
随机森林模型
随机森林模型集成模型简介Bagging算法Boosting算法随机森林模型1、基本原理1、数据随机2、特征随机随机森林的代码实现集成模型简介集成学习模型使用一系列弱学习器(基础模型或者基模型)进行学习。将各个弱学习器的结果进行整合,从而达到比单个学习器更好的学习效果。常见的算法有bagging算法和boosting算法。随机森林就是典型的bagging算法,而boosting算法的典型学习模型有A
集成模型简介
集成学习模型使用一系列弱学习器(基础模型或者基模型)进行学习。将各个弱学习器的结果进行整合,从而达到比单个学习器更好的学习效果。常见的算法有bagging算法和boosting算法。随机森林就是典型的bagging算法,而boosting算法的典型学习模型有Adaboost、GBDT、XGBoost、LightGBM。
Bagging算法
bagging算法原理类似投票,每次使用一个训练集训练一个弱学习器,有放回地随机抽取n次后,根据不同的训练集训练出n个弱学习器。对于分类问题,根据所有的弱学习器的投票,进行“少数服从多数”的原则进行最终预测结果。对于回归问题,采取所有学习器的平均值作为最终结果。
Boosting算法
Boosting算法本质是将弱学习器提升至强学习器。它和bagging算法区别在于,bagging算法对待所有的弱学习器一视同仁,而boosting算法则对弱学习器区别对待,改变弱学习器的权重。具体表现在:1、在每一论训练后对预测结果较准确的弱学习器给予较大权重,对不好的弱学习器降低权重。2、在每一轮训练后改变训练集的权值或概率分布。通过提高前一轮被弱学习器预测错误的样例的权值,降低前一轮被弱学习器预测正确的样例权值。提高若学器对预测错误的数据的重视程度。
随机森林模型
1、基本原理
随机森林(random forest)是一种经典的bagging模型,其弱学习器为决策树模型。为了保证模型的泛化能力,在建立每棵树时,遵循“数据随机”和“特征随机”两个基本原则。
1、数据随机
从所有数据中有放回地随机抽取数据作为其中一个决策树模型的训练数据。
2、特征随机
假设每个样本的维度为M,指定一个常数k<M,随机地从M个特征中选取k个特征,在使用python构造随机森林模型,默认选取特征的个数k为√M。
随机森林的代码实现
随机森林分类模型的弱学习器是分类决策树模型,随机森林回归模型的弱学习器是回归决策树模型。
####随机森林0-1分类模型
from sklearn.ensemble import RandomForestClassifier
X = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
y = [0, 0, 0, 1, 1]
model = RandomForestClassifier(n_estimators=10, random_state=123)
model.fit(X, y)
print(model.predict([[5, 5]]))
n_estimators:若学习器的数量
random_state:随机种子,
###随机森林回归模型
from sklearn.ensemble import RandomForestRegressor
X = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
y = [1, 2, 3, 4, 5]
model = RandomForestRegressor(n_estimators=10, random_state=123)
model.fit(X, y)
print(model.predict([[5, 5]]))
案例实战
量化金融股票
1、引入所需要的库
import tushare as ts # 股票基本数据相关库
import numpy as np # 科学计算相关库
import pandas as pd # 科学计算相关库
import talib # 股票衍生变量数据相关库
import matplotlib.pyplot as plt # 引入绘图相关库
from sklearn.ensemble import RandomForestClassifier # 引入分类决策树模型
from sklearn.metrics import accuracy_score # 引入准确度评分函数
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息,警告非报错,不影响代码执行
2、获取数据
# 1.股票基本数据获取
df = ts.get_k_data('000002',start='2015-01-01',end='2019-12-31')
df = df.set_index('date') # 设置日期为索引
# 2.简单衍生变量构造
df['close-open'] = (df['close'] - df['open'])/df['open']
df['high-low'] = (df['high'] - df['low'])/df['low']
df['pre_close'] = df['close'].shift(1) # 该列所有往下移一行形成昨日收盘价
df['price_change'] = df['close']-df['pre_close']
df['p_change'] = (df['close']-df['pre_close'])/df['pre_close']*100
# 3.移动平均线相关数据构造
df['MA5'] = df['close'].rolling(5).mean()
df['MA10'] = df['close'].rolling(10).mean()
df.dropna(inplace=True) # 删除空值
# 4.通过Ta_lib库构造衍生变量
df['RSI'] = talib.RSI(df['close'], timeperiod=12) # 相对强弱指标
df['MOM'] = talib.MOM(df['close'], timeperiod=5) # 动量指标
