
fp16和fp32,神经网络混合精度训练,PYTORCH 采用FP16,Libtorch采用FP16,神经网络混合精度三种避免损失,TensorRT模型转换及部署(一)
文章目录基础知识利用fp16 代替 fp32PYTORCH 采用FP16后的速度提升问题Libtorch采用FP16后的速度提升问题CPU上tensor不支持FP16tf 的调用如何在TensorRT上用半精度(FP16)对Caffemodel进行inference神经网络混合精度训练三种避免损失TensorRT模型转换及部署,FP32/FP16/INT8精度区分转换流程Parser如今支持:优化
文章目录
基础知识
我之前写的《IEEE 754规定的浮点数规则与发送与接收float数据的代码示例》
https://blog.csdn.net/djfjkj52/article/details/106731419
single与double
double精度是float的两倍,所以需要更精确的计算常使用double。 单精度浮点数在机内占4个字节,用32位二进制描述。 双精度浮点数在机内占8个字节,用64位二进制描述。 浮点数在机内用指数型式表示,分解为:数符,尾数,指数符,指数四部分。
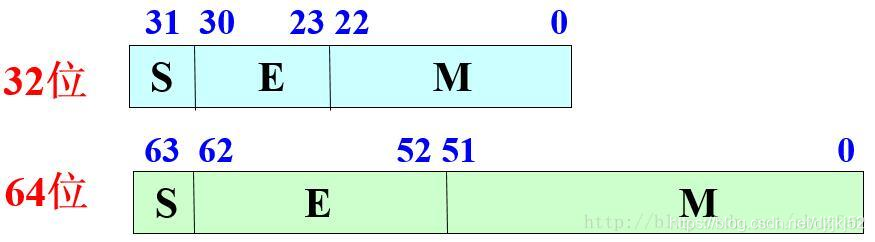

IEEE标准中的FP16格式如下:
取值范围是5.96× 10−8 ~ 65504,而FP32则是1.4×10-45 ~ 3.4×1038。
从FP16的范围可以看出,用FP16代替原FP32神经网络计算的最大问题就是精度损失。
利用fp16 代替 fp32
float : 1个符号位、8个指数位和23个尾数位
优点:
1)TensorRT的FP16与FP32相比能有接近一倍的速度提升168,前提是GPU支持FP16(如最新的2070,2080,2080ti等)。混合精度训练是在尽可能减少精度损失的情况下利用半精度浮点数加速训练。它使用FP16即半精度浮点数存储权重和梯度。在减少占用内存的同时起到了加速训练的效果。
2)减少显存。
缺点:
1) 会造成溢出
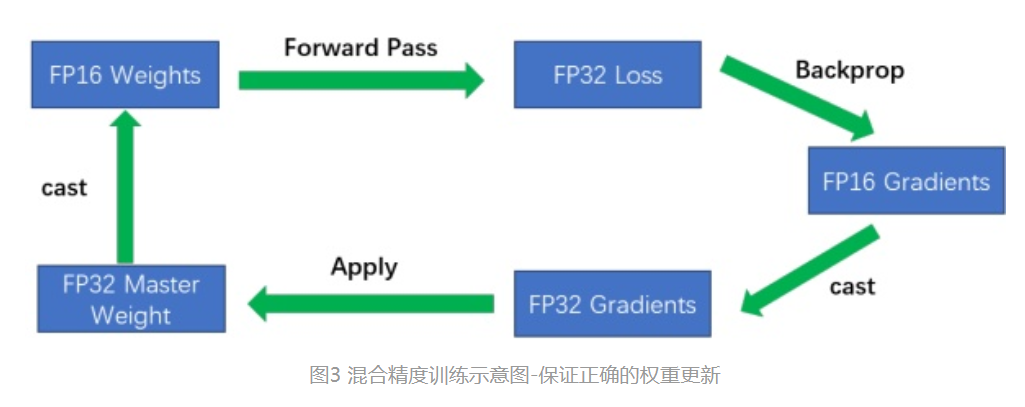
因此,在日常使用过程中,常使用双混合精度训练。如图:
 此过程中的技术:
此过程中的技术:
1) Loss scaling :会存在很多梯度在FP16表达范围外,我们为了让其落入半精度范围内,会给其进行等比放大后缩小。
流程:

PYTORCH 采用FP16后的速度提升问题
https://www.jianshu.com/p/cf83c877d71d
pytorch可以使用half()函数将模型由FP32迅速简洁的转换成FP16.但FP16速度是否提升还依赖于GPU。以下面的代码为例,
import time
import torch
from torch.autograd import Variable
import torchvision.models as models
import torch.backends.cudnn as cudnn
cudnn.benchmark = True
net = models.resnet18().cuda()
inp = torch.randn(64, 3, 224, 224).cuda()
for i in range(5):
net.zero_grad()
out = net.forward(Variable(inp, requires_grad=True))
loss = out.sum()
loss.backward()
torch.cuda.synchronize()
start=time.time()
for i in range(100):
net.zero_grad()
out = net.forward(Variable(inp, requires_grad=True))
loss = out.sum()
loss.backward()
torch.cuda.synchronize()
end=time.time()
print("FP32 Iterations per second: ", 100/(end-start))
net = models.resnet18().cuda().half()
inp = torch.randn(64, 3, 224, 224).cuda().half()
torch.cuda.synchronize()
start=time.time()
for i in range(100):
net.zero_grad()
out = net.forward(Variable(inp, requires_grad=True))
loss = out.sum()
loss.backward()
torch.cuda.synchronize()
end=time.time()
print("FP16 Iterations per second: ", 100/(end-start))
在1080Ti上的性能对比:
FP32 Iterations per second: 10.37743206218922
FP16 Iterations per second: 9.855269155760238
FP32 Memory:2497M
FP16 Memory:1611M
可以发现FP16显著的降低了显存,但是速度没有提升,反而有些许下降。
然后观察在 V100 上的性能对比:
FP32 Iterations per second: 16.325794715481173
FP16 Iterations per second: 24.853492643300903
FP32 Memory: 3202M
FP16 Memory: 2272M
此时显存显著降低且速度也提升较明显。
关于pytorch 中采用FP16有时速度没有提升的问题,参考https://discuss.pytorch.org/t/cnn-fp16-slower-than-fp32-on-tesla-p100/12146
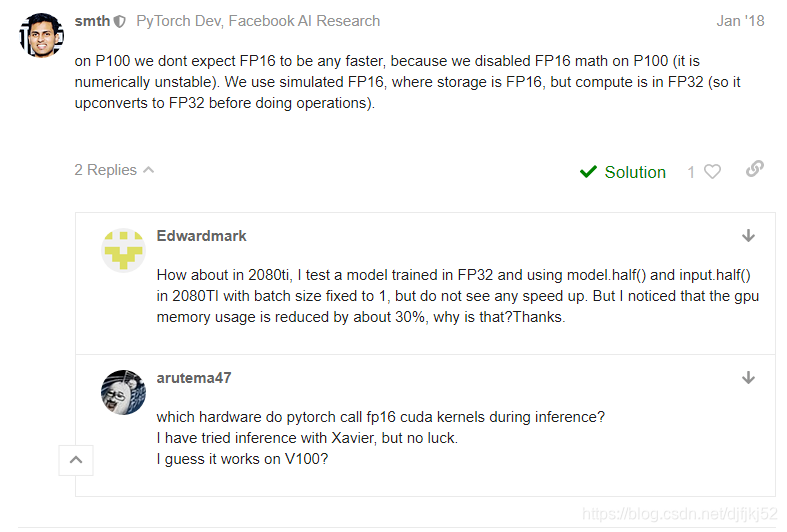
在P100上,我们不希望FP16更快,因为我们在P100上禁用了FP16数学运算(这在数值上是不稳定的)。 我们使用模拟的FP16,其中存储为FP16,但计算位于FP32中(因此在执行操作之前它会向上转换为FP32)。
