
各种元启发式算法(Metaheuristics)介绍
各种元启发式算法(Metaheuristics)介绍前言一、模拟退火算法(Simulated Annealing)1.二、使用步骤1.引入库2.读入数据总结前言元启发式算法能够在一定程度上在全局进行搜索,找到最优解的近似解。元启发式算法的核心是Exploration和Exploitation。其中,Exploration即尽量探索整个搜索空间,由于最优解可能存在在整个搜索空间的任何位置。而Expl
各种元启发式算法(Metaheuristics)介绍
前言
元启发式算法能够在一定程度上在全局进行搜索,找到最优解的近似解。元启发式算法的核心是Exploration和Exploitation。其中,Exploration即尽量探索整个搜索空间,由于最优解可能存在在整个搜索空间的任何位置。而Exploitation即尽可能的利用到有效的信息,在大部分的情况下优解之间往往存在着一定的相关性,利用这些相关性来逐步调整,从初解慢慢搜索到优解。总的来说,元启发式算法希望在Exploration和Exploitation之间尽可能的平衡。接下来我们将介绍几种元启发式算法,即模拟退火算法(Simulated Annealing)、禁忌搜索算法(Tabu Search)、遗传算法(Genetic Algorithms )、进化策略(Evolution Strategies)、差分进化算法(Differential Evolution )、蚁群算法(Ant Colony Optimization )、粒子群算法(Particle Swarm Optimization )。
一、模拟退火算法(Simulated Annealing)
1.前言
退火是一种金属热处理工艺,是指将金属缓慢加热到一定温度后,保持足够的时间,然后以适宜的速度冷却。目的是为了降低硬度、稳定尺寸等。而模拟退火算法就是参照退火的过程尽量的去寻找一个函数的最优解。
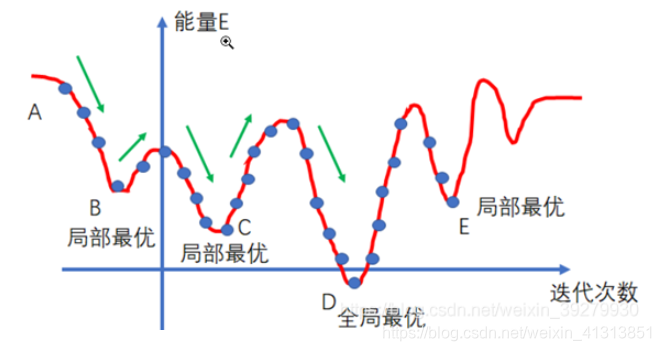
2. 爬山法
模拟退火算法实际上一定程度上参照了“爬山法”,所谓爬山法即假设存在一个函数 f ( x ) f(x) f(x),目标是在一定范围内求该函数的最大值。倘若此时存在一个旧的解 x i x_i xi,其函数值为 f ( x i ) f(x_i) f(xi),而在 x i x_i xi的附近随即找到了一个新的解 x j x_j xj,其对应的函数值为 f ( x j ) f(x_j) f(xj),如果 f ( x j ) < f ( x i ) f(x_j)<f(x_i) f(xj)<f(xi),那么即证明新的解 x j x_j xj要优于旧的解 x i x_i xi,那么就用新的解 x j x_j xj替代旧的解 x i x_i xi,否则不进行替换。原有的爬山法极其容易陷入局部最优的情况,因为在局部最优的解的附近的解都无法替换这个局部最优解,此时无论如何迭代结果都保持在这个局部最优解上了。
3. 模拟退火
模拟退火算法解决爬山法中存在的陷入局部最优解情况的解决方案就是它以一定的概率来接受一个比当前的解要查的解,因此有可能会跳出这个局部的最优解,达到全局的最优解。
因此模拟退火算法为了克服这个缺点,设计了新的更新办法。即倘若此时存在一个旧的解 x i x_i xi,其损失值为 f ( x i ) f(x_i) f(xi),而在 x i x_i xi的附近随即找到了一个新的解 x j x_j xj,其对应的损失值为 f ( x j ) f(x_j) f(xj),如果 f ( x j ) < f ( x i ) f(x_j)<f(x_i) f(xj)<f(xi),那么即证明新的解 x j x_j xj要优于旧的解 x i x_i xi,那么就用新的解 x j x_j xj替代旧的解 x i x_i xi,否则以一个接受的概率 p p p,其中 p p p位于[0,1],并且如果 f ( x i ) f(x_i) f(xi)和 f ( x j ) f(x_j) f(xj)越接近,则 p p p越大(直观意义上即新的解和旧的解的函数值越接近,则我们接收新的解的可能性越大)。
