
xunsearch php实例,xunsearch系列(一)安装篇
先来了解一下什么是全文检索(全文搜索)?全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文搜索搜索引擎数据库中的数据。一、什么是xunsearch?概况xunsearch是一个以GPL协议开源发布的高性
先来了解一下什么是全文检索(全文搜索)?
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文搜索搜索引擎数据库中的数据。
一、什么是xunsearch?
概况
xunsearch是一个以GPL协议开源发布的高性能、全功能的全文检索解决方案,并针对中文深度优化和处理,用于帮助开发者针对海量数据快速建立搜索引擎。
xunsearch采用结构化分层设计,包含后端服务器和前端开发包两大部分。后端采用c/c++基于xapian搜索库、scws中文分词、libevent等开源库开发,借鉴了nginx的多进程多线程混合工作方式,是一个可承载高并发的高性能服务端。前端则是使用流行的脚本语言编写的开发工具包(即SDK),API简单清晰上手容易,并附带全中文的示例代码、文档和辅助工具,目前暂只支持PHP语言。
特色优势
海量数据下高速搜索响应。单库最多支持40亿条数据,在500万张网页1.5TB数据中,非缓存检索时间约为0.5秒。
专为搜索而自主开发的scws中文分词,支持复合分词、自定义补充词库,保障查全率、准确率。
健壮稳定的后端守护程序,内置缓存池与线程池用于保障性能。
索引接口齐全容易,支持实时搜索,支持任何数据库源(不局限于SQL)。
极低的开发难度,具备规范的中文文档,示范代码,辅助工具。
除通用搜索引擎功能外,还内置拼音检索、分面搜索、相关搜索、同义词搜索、搜索纠错建议等专业功能。
与Lucene、Sphinx等相比,xunsearch提供了更丰富且必须的功能,开发难度更低,开发周期更短。
应用领域目前后端服务器只支持UNIX(含Linux、BSD、MacOS等)操作系统,前端开发包只支持PHP语言。
xunsearch可以帮助你建立门户、垂直搜索、论坛搜索、WEB站内搜索、文档文献资料搜索等。
架构简图
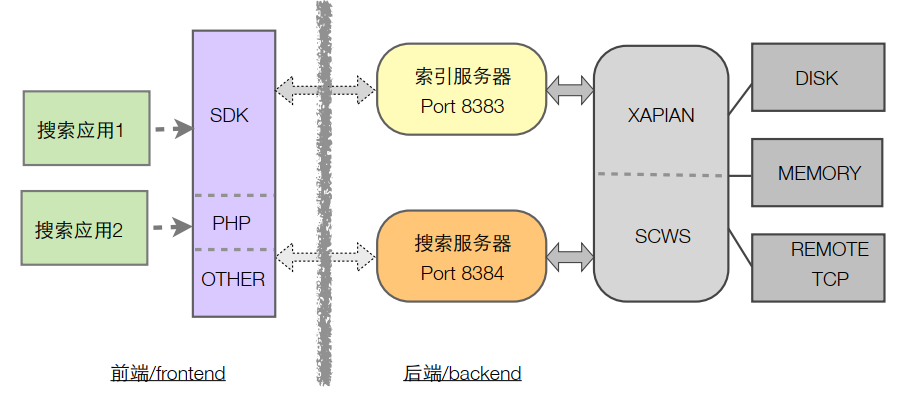
二、安装
服务端
前端的xunsearch PHP-SDK与服务端通讯协同工作,要想使用xunsearch搜索就必须安装xunsearch服务端,目前只支持UNIX类型的操作系统(含Linux、BSD、MacOS在内)以源码方式编译安装,暂不支持Windows操作系统。因此也要求你的服务器上你必须装有gcc、make等软件包编译安装工具。