df['EMA12'] = talib.EMA(df['close'], timeperiod=12) # 12日指数移动平均线
df['EMA26'] = talib.EMA(df['close'], timeperiod=26) # 26日指数移动平均线
df['MACD'], df['MACDsignal'], df['MACDhist'] = talib.MACD(df['close'], fastperiod=12, slowperiod=26, signalperiod=9) # MACD值
df.dropna(inplace=True) # 删除空值
3、特征变量和目标变量提取
X = df[['close', 'volume', 'close-open', 'MA5', 'MA10', 'high-low', 'RSI', 'MOM', 'EMA12', 'MACD', 'MACDsignal', 'MACDhist']]
y = np.where(df['price_change'].shift(-1)> 0, 1, -1)
4、划分训练集和测试集
X_length = X.shape[0] # shape属性获取X的行数和列数,shape[0]即表示行数
split = int(X_length * 0.9)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
5、模型构建
model = RandomForestClassifier(max_depth=3, n_estimators=10, min_samples_leaf=10, random_state=1)
model.fit(X_train, y_train)
完整的RandomForestClassifier参数
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=3, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=10, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10,
n_jobs=None, oob_score=False, random_state=1, verbose=0,
warm_start=False)
6、预测
y_pred = model.predict(X_test)
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
用pridict_paoba()函数科研预测各个分类的概率
# 查看预测概率
y_pred_proba = model.predict_proba(X_test)
y_pred_proba[0:5]
7、模型准确度评估
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
# 此外,我们还可以通过模型自带的score()函数记性打分,代码如下:
model.score(X_test, y_test)
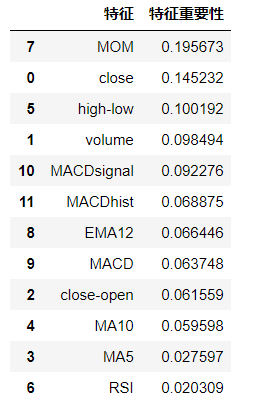
8、分析特征变量的特征重要性
model.feature_importances_
# 通过如下代码可以更好的展示特征及其特征重要性:
features = X.columns
importances = model.feature_importances_
a = pd.DataFrame()
a['特征'] = features
a['特征重要性'] = importances
a = a.sort_values('特征重要性', ascending=False)
参数调优
from sklearn.model_selection import GridSearchCV # 网格搜索合适的超参数
# 指定分类器中参数的范围
parameters = {'n_estimators':[5, 10, 20], 'max_depth':[2, 3, 4, 5], 'min_samples_leaf':[5, 10, 20, 30]}
new_model = RandomForestClassifier(random_state=1) # 构建分类器
grid_search = GridSearchCV(new_model, parameters, cv=6, scoring='accuracy') # cv=6表示交叉验证6次,scoring='roc_auc'表示以ROC曲线的AUC评分作为模型评价准则, 默认为'accuracy', 即按准确度评分,设置成'roc_auc'表示以ROC曲线的auc值作为评估标准
grid_search.fit(X_train, y_train) # 传入数据
grid_search.best_params_ # 输出参数的最优值

9、 收益回测曲线绘制
X_test['prediction'] = model.predict(X_test)
X_test['p_change'] = (X_test['close'] - X_test['close'].shift(1)) / X_test['close'].shift(1)
X_test['origin'] = (X_test['p_change'] + 1).cumprod()
X_test['strategy'] = (X_test['prediction'].shift(1) * X_test['p_change'] + 1).cumprod()
X_test[['strategy', 'origin']].tail()

# 通过如下代码将收益情况删除空值后可视化,并设置X轴刻度自动倾斜:
X_test[['strategy', 'origin']].dropna().plot()
plt.gcf().autofmt_xdate()
plt.show()


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)