由于概率 p p p位于[0,1]之间,因此我们采用了函数 y = e x y=e^x y=ex,并且概率 p p p和函数值之差成反比,因此 p p p正比于 e − ∣ f ( x j ) − f ( x i ) ∣ e^{-|f(x_j)-f(x_i)|} e−∣f(xj)−f(xi)∣。同时,我们希望在前期,搜索范围更大一点,更倾向接收新的解,即 p p p相对大一些,同时后期希望能够在一定范围内更精细的搜索,即 p p p相对小些,因此我们引入了新的变量 c t c_t ct,此时计算概率 p p p的公式如下:
p = e − ∣ f ( x j ) − f ( x i ) ∣ c t p=e^{-|f(x_j)-f(x_i)|c_t} p=e−∣f(xj)−f(xi)∣ct
可以看出 p p p和 c t c_t ct呈反比,因此我们希望 c t c_t ct随着时间 t t t的变化逐渐递增。此时我们假设初始温度 T 0 T_0 T0=100,温度下降的公式为: T t + 1 = a T t T_{t+1}=aT_t Tt+1=aTt,根据经验, a a a常取为0.95,那么某一时刻 t t t的温度为: T t = a t T 0 = 100 ∗ 0.9 5 t T_t=a^tT_0=100*0.95^t Tt=atT0=100∗0.95t。可以看到, c t c_t ct和 T t T_t Tt呈反比,因此 c t c_t ct的计算公式为:
c t = 1 a t T 0 = 1 100 ∗ 0.9 5 t c_t=\frac{1}{a^tT_0}=\frac{1}{100*0.95^t} ct=atT01=100∗0.95t1
4.算法流程
此时以求函数
f
(
x
)
f(x)
f(x)在一定范围内的最大值为例。
(1)随机生成一个解A,计算解A对应的目标函数值
f
(
A
)
f(A)
f(A)。
(2)在A的附近随机生成一个解B,计算解B对应的目标函数值
f
(
B
)
f(B)
f(B)。如果
f
(
B
)
>
f
(
A
)
f(B)>f(A)
f(B)>f(A),则用解B替换解A,否则我们计算接收解B的概率,即
p
=
e
−
∣
f
(
B
)
−
f
(
A
)
∣
100
∗
0.9
5
t
p=e^{\frac{-|f(B)-f(A)|}{100*0.95^t}}
p=e100∗0.95t−∣f(B)−f(A)∣,然后生成一随机数
r
r
r,如果
r
<
p
r<p
r<p,则接收解B替换A称为新的解,否则仍保持原解A。
(3)在同一个温度
T
t
T_t
Tt(同一个
t
t
t)下不断重复步骤(2)直到达到设定的迭代次数(例如500次)(这里的迭代可以看成是内层的循环)后,更新温度和时间
t
t
t,更新公式为:
t
=
t
+
1
t=t+1
t=t+1
T
t
=
a
t
T
0
=
100
∗
0.9
5
t
T_t=a^tT_0=100*0.95^t
Tt=atT0=100∗0.95t
然后根据新的温度和时间 t t t返回步骤(2)继续进行迭代(这里的迭代可以看成外层的循环),直到满足终止条件。终止条件可以有很多种准则:(1)达到指定的外层迭代次数,例如迭代200次。(2)达到指定的温度,例如温度降低到0.000001一下。(3)我们找到的最优解 X X X连续 M M M次(例如30次)迭代都没有变化。
以上的讨论没有涉及到一个核心的问题,那就是模拟退火算法一定能找到最优解吗?可以利用随机过程中的马尔可夫过程证明,在一定条件下,当温度降为0时,最后的状态一定是全局最优解。而总体而言,其具有渐进收敛性,已经在理论上被证明以是一种以概率I收敛于全局最优解的全局优化算法。这就能够为模拟退火算法在求解全局最优化问题提供理论支持。
二、禁忌搜索算法(Tabu Search)
1.前言
