnxn这个类管理所有对Zookeeper服务器端的网络通讯,服务端和客户端所有交互的数据都要调用这个类,包括给ZK Server发送Request,从ZK Server接受Response,以及从ZK Server接受Watcher Event。
2、服务端运行模式
服务端单机模式
zoo.cfg文件配置参数详解
# 这个时间是被用来做服务器之间或客户端与服务器心跳和最低会话超时时间的基数。
tickTime=2000
# 存储在内存中数据快照的目录。
dataDir=d:/zookeeperdata/1
# 服务器端开启的监听端口,用来接受客户端访问请求的端口。
clientPort=2181
服务端集群模式
配置参数详解
#Zookeeper服务器集群中连接到Leader与Follower 服务器少次心跳时间间隔数,以及最大通讯的超时时间,总时间为 5(initLimit)*2000(tickTime)=10 秒。
initLimit=5
#Leader与Follower间请求/应答时间长度,这里总时间长度就是 2(syncLimit)*2000(tickTime)=4 秒。
syncLimit=2
#server是固定配置,1和2表示这个是第几号服务器,2888:3888表示服务器与集群中的 Leader 服务器的通讯端口。
server.1=192.168.1.1:2888:3888
server.2=192.168.1.2:2888:3888
另外,集群模式下还要在 dataDir 目录下创建一个myid文件,这个文件中写入的内容就是一个数字,这个数字就是和server.x中的x这个数字对应,Zookeeper 启动时会读取这个文件判定自己是谁,myid文件的编码格式是ANSI。
在虚拟机192.168.255.131/132上安装了ZooKeeper
apt-get方式失败,从133机器上copy安装包过去,直接安装,先安装bigtop
/var/cache/apt/archives/bigtop-utils_0.6.0+140-1.cdh4.4.0.p0.24~precise-cdh4.4.0_all.deb
/var/cache/apt/archives/zookeeper-server_3.4.5+23-1.cdh4.4.0.p0.24~precise-cdh4.4.0_all.deb
/var/cache/apt/archives/zookeeper_3.4.5+23-1.cdh4.4.0.p0.24~precise-cdh4.4.0_all.deb
重新配置了集群,myid必须在1和255之间。
192.168.255.131 myid=1
192.168.255.132 myid=2
192.168.255.133 myid=3
三台机器都有相同的zoo.cfg文件
zoo.cfg配置文件的含义
#最大客户端连接数量
maxClientCnxns=1024
# 每次心跳的间隔时间,2000毫秒
tickTime=2000
# 初始化同步需要的最大时间10秒
initLimit=10
# 发送请求和获得确认之间的ticks数量
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/var/lib/zookeeper
# the port at which the clients will connect
clientPort=2181
# the directory where the zookeeper log is stored
dataLogDir=/var/log/zookeeper
#第一个端口给followers用来连接leader的,第二个端口用来leader选举
server.1=192.168.255.131:2888:3888
server.2=192.168.255.132:2888:3888
server.3=192.168.255.133:2888:3888
###################################################################################################