这里安装的包是:xunsearch-full-latest.tar.bz2
1、运行下面指令下载、解压安装包wget http://xunsearch.com/download/xunsearch-full-latest.tar.bz2
tar -jxvf xunsearch-full-latest.tar.bz2
2、执行安装脚本,根据提示进行操作即可,主要是输入xunsearch 软件包的安装目录。cd xunsearch-full-1.4.13/
sh setup.sh
第一次安装的话,过程可能会稍显漫长,请不必着急,您大可泡杯茶一边喝一边等待即可。
安装成功后的界面如下:
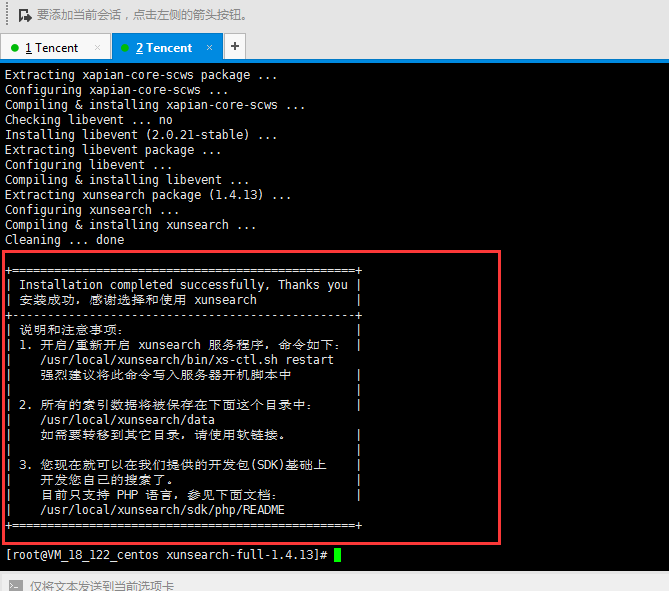
3、启动测试cd /usr/local/xunsearch/bin/
./xs-ctl.sh start #启动xunsearch服务 默认监听本地的8383、8384端口
./xs-ctl.sh stop #停止xunsearch服务
./xs-ctl.sh restart #重新启动xunsearch服务
#服务端和SDK不在同一台服务器的情况:
/xunsearch安装目录/bin/xs-ctl.sh -b inet start #启动服务 绑定全部IP,适合SDK/服务端 在不同服务器的情况
/xunsearch安装目录/bin/xs-ctl.sh -b inet stop #停止服务 若启动时指定了-b inet 此处也必须指定
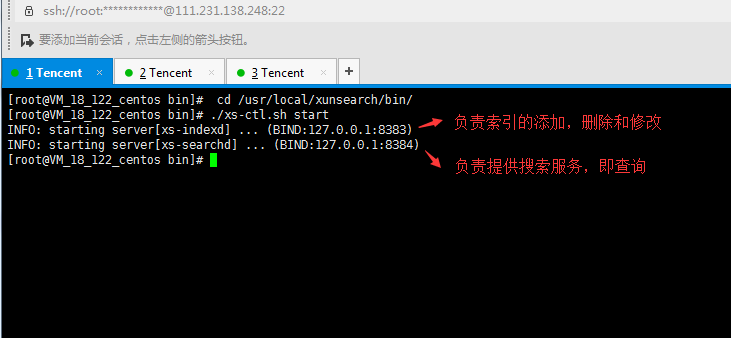
说明:会启动两个服务
1、索引服务(8383):负责索引的添加,删除和修改
2、搜索服务(8384):负责提供搜索服务,即查询
启动服务示例截图如下:
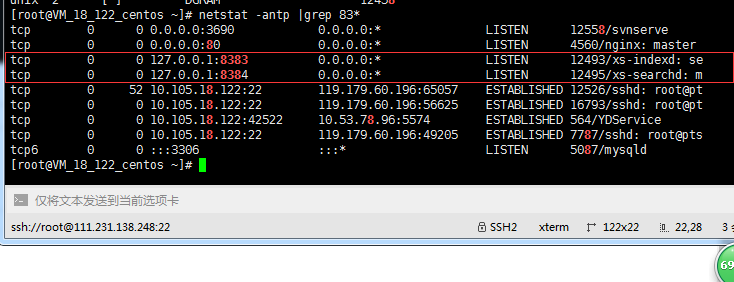
可通过进程以及端口查看服务是否启动成功,启动成功如下:

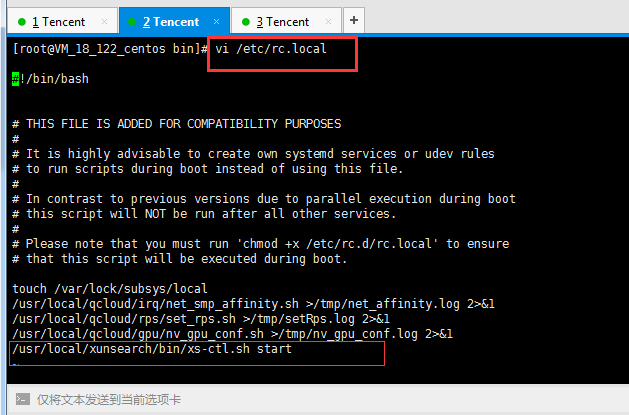
4、加入开机自动启动xunsearch服务vi /etc/rc.local
/usr/local/xunsearch/bin/xs-ctl.sh start #将改行命令加在文件最后一行即可
保存退出
示例截图如下:
5、将xunsearch中的bin目录加入到环境变量中,以后可以在任意目录直接执行xunsearch/bin目录下的相关命令了vi /etc/profile
export PATH=$PATH:/usr/local/xunsearch/bin
如果你的profile文件底部已经有了export PATH=$PATH......等省略一堆命令...... 那你直接在后面在加上一个冒号(:)
然后在冒号后面加上xunsearch的bin目录的路径即可
保存退出
示例截图如下:
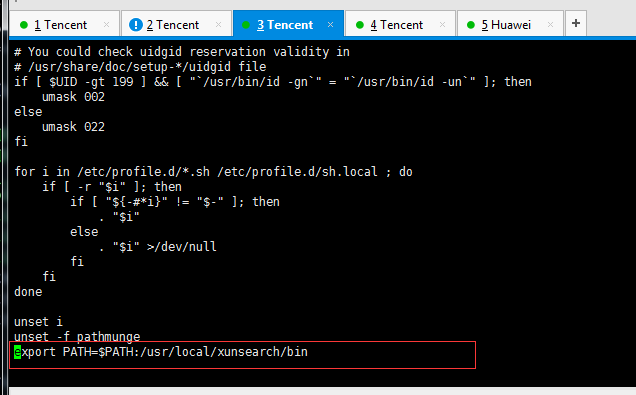
最后在执行命令:source /etc/profile #使刚刚的改动立即生效
是的 没错,安装就是这么简单。特别提示,搜索的所有索引数据将被保存到/usr/local/xunsearch/data目录,如果你希望数据目录另行安排,请采用软连接形式确保/usr/local/xunsearch/data链至真实数据目录。此外,如果服务端启动时使用了-b inet参数,那么请借助iptables或其它防火墙工具进行保护,xunsearch本身出于性能考虑不做其它验证处理。
三、题外篇
关于SCWS 中文分词
SCWS 是 Simple Chinese Word Segmentation 的首字母缩写(即:简易中文分词系统)。
这是一套基于词频词典的机械式中文分词引擎,它能将一整段的中文文本基本正确地切分成词。 词是中文的最小语素单位,但在书写时并不像英语会在词之间用空格分开, 所以如何准确并快速分词一直是中文分词的攻关难点。
SCWS 采用纯 C 语言开发,不依赖任何外部库函数,可直接使用动态链接库嵌入应用程序,支持的中文编码包括 GBK、UTF-8 等。此外还提供了 PHP 扩展模块,可在 PHP 中快速而方便地使用分词功能。
分词算法上并无太多创新成分,采用的是自己采集的词频词典,并辅以一定的专有名称,人名,地名, 数字年代等规则识别来达到基本分词,经小范围测试准确率在 90% ~ 95% 之间, 基本上能满足一些小型搜索引擎、关键字提取等场合运用。首次雏形版本发布于 2005 年底。
SCWS 由hightman开发,并以BSD许可协议开源发布,源码托管在github。
更多SCWS 中文分词可参考官网,地址如下:
xunsearch安装也可参考如下网址:
声明:禁止任何非法用途使用,凡因违规使用而引起的任何法律纠纷,本站概不负责。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)