禁忌搜索是一种现代启发式算法,由美国科罗拉多大学教授Fred Glover在1986年左右提出的,是一个用来跳脱局部最优解的搜索方法。其先创立一个初始化的解,然后不断的进行调整移动,提高解的质量,以此来寻找最优解的过程。
2.禁忌搜索名词
-
候选集合
候选集合一般由当前解的近似解组成,即将某解的邻居作为候选集合。例如对于某一问题,其初始解是[1,2,3],那么它的候选集和可以是[1,3,2],[2,1,3],[2,3,1]等等。
-
禁忌表
禁忌表中包含禁忌对象和禁忌长度。它的存在是为了使算法“不走回头路”,即避免一些重复的步骤,因此将一些元素放入禁忌表中,这些元素在下次搜索时不会再被考虑。这些被禁止搜索的元素就是禁忌对象。禁忌长度则是禁忌表中所能接受的最多禁忌对象的数量,倘若达到了数量的上限,将根据先进先出的原则进行替换。如果禁忌长度过大会导致算法耗时过长,过小则会造成出现重复搜索的情况。
-
评价函数
即用来评价一个解好坏的函数。例如TSP问题中就是旅程的总距离。
-
特赦规则
禁忌搜索算法中,在某一次迭代中,可能会出现候选集中的某一个方案由于其元素出现在了禁忌表中而被禁止搜索,但如果解禁该元素,则会使评价函数有所改善(能够获得一个更优的解),此时我们能够对该元素进行特赦,即暂时允许解禁该元素,使用该解然后重新将该元素放回到禁忌表中。
-
终止条件
当两次迭代所得到的局部最优解不再变化,或者达到迭代次数,或者两次迭代的评价函数值极其相近,即可停止迭代。通常情况下我们选择以达到指定迭代次数为终止条件。
3. 算法流程
以旅行商问题为例,假设一架飞机,从A点出发,经过B、C、D三点后返回A点,且每个点只能经过一次,最终返回A点,求最短路径。我们设定候选集合个数为2,禁忌长度为2。
(1)随机生成一个初始解,假设为[A,B,C,D,A],假设其路径为10。记录其历史最优为10。
(2)生成其2个候选集合,例如[A,C,B,D,A],假设其路径为12(交换BC)和[A,B,D,C,A],假设其路径为8(交换CD)。此时我们选择其中路径最短的[A,B,D,C,A]替换当前解,同时记录历史最优解的最短路径为8,并将交换CD放入禁忌表中。
(3)重复步骤(2)直到达到迭代次数,最终记录的历史最优解的最短路径即为答案。
注:
(1)步骤(2)中将某种交换方式放入禁忌表后,接下来的计算中,如果候选方案中有某个解以该替换方式生成,则其不能被选择来代替当前解,除非该方案的路径能够小于历史最优解的路径。
(2)步骤(2)中假设候选集合中的每个方案的路径都比当前方案的路径长,仍然需要从中选择较佳的方案替代当前方案。
三、遗传算法(Genetic Algorithms)
1.前言
遗传算法是仿真生物遗传学和自然选择机理,通过人工方式所构造的一类搜索算法。从某种程度上来说,遗传算法是对生物进化过程进行数学方式仿真。遗传算法主要思想是生物种群的生存过程中普遍遵循达尔文的进化准则,即群体中的个体根据对环境的适应能力从而被大自然所选择或淘汰。进化过程的结果反映在个体的结构上,就是个体通过交叉、变异来适应大自然环境。
2.遗传算法相关概念
-
适应度
适应度其本质就是代价函数,通过计算种群中个体的适应度,可以用于评估种群中的个体的优劣程度。
-
编码
遗传算法一般将个体进行二进制编码,即每个个体都是一个二进制编码的符号串,符号串的长度则与所求问题所要求的精度有关。 -
选择
选择操作就是根据种群中的个体的适应度函数所度量的优劣程度来决定他是否能够被选择。选择的策略有好几种,(1)轮盘赌选择法,即每个个体被选择的概率为根据其适应度的值决定,个体的适应度的值越好,其被选择的概率越大。(2)随机遍历抽样法,即每次都等概率的随机选择样本。(3)锦标赛选择法,即每次都随机从种群中选出若干个个体,然后选择其中最好的个体进入子代种群。
-
交叉
交叉操作就是随机选择两个个体,然后将两者的部分值进行交换。交叉策略有几种,(1)单点交叉,指在个体的编码串中随即设置一个交叉点,然后相互交换部分染色体。(2)两点交叉,指在个体编码串中随机设置了两个交叉点,然后再进行部分基因交换。(3)多点交叉,指在个体编码串中随机设置多个交叉点,然后进行基因交换。
-
变异