在2080ti中,我测试了在FP32中训练的模型,并在2080TI中使用model.half()和input.half()将批处理大小固定为1,但是没有看到任何加速。 但是我注意到gpu的内存使用量减少了约30%,这是为什么呢?
您正在使用哪种操作,特别是哪个cudnn版本?
如果您使用的是cudnn 7.3及更高版本,则卷积应将TensorCores用于FP16输入。
但是,GEMM(例如用于线性层)的大小限制为8的倍数。对于矩阵A x矩阵B,其中A的大小为[I,J],B的大小为[J,K],I,J和K 要使用TensorCores,必须是8的倍数。 所有cublas和cudnn版本均存在此要求。
另外,您可以在脚本开头尝试使用torch.backends.cudnn.benchmark = True吗?
操作包含conv2d和conv_transpose2d。 我已经将cudnn基准设置为true,但是我的某些矩阵不是8的倍数,我将尝试对其进行更改然后进行测试。 CUDA版本9.2.148,cudnn 7.6.3。
非常感谢你。
Libtorch采用FP16后的速度提升问题
https://www.jianshu.com/p/cf83c877d71d
我们在V100上测试FP16是否能提升libtorch的推理速度。
1 下载libtorch
wget https://download.pytorch.org/libtorch/cu101/libtorch-cxx11-abi-shared-with-deps-1.6.0%2Bcu101.zip
unzip libtorch-cxx11-abi-shared-with-deps-1.6.0+cu101.zip
在pytorch官网找到对应版本的libtorch,libtorch一般会向下支持,我这里的libtorch版本1.6.0, pytorch安装的是1.1.0
2 pytorch生成trace.pt
import torch
import torchvision.models as models
net = models.resnet18().cuda()
net.eval()
inp = torch.randn(64, 3, 224, 224).cuda()
traced_script_module = torch.jit.trace(net, inp)
traced_script_module.save("RESNET18_trace.pt")
print("trace has been saved!")
3 libtorch 调用trace
#include<iostream>
#include<vector>
#include<torch/script.h>
#include <cuda_runtime_api.h>
using namespace std;
int main()
{
at::globalContext().setBenchmarkCuDNN(true);
std::string model_file = "/home/zwzhou/Code/test_libtorch/RESNET18_trace.pt";
torch::Tensor inputs = torch::rand({64, 3, 224, 224}).to(at::kCUDA);
torch::jit::script::Module net = torch::jit::load(model_file); // load model
net.to(at::kCUDA);
auto outputs = net.forward({inputs});
cudaDeviceSynchronize();
auto before = std::chrono::system_clock::now();
for (int i=0; i<100; ++i)
{
outputs = net.forward({inputs});
}
cudaDeviceSynchronize();
cudaDeviceSynchronize();
auto after = std::chrono::system_clock::now();
std::chrono::duration<double> all_time = after - before;
std::cout<<"FP32 iteration per second: "<<(100/all_time.count())<<"\n";
net.to(torch::kHalf);
cudaDeviceSynchronize();
before = std::chrono::system_clock::now();
for (int i=0; i<100; ++i)
{
outputs = net.forward({inputs.to(torch::kHalf)});
}
cudaDeviceSynchronize();
after = std::chrono::system_clock::now();
std::chrono::duration<double> all_time2 = after - before;
std::cout<<"FP16 iteration per second: "<<(100/all_time2.count())<<"\n";
}
4 编写CMakeLists.txt
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)
project(FP_TEST)
set(CMAKE_PREFIX_PATH "/home/zwzhou/packages/libtorch/share/cmake/Torch")
set(DCMAKE_PREFIX_PATH /home/zwzhou/packages/libtorch)
find_package(Torch REQUIRED)
add_executable(mtest ./libtorch_test.cpp)
target_link_libraries(mtest ${TORCH_LIBRARIES})
set_property(TARGET mtest PROPERTY CXX_STANDARD 14)
5 测评时间
cd build
cmake ..