ZooKeeper跟Chubby一样用来存放一些相互协作的信息(Coordination),这些信息比较小一般不会超过1M,在zookeeper中是以一种hierarchical tree的形式来存放,这些具体的Key/Value信息就store在tree node中,这新信息很小一般不回城超过1M,当有事件导致node数据,例如:变更,增加,删除时,Zookeeper就会调用 triggerWatch方法,判断当前的path来是否有对应的监听者(watcher),如果有watcher,会触发其process方法,执行process方法中的业务逻辑,如图所示:

应用实例
ZooKeeper有了上述的这些用途,让我们设想一下,在一个分布式系统中有这这样的一个应用:
2个任务工厂(Task Factory)一主一从,如果从的发现主的死了以后,从的就开始工作,他的工作就是向下面很多台代理(Agent)发送指令,让每台代理(Agent)获得不同的账户进行分布式并行计算,而每台代理(Agent)中将分配很多帐号,如果其中一台代理(Agent)死掉了,那么这台死掉的代理上的账户就不会继续工作了。
上述,出现了3个最主要的问题:
1.Task Factory 主/从一致性的问题
2.Task Factory 主/从心跳如何用简单+稳定 或者2者折中的方式实现。
3.一台代理(Agent)死掉了以后,一部分的账户就无法继续工作,需要通知所有在线的代理(Agent)重新分配一次帐号。
怕文字阐述的不够清楚,画了系统中的Task Factory和Agent的大概系统关系,如图所示:
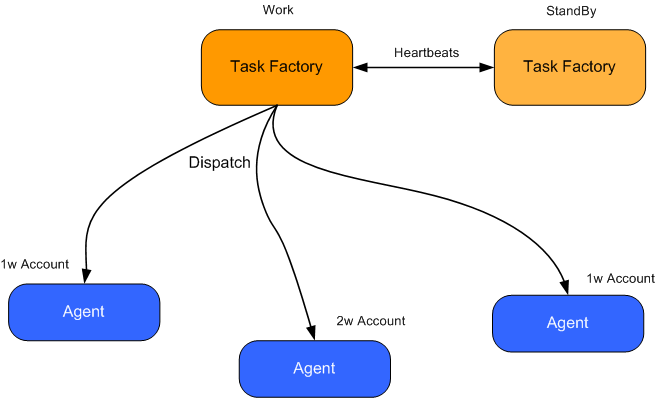
OK,让我们想想ZooKeeper是不是能帮助我们去解决目前遇到的这3个最主要的问题呢?
解决思路
1. 任务工厂Task Factory都连接到ZooKeeper上,创建节点,设置对这个节点进行监控,监控方法例如:
event= new WatchedEvent(EventType.NodeDeleted, KeeperState.SyncConnected, "/TaskFactory");
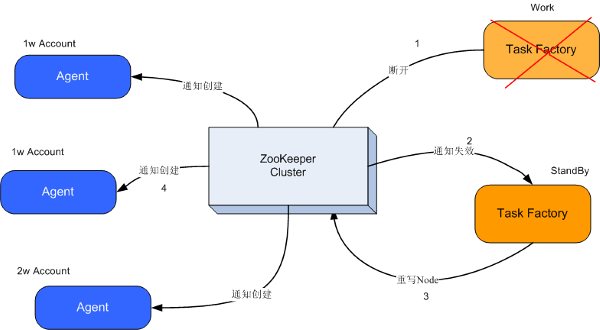
这个方法的意思就是只要Task Factory与zookeeper断开连接后,这个节点就会被自动删除。
2.原来主的任务工厂断开了TCP连接,这个被创建的/TaskFactory节点就不存在了,而且另外一个连接在上面的Task Factory可以立刻收到这个事件(Event),知道这个节点不存在了,也就是说主TaskFactory死了。
3.接下来另外一个活着的TaskFactory会再次创建/TaskFactory节点,并且写入自己的ip到znode里面,作为新的标记。
4.此时Agents也会知道主的TaskFactory不工作了,为了防止系统中大量的抛出异常,他们将会先把自己手上的事情做完,然后挂起,等待收到Zookeeper上重新创建一个/TaskFactory节点,收到 EventType.NodeCreated 类型的事件将会继续工作。
5.原来从的TaskFactory 将自己变成一个主TaskFactory,当系统管理员启动原来死掉的主的TaskFactory,世界又恢复平静了。
6.如果一台代理死掉,其他代理他们将会先把自己手上的事情做完,然后挂起,向TaskFactory发送请求,TaskFactory会重新分配(sharding)帐户到每个Agent上了,继续工作。
上述内容,大致如图所示:
参考:
http://www.javabloger.com/article/apache-zookeeper-hadoop.html
http://www.javabloger.com/article/zookeeper-hapood-apache.html

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)