变异操作就是改变个体编码上的某些数值,最简单的变异就是随机产生一个随机数,将该位的数值反转,即1变成0,0变成1。
3.算法流程
(1)设置初始种群个数,迭代终止条件等。
(2)随机生成初始种群中的个体。
(3)对初始种群进行编码。
(3)进行交叉操作。
(4)进行变异操作。
(5)进行选择操作,生成下一代种群。
(6)判断是否达到迭代结束条件,例如达到指定迭代次数,如果没有则返回步骤(3),否则输出当前种群中最优的个体即为最终结果。
四、进化策略(Evolution Strategies)
1.前言
进化策略也是一种模仿生物进化的求解参数优化问题的方法,不过它与遗传算法不一样的是,它采用实数值作为基因(简单地说就是不进行编码),并且他总遵循着均值为0,某一方差的高斯分布的比那花产生新的个体,然后将较好的个体保留。
2.进化策略相关概念
-
交叉
和遗传算法一样,交叉就是交换两个个体的基因。
-
变异
变异则是在每个分量上加上一个零均值,某一方差的高斯分布的变化后产生的新的个体,这个某一方差就是下面提到的变异程度。
-
变异程度
变异程度会保持变化,在算法开始初期变异程度较大,直观上就是在大范围的进行搜索,在算法接近收敛后,变异程度会开始减小,即在小范围内仔细搜索。
-
选择策略
选择方案有两种,一种是(u+r)选择方式,即从u个父代个体及r个自带个体中选出最优的u个个体组成下一代新群体。(u,r)选择则是从r个子代新个体中选择u个最优的个体组成下一代群体,在这种选择方式中,每个个体都只能存活一代,随即便会被新的个体顶替。直观的看(u+r)选择似乎更好,因为它可以保证最优个体一直存活,使群体的进化过程呈单调上升的趋势,但是这种情况下可能得出来的是局部最优的解。根据实践证明,(u,r)选择方式要优于(u+r)选择方式,并已经成为进化策略中的主流方式。
3.算法流程
(1)设置初始种群个数,迭代终止条件等。
(2)随机生成初始种群中的个体。
(3)对初始种群进行编码。
(3)进行交叉操作。
(4)进行变异操作。
(5)进行选择操作,生成下一代种群。
(6)判断是否达到迭代结束条件,例如达到指定迭代次数,如果没有则返回步骤(3),否则输出当前种群中最优的个体即为最终结果。
4.进化策略和遗传算法区别对比
(1)进化策略是一种数值优化的方法,主要用于离散型优化问题。遗传算法是一种运用在二进制上的自适应搜索技术,主要用于参数优化。
(2)选择策略不同。
(3)参数变化不同,进化策略中的变异程度是在改变的;遗传算法中的参数一般保持恒定。
五、差分进化算法(Differential Evolution)
1.前言
Differential Evolution(DE)是由Storn等人于1995年提出的,和其它演化算法一样,DE是一种模拟生物进化的随机模型,通过反复迭代,使得那些适应环境的个体被保存了下来。但相比于进化算法,DE保留了基于种群的全局搜索策略,采用实数编码、基于差分的简单变异操作和一对一的竞争生存策略,降低了遗传操作的复杂性。同时,DE特有的记忆能力使其可以动态跟踪当前的搜索情况,以调整其搜索策略,具有较强的全局收敛能力和鲁棒性,且不需要借助问题的特征信息,适于求解一些利用常规的数学规划方法所无法求解的复杂环境中的优化问题。
2.差分进化算法相关概念
-
变异
差分进化中,每次执行变异操作都会产生一个变异算子。变异算子产生的方式如下:在种群中随机选取三个个体 X 1 X_1 X1, X 2 X_2 X2, X 3 X_3 X3,并根据这三个个体生成一个新的个体 H i H_i Hi作为变异算子,计算方式为:
H i = X 1 + F ( X 2 − X 3 ) H_i=X_1+F(X_2-X_3) Hi=X1+F(X2−X3)
其中 X 2 − X 3 X_2-X_3 X2−X3是差分向量,F是缩放因子,用于控制差分向量的影响力,一般在[0,2]之间选择,通常取为0.5。
-
交叉
在交叉步骤中,每个个体 X i X_i Xi会和它所生成的一个变异算子 H i H_i Hi进行交叉,具体而言,对于个体的每一位,按照一定的概率来选择让 X i , j X_{i,j} Xi,j替换 H i , j H_{i,j} Hi,j。即:
H i , j = { H i , j , r a n d ( 0 , 1 ) ≤ p r c X i , j , r a n d ( 0 , 1 ) > p r c H_{i,j}=\left\{ \begin{array}{c} H_{i,j}, rand(0,1)\le p_{rc} \\ X_{i,j},rand(0,1)>p_{rc}\end{array}\right. Hi,j={Hi,j,rand(0,1)≤prcXi,j,rand(0,1)>prc
其中, p r c p_{rc} prc为交叉概率。
-
选择
对于每一个个体 X i X_i Xi和与其对应的变异算子 H i H_i Hi,从二者中选择一个适应度表现更好的保存进入下一代种群。
3.算法流程
(1)设置初始种群个数,迭代终止条件等。
(2)随机生成初始种群中的个体。
(3)对初始种群进行编码。
(3)进行变异操作,对每一个个体生成与之对应的变异算子。
(4)进行交叉操作。对每一个变异算子根据其对应的个体进行交叉操作。
(5)进行选择操作,对每一对个体、变异算子对,从二者中选择适应度表现更好的进入下一代种群。
(6)判断是否达到迭代结束条件,例如达到指定迭代次数,如果没有则返回步骤(3),否则输出当前种群中最优的个体即为最终结果。
六、蚁群算法(Ant Colony Optimization)
1.前言
蚂蚁在行走过程中会释放一种称为“信息素”的物质,用来标识自己的行走路径。在寻找食物的过程中,根据信息素的浓度选择行走的方向,并最终到达食物所在的地方。信息素会随着时间的推移而逐渐挥发。在一开始的时候,由于地面上没有信息素,因此蚂蚁们的行走路径是随机的。蚂蚁们在行走的过程中会不断释放信息素,标识自己的行走路径。随着时间的推移,有若干只蚂蚁找到了食物,此时便存在若干条从洞穴到食物的路径。由于蚂蚁的行为轨迹是随机分布的,因此在单位时间内,短路径上的蚂蚁数量比长路径上的蚂蚁数量要多,从而蚂蚁留下的信息素浓度也就越高。这为后面的蚂蚁们提供了强有力的方向指引,越来越多的蚂蚁聚集到最短的路径上去。
2.蚁群算法相关参数及公式
注:以城市间最短路径为例
-
相关参数
m表示蚂蚁数量,k表示蚂蚁编号,d(i,j)表示城市(i,j)之间的距离, η i j η_{ij} ηij表示蚂蚁从城市i到j的启发程度, τ i j τ_{ij} τij表示边(i,j)上的信息素。 Δ τ i j Δτ_{ij} Δτij表示本次迭代边(i,j)上的信息素增量, Δ τ i j k Δτ_{ij}^k Δτijk表示第k只蚂蚁在本次迭代中在边(i,j)上的信息素增量,ρ为信息素蒸发系数, p i j k p_{ij}^k pijk表示蚂蚁k从城市i到j的概率。
-
启发式因子计算公式
η i j = 1 d i j η_{ij}=\frac{1}{d_{ij}} ηij=dij1
直观感受:两地距地越短,其启发式因子的值越大。
-
禁忌表
每只蚂蚁都有其对应的禁忌表,为了让蚂蚁能够遍历所有城市,不走回头路而设定。蚂蚁每经过一个城市,就把该城市加入禁忌表。
-
转移概率计算公式
p i j k = ( τ i j ) α ⋅ ( η i j ) β ∑ ( τ i s ) α ⋅ ( η i s ) , s ∈ J k p_{ij}^k=\frac{(τ_{ij})^α·(η_{ij})^β}{\sum(τ_{is})^α·(η_{is})},s∈J_k pijk=∑(τis)α⋅(ηis)(τij)α⋅(ηij)β,s∈Jk
其中, J k J_k Jk表示蚂蚁从当前城市(即i)可以到达的所有城市的集合。α为信息素的相对重要程度,β为启发式因子的相对重要程度。
直观感受:信息素越大,两地距离越短,则被选择的概率越大。
-
信息素更新公式
τ i j ( n e w ) = ( 1 − ρ ) ⋅ τ i j ( o l d ) + Δ τ i j τ_{ij}(new)=(1-ρ)·τ_{ij}(old)+Δτ_{ij} τij(new)=(1−ρ)⋅τij(old)+Δτij