make
./mtest
6 输出时间
FP32 iteration per second: 60.6978
FP16 iteration per second: 91.5507
可以发现,libtorch版本比pytorch版本速度提升比较明显;另外,可以看出在V100上FP16同样能够提升libtorch的推理速度。
CPU上tensor不支持FP16
CPU上tensor不支持FP16,所以CUDA上推理完成后转成CPU后还需要转到FP32上。
https://discuss.pytorch.org/t/runtimeerror-add-cpu-sub-cpu-not-implemented-for-half-when-using-float16-half/66229
tf 的调用
Google的TensorFlow则比较简单粗暴,把单精度的后16位砍掉,也就是1位符号、8位指数和7位尾数。动态范围和单精度相同,精度只有 lg28,2个有效数字。
我找到了实现它的方法。
使用 tf.train.NewCheckpointReader()加载检查点,然后读取参数并将其转换为float16类型。
使用float16读取参数初始化图层
weight_name = scope_name + '/' + get_layer_str() + '/' + 'weight'
initw = inits[weight_name]
weight = tf.get_variable('weight', dtype=initw.dtype, initializer=initw)
out = tf.nn.conv2d(self.get_output(), weight, strides=[1, stride, stride, 1], padding='SAME')
GPU是没有张量核心的GTX1080,但是使用fp16的推理要比使用fp32的推理快20%-30%,我不明白原因,并且使用了哪个“硬件单元”计算fp16,fp32的传统单位是吗?
如何在TensorRT上用半精度(FP16)对Caffemodel进行inference
http://whitelok.github.io/2018/09/05/how_to_do_caffemodel_inference_with_tensorrt_with_FP16/
FP32即float占用的是4字节,FP16占用的2字节。 Nvidia有大量的计算加速框架(cuDNN, cuBlas)以及加速硬件(Tensor Core, DLA)对FP16的数据有加速优化
NVidia是如何处理float与FP16的转换的,和其他普通的框架处理精度问题之间的区别是什么?
在IEEE-754的描述中单精度浮点数(Nvidia习惯称为FP32,C++标准中的float)是4个字节,包括1位符号、8位指数和23位尾数。
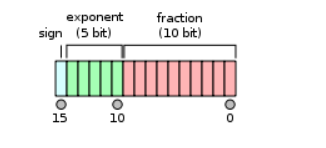
NVidia在2002年提出了半精度浮点数FP16,只使用2个字节16位,包括1位符号、5位指数和10位尾数,动态范围是 2−30∼231也就是 10−9∼109,精度是 lg211,大约3个十进制有效数字。NVidia的方案已经被IEEE-754采纳。Google的TensorFlow则比较简单粗暴,把单精度的后16位砍掉,也就是1位符号、8位指数和7位尾数。动态范围和单精度相同,精度只有 lg28,2个有效数字。
NVidia的float与FP16的转换方法:
float –> FP16
typedef unsigned short half;
half nvFloat2Half(float m)
{
unsigned long m2 = *(unsigned long*)(&m);
// 强制把float转为unsigned long
// 截取后23位尾数,右移13位,剩余10位;符号位直接右移16位;
// 指数位麻烦一些,截取指数的8位先右移13位(左边多出3位不管了)
// 之前是0~255表示-127~128, 调整之后变成0~31表示-15~16
// 因此要减去127-15=112(在左移10位的位置).
unsigned short t = ((m2 & 0x007fffff) >> 13) | ((m2 & 0x80000000) >> 16)
| (((m2 & 0x7f800000) >> 13) - (112 << 10));
if(m2 & 0x1000)
t++; // 四舍五入(尾数被截掉部分的最高位为1, 则尾数剩余部分+1)
half h = *(half*)(&t); // 强制转为half
return h ;
}
FP16 –> float
float nvHalf2Float(half n)
{
unsigned short frac = (n & 0x3ff) | 0x400;
int exp = ((n & 0x7c00) >> 10) - 25;
float m;
if(frac == 0 && exp == 0x1f)
m = INFINITY;
else if (frac || exp)
m = frac * pow(2, exp);
else
m = 0;
return (n & 0x8000) ? -m : m;
}
其他框架的典型如Tensorflow的float与FP16的转换方法:
float <–> FP16
class Float16Compressor
{
union Bits
{
float f;
int32_t si;
uint32_t ui;
};
static int const shift = 13;
static int const shiftSign = 16;
static int32_t const infN = 0x7F800000;//flt32 infinity
static int32_t const maxN = 0x477FE000;//max flt16 normal as a flt32
static int32_t const minN = 0x38800000;//min flt16 normal as a flt32
static int32_t const signN = 0x80000000;//flt32 sign bit
static int32_t const infC = infN>> shift;
static int32_t const nanN = (infC + 1) <<shift;//minimum flt16 nan as a flt32
static int32_t const maxC = maxN>> shift;
static int32_t const minC = minN>> shift;
static int32_t const signC = signN>> shiftSign;//flt16 sign bit
static int32_t const mulN = 0x52000000;//(1 <<23)/minN
static int32_t const mulC = 0x33800000;//minN/(1 <<(23 - shift))
static int32_t const subC = 0x003FF;//max flt32 subnormal down shifted