Δ τ i j = ∑ Δ τ i j k Δτ_{ij}=\sumΔτ_{ij}^k Δτij=∑Δτijk
Δ τ i j k = Q L k Δτ_{ij}^k=\frac{Q}{L_k} Δτijk=LkQ,当蚂蚁k在本次周游中经过边(i,j),否则为0
其中,Q为一正常数, L k L_k Lk为蚂蚁k本次周游所走路径长度总和。
直观感受:每只蚂蚁所释放的信息数总量是一样的,若它所走的总路径越短,它所留下的信息素越多(浓度越大)。两地在本次迭代中的信息素变化量为所有蚂蚁在两地中留下的信息素。信息素的更新方式为原本存在的信息素会以一定比例挥发,再加上所有蚂蚁本次迭代留下的新的信息素。
-
补充
每一次迭代为所有蚂蚁完成以此周游。
3.算法流程
以城市间最短路径为例
(1)初始化参数,最开始时,每条边的信息素的量都相等。
(2)将各蚂蚁放置在各个顶点上,禁忌表为对应的顶点。
(3)计算蚂蚁k前往各个城市的概率 p i j p_ij pij,然后按照轮盘赌方式选择前往的顶点,然后更新禁忌表,不断循环直到遍历了所有顶点一次。
(4)计算该蚂蚁留在各边上的信息素。
(5)不断循环步骤(3)和(4)直到m只蚂蚁全部完成了周游。
(6)计算各边的信息素增量和信息素量。
(7)记录本路迭代的路径,更新最优路径,清空禁忌表。
(8)判断是否达到了算法终止条件,如迭代次数等。若满足,则输出记录下的最优路径,否则,返回步骤(2)进行新一轮迭代。
七、粒子群优化算法(Particle Swarm Optimization)
1.前言
粒子群优化算法的思想来自于对鸟类捕食行为的研究,通过模拟鸟群飞行觅食的行为,使得群体达到最优的目的。它并没有遗传算法中的交叉和变异操作,而是通过追随当前已知的最优值来寻找全局最优解。粒子群优化算法相较于其他优化算法而言,需要调整的参数很少,收敛速度快,简单易实现。
2.粒子群优化算法相关参数及公式
-
相关参数
假设整个空间的维度为D,一共有N个粒子,其中粒子i的当前位置为 X i = ( X i 1 , X i 2 , . . . X i D ) X_i=(X_{i1},X_{i2},...X_{iD}) Xi=(Xi1,Xi2,...XiD),粒子i的速度为 V i = ( V i 1 , V i 2 , . . . V i D ) V_i=(V_{i1},V_{i2},...V_{iD}) Vi=(Vi1,Vi2,...ViD)。同时我们还需要记录每个粒子i所经历过的最好位置(即粒子i通过适应度函数计算出表现最好的位置) p b e s t i = ( p i 1 , p i 2 , . . . p i D ) pbest_i=(p_{i1},p_{i2},...p_{iD}) pbesti=(pi1,pi2,...piD),以及整个种群所经历过的最好位置 g b e s t = ( g 1 , g 2 , . . . g D ) gbest=(g_1,g_2,...g_D) gbest=(g1,g2,...gD)。通常每一维度的位置和速度变化都有指定的区间,即 [ X m i n , d , X m a x , d ] [X_{min,d},X_{max,d}] [Xmin,d,Xmax,d]和 [ − V m a x , d , V m a x , d ] [-V_{max,d},V_{max,d}] [−Vmax,d,Vmax,d],粒子在该维度的位置和速度不能超过边界值,如果超出了边界值,则应被设置为边界值。
-
适应度函数
每一个粒子(小鸟)都在整个空间中进行搜索,而粒子当前位置的好坏则通过适应度函数进行判断。
-
粒子速度及位置更新公式
V i d k = w v i d k − 1 + c 1 r 1 ( p b e s t i d − x i d k − 1 ) + c 2 r 2 ( g b e s t i d − x i d k − 1 ) V_{id}^k=wv_{id}^{k-1}+c_1r_1(pbest_{id}-x_{id}^{k-1})+c_2r_2(gbest_{id}-x_{id}^{k-1}) Vidk=wvidk−1+c1r1(pbestid−xidk−1)+c2r2(gbestid−xidk−1)