static int32_t const norC = 0x00400;//min flt32 normal down shifted
static int32_t const maxD = infC - maxC - 1;
static int32_t const minD = minC - subC - 1;
public:
static float decompress(uint16_t value)
{
Bits v;
v.ui = value;
int32_t sign = v.si & signC;
v.si ^= sign;
sign <<= shiftSign;
v.si ^= ((v.si + minD) ^ v.si) & -(v.si> subC);
v.si ^= ((v.si + maxD) ^ v.si) & -(v.si> maxC);
Bits s;
s.si = mulC;
s.f *= v.si;
int32_t mask = -(norC> v.si);
v.si <<= shift;
v.si ^= (s.si ^ v.si) & mask;
v.si |= sign;
return v.f;
}
static uint16_t compress(float value)
{
Bits v, s;
v.f = value;
uint32_t sign = v.si & signN;
v.si ^= sign;
sign>>= shiftSign; //logical shift
s.si = mulN;
s.si = s.f * v.f; //correct subnormals
v.si ^= (s.si ^ v.si) & -(minN> v.si);
v.si ^= (infN ^ v.si) & -((infN> v.si) & (v.si> maxN));
v.si ^= (nanN ^ v.si) & -((nanN> v.si) & (v.si> infN));
v.ui>>= shift; //logical shift
v.si ^= ((v.si - maxD) ^ v.si) & -(v.si> maxC);
v.si ^= ((v.si - minD) ^ v.si) & -(v.si> subC);
return v.ui | sign;
}
};
当我们手上有一个caffemodel的时候,怎么才能使用到TensorRT的FP16 Inference能力呢?
1). 下载nvcaffe并编译cmake -DTEST_FP16=ON
2). export PYTHONPATH=/the/path/to/your/caffe_root/python/
3). 修改模型文件prototxt:
a. 添加default_forward_type: FLOAT16到prototxt头部
b. 添加default_backward_type: FLOAT16到prototxt头部
4). 转换FP32模型成FP16兼容模式文件python genDefaultModel.py --input /path/to/net.prototxt --model /path/to/net_fp32.caffemodel --output /path/to/net_fp16.caffemodel
神经网络混合精度训练三种避免损失
https://zhuanlan.zhihu.com/p/84219777
之前介绍过了神经网络分布式训练,没怎么研究混合精度,以为就是都转成FP16就好了,最近才发现还是有些东西的,所以看了下百度和英伟达合作的MIXED PRECISION TRAINING,把细节记下来。
注意:小batch场景下混合精度并不能带来速度提升,甚至会更慢。因为小batch下的计算已经很快了,速度瓶颈在IO(在GPU和GPU间传送数据)。而混合精度需要进行FP16与FP32的转换,会消耗更多时间。
文中提出了三种避免损失的方法:
1.1. 为每个权重保留一份FP32的副本
在前向和反向时使用FP16,整个过程变成:权重从FP32转成FP16进行前向计算,得到loss之后,用FP16计算梯度,再转成FP32更新到FP32的权重上。这里注意得到的loss也是FP32,因为涉及到累加计算(参见下文)。
用FP32保存权重主要是为了避免溢出,FP16无法表示2e-24以下的值,一种是梯度的更新值太小,FP16直接变为了0;二是FP16表示权重的话,和梯度的计算结果也有可能变成0。实验表明,用FP16保存权重会造成80%的精度损失。
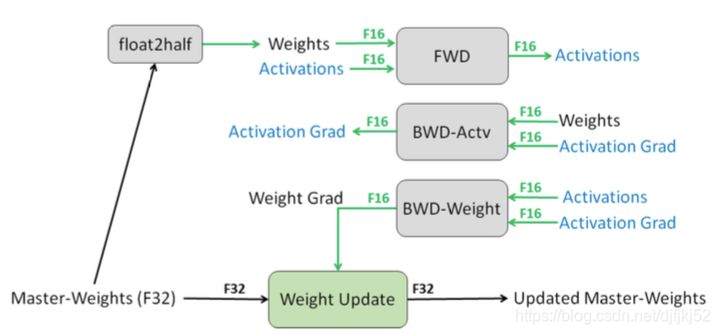
1.2. Loss-scaling
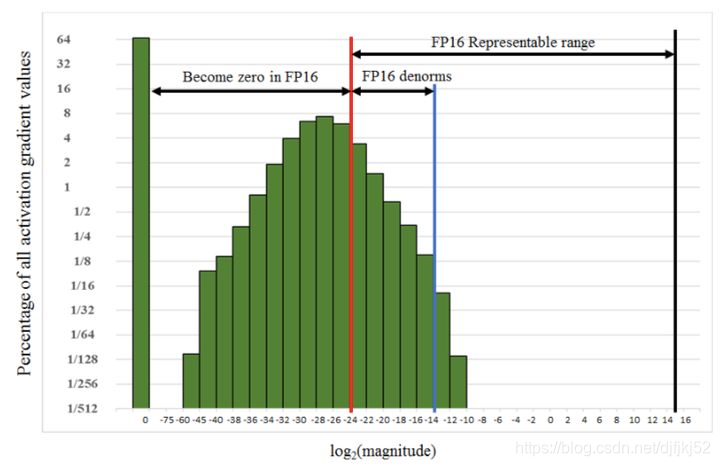
得到FP32的loss后,放大并保存为FP16格式,进行反向传播,更新时转为FP32缩放回来。下图可以看到,很多激活值比较小,无法用FP16表示。因此在前向传播后对loss进行扩大(固定值或动态值),这样在反响传播时所有的值也都扩大了相同的倍数。在更新FP32的权重之前unscale回去。
1.3. 改进算数方法:FP16 * FP16 + FP32。
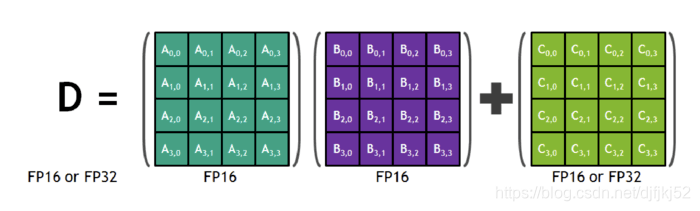
经过实验,作者发现将FP16的矩阵相乘后和FP32的矩阵进行加法运算,写入内存时再转回FP16可以获得较好的精度。英伟达V系列GPU卡中的Tensor Core(上图)也很支持这种操作。因此,在进行大型累加时(batch-norm、softmax),为防止溢出都需要用FP32进行计算,且加法主要被内存带宽限制,对运算速度不敏感,因此不会降低训练速度。另外,在进行Point-wise乘法时,用FP16或者FP32都可以,引用原文感受以下:
Point-wise operations, such as non-linearities and element-wise matrix products, are memory- bandwidth limited. Since arithmetic precision does not impact the speed of these operations, either FP16 or FP32 math can be used.
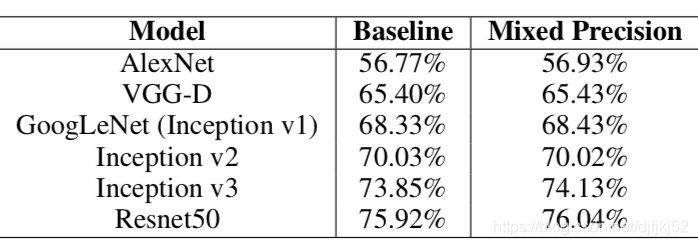
实验结果
从下图的Accuracy结果可以看到,混合精度基本没有精度损失:
Loss scale的效果:

如何应用MP
Pytorch可以使用英伟达的开源框架APEX,支持混合进度和分布式训练:
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
Tensorflow就更简单了,已经有官方支持,只需要训练前加一句:
export TF_ENABLE_AUTO_MIXED_PRECISION=1
# 或者
import os
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
https://developer.nvidia.com/automatic-mixed-precision
TensorRT模型转换及部署,FP32/FP16/INT8精度区分
TensorRT
1、简介
TensorRT 是一个深度学习模型线上部署的优化引擎,即 GPU Inference Engine。Tensor 表明张量,即数据流动以张量的方式,如4维张量 [N, C, H, W]。RT表示 runtime。
https://www.shangmayuan.com/a/cf71773c621a4ffb817c563a.html
在inference的阶段神经网络没有了后向传播,模型是固定的了,因此可以使得计算图有更好的优化 (graph optimazation)。同时输入输出大小固定了,简化了内存管理 (memory management)。为了实时性,可改用更小的batch size,以减小latency(可是同时GPU的利用率也下降了)。这些方面均可以在TensorRT中获得改进。
若是来自其余深度学习框架的模型中,有个别网络层比较新,TensorRT中暂不支持,用户能够经过TensorRT提供的API自定义本身的网络层。(具体可参见本文“流程”)
精度的下降能够大幅度加快神经网络模型的推理速度。
低精度技术 (high speed reduced precision)。在training阶段,梯度的更新每每是很微小的,须要相对较高的精度,通常要用到FP32以上。在inference的时候,精度要求没有那么高,通常F16(半精度)就能够,甚至能够用INT8(8位整型),精度影响不会很大。同时低精度的模型占用空间更小了,有利于部署在嵌入式模型里面。架构
英伟达显卡对精度的支持状况:框架
FP16 (Pascal P100 and V100 (tensor core))
INT8 (P4/P40)
其中V100采用 NVIDIA Volta 架构,相较于前代Pascal架构效率提高50%,拥有 640 个 Tensor Cores,tensor core的引入能够较高能效大幅增长浮点计算吞吐量。其中P4是专门线上作inference的一张小卡,功耗低。其余的还有T4显卡(含有Turing Tensor Cores,支持INT8/INT4精度,更快的inference)。

上面是各显卡低精度与单精度FLOPS的比较。FLOPS (Floating-point Operations per Second),每秒浮点运算次数,亦称每秒峰值速度。TFLOPS (teraFLOPS) ,1万亿 (10^12) 次的浮点运算每秒s
转换流程