x i d k = x i d k − 1 + v i d k − 1 x_{id}^k=x_{id}^{k-1}+v_{id}^{k-1} xidk=xidk−1+vidk−1
其中:
v i d k v_{id}^k vidk表示第k次迭代中粒子i在第d维的飞行速度
x i d k x_{id}^k xidk表示第k次迭代中粒子i在第d维的位置
c 1 , c 2 c_1,c_2 c1,c2为加速度常数,用于调节学习步长
r 1 , r 2 r_1,r_2 r1,r2是两个随机数,取值在[0,1]之间,用于增加搜索的随机性
w w w为惯性权重,非负数,用于调节对解空间的搜索范围。
3.算法流程
(1)在初始范围内,对粒子群进行随机初始化,包括每个粒子的初始位置和初始速度。
(2)根据适应度函数,计算每个粒子的适应度值。
(3)对每个粒子,将当前适应度的值与其个体历史最佳位置(pbest)对应的适应度值进行比较,如果当前的适应度值更高,则用当前位置更新该粒子个体的历史最优位置pbest。
(4)对每个粒子,将其当前适应度的值与全局最佳位置(gbest)对应的适应度的值进行对比。如果当前适应度的值更高,则用当前位置更新整个粒子群的历史最优位置gbest。
(5)根据公式更新每个粒子的速度和位置。
(6)判断是否达到算法的终止条件,若达到了则停止迭代并输出整个粒子群的历史最优位置gbest,否则转到步骤(2)。
参考文献
模拟退火:
https://mp.weixin.qq.com/s/001Klrt7jjf8s5rI3py7Yg
禁忌搜索:
https://blog.csdn.net/adkjb/article/details/81712969
遗传算法、进化策略:
https://blog.csdn.net/u014248127/article/details/79143437
https://blog.csdn.net/changyuanchn/article/details/80331134
https://zhuanlan.zhihu.com/p/28622201
差分进化算法:
https://www.omegaxyz.com/2018/04/24/differential_evolution_intro/
https://blog.csdn.net/weixin_42528077/article/details/82779819?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_baidulandingword-1&spm=1001.2101.3001.4242
https://blog.csdn.net/qq_37423198/article/details/77856744
https://blog.csdn.net/mxxxkuku/article/details/102576024
蚁群算法:
https://blog.csdn.net/u011125673/article/details/88087479
https://zhuanlan.zhihu.com/p/137408401
PSO:
https://blog.csdn.net/xiaofalu/article/details/100576488
总结
总的来说,本文对几种启发式算法进行了简单的介绍,可能没有比较严谨的推理,也没有比较深入的进行介绍和研究。不过我用了自认为比较口语化的方式对算法进行描述和解释,来让大家对各个模型有一个认识。欢迎大家批评指正。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 40
40 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)