TensorRT的流程主要分为模型解析、模型转换优化、模型执行三个步骤(以下图)。
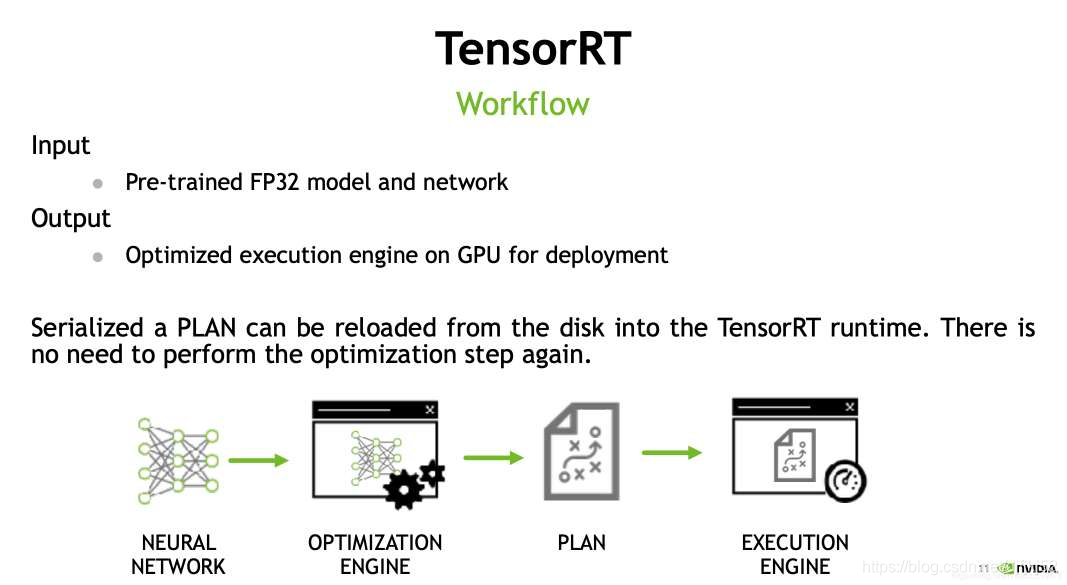
好比传入一个caffe模型,解析(Tensor中的Parser)就是获得模型里面有哪些网络层,有怎样的链接关系。而后对应得再转换成TensorRT的。可能有个别的比较新的网络层TensorRT中没有支持,用户能够经过API接口自定义layer,好比构建某种特殊卷积层。这个自定义API支持C++和Python语言。
目前支持的layer类型:

Parser如今支持:
caffe
uff(tensorflow可转换的一种模型文件结构)
ONNX (Open Neural Network Exchange),开放神经网络交换,对应Pytorch,caffe2等。
若是这些框架都不支持,还能够用TensorRT提供的API的,一层一层本身构建相应的神经网络。
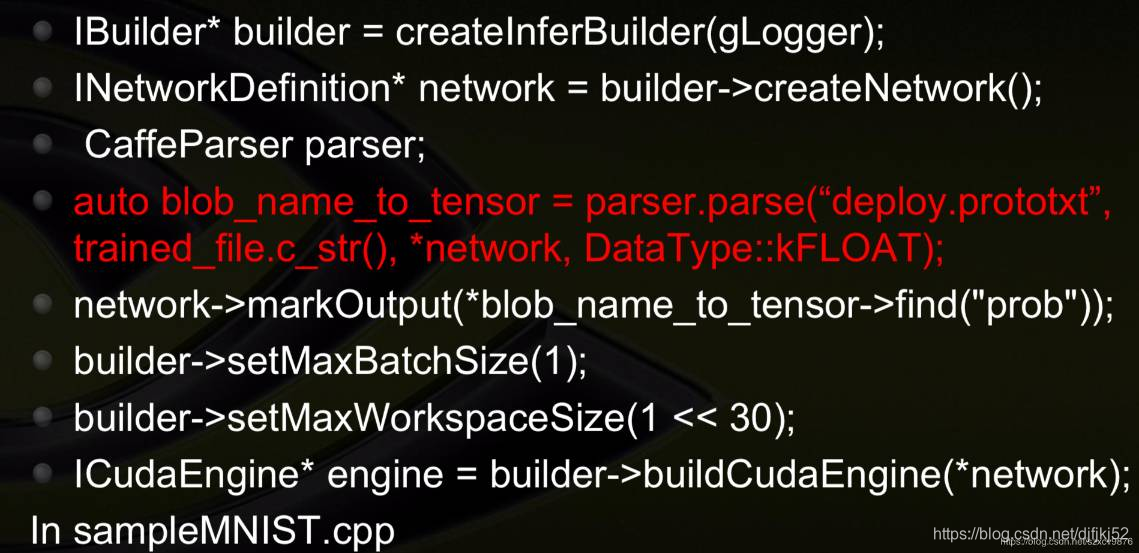
从Caffe导入神经网络的示例代码:
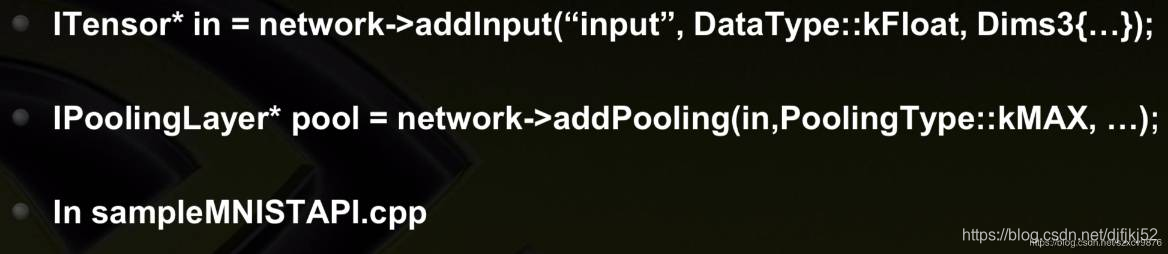
 从definition APIs导入神经网络的示例代码:
从definition APIs导入神经网络的示例代码:
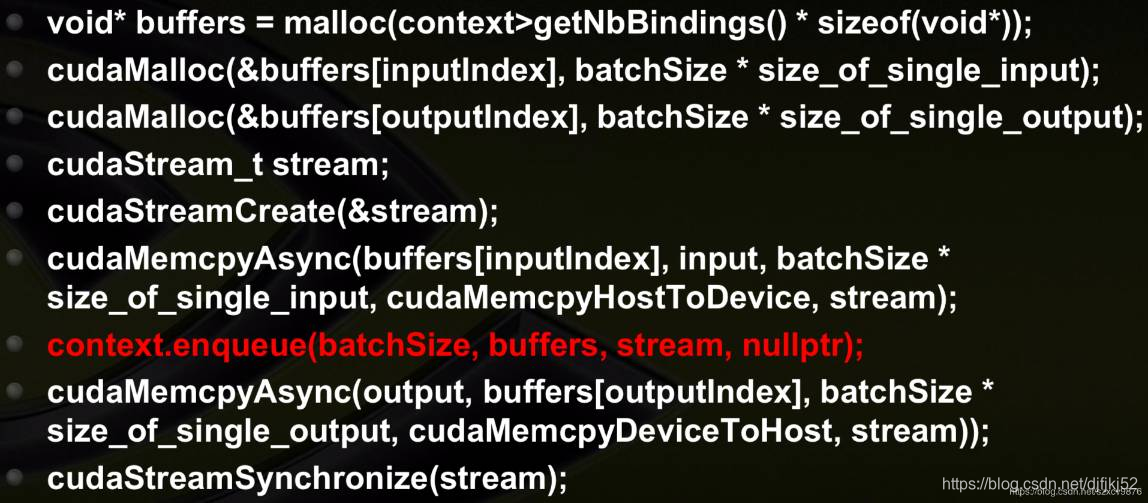
模型优化中,优化好的engine(上图中的PLAN),能够进行保存,能够序列化(serialization) 到一个buffer或者file里面。读的时候,再deserialization。具体优化策略看本文后面。
等到执行的时候,先建立一个context分配一些预先的资源,而后再执行新的优化好的模型。
示例代码:
自定义层
1、使用api创建自定义层
2、添加进入网络结构中。有两种方法,a、可以改变模型的解析文件,从模型解析角度区改变。b、使用addPlugin 的接口,在定义网络的时候区改变。

1、定义输出接口

2、配置层

3、初始化、终止操作api
 4、定义自定义层
4、定义自定义层

5、序列化层
 补充:在解析模型中增加自定义层
补充:在解析模型中增加自定义层
 补充:使用addPlugin 的接口,在定义网络的时候区改变。
补充:使用addPlugin 的接口,在定义网络的时候区改变。

优化策略
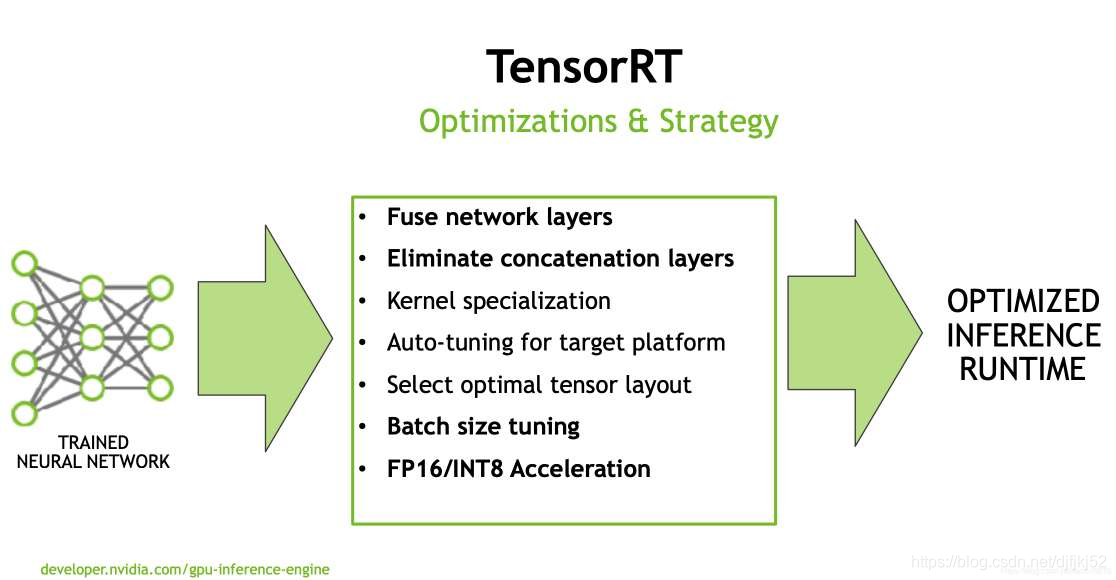
卷积、添加bias和激活函数(如,ReLu)这些操做是能够合并到一块儿的。多路径网络层相同部分能够合并。concat层是能够消除的。并行的卷积计算能够合并到一块儿。还有就是针对特定的平台,自动选择最好的layers和算法。同时支持可扩展的multi-stream输入的并行处理。
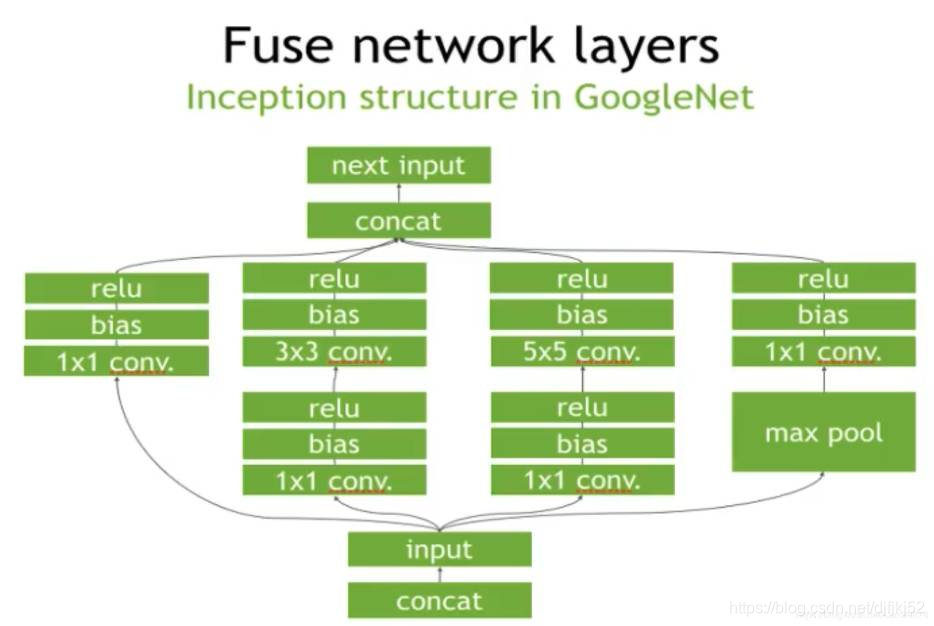
以下图Inception结构在TensorRT中的优化方式:
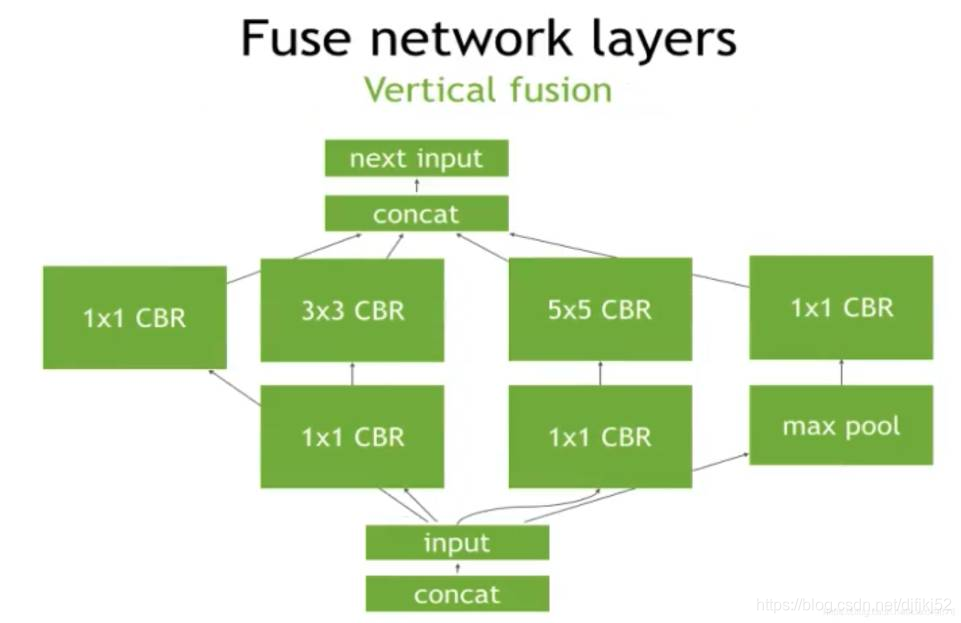
 1、垂直融合
1、垂直融合
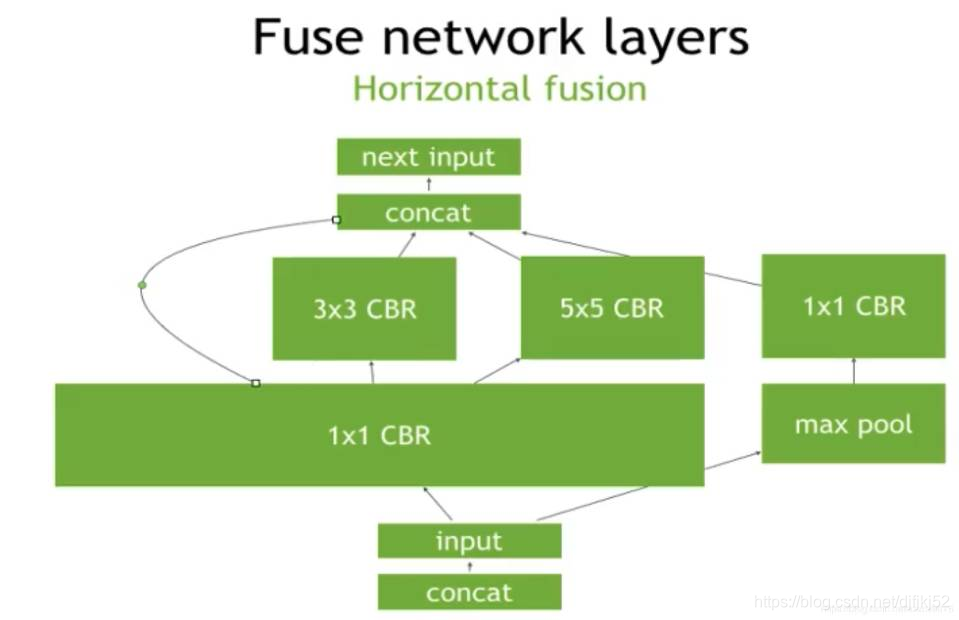
2、水平融合
 3、简化
3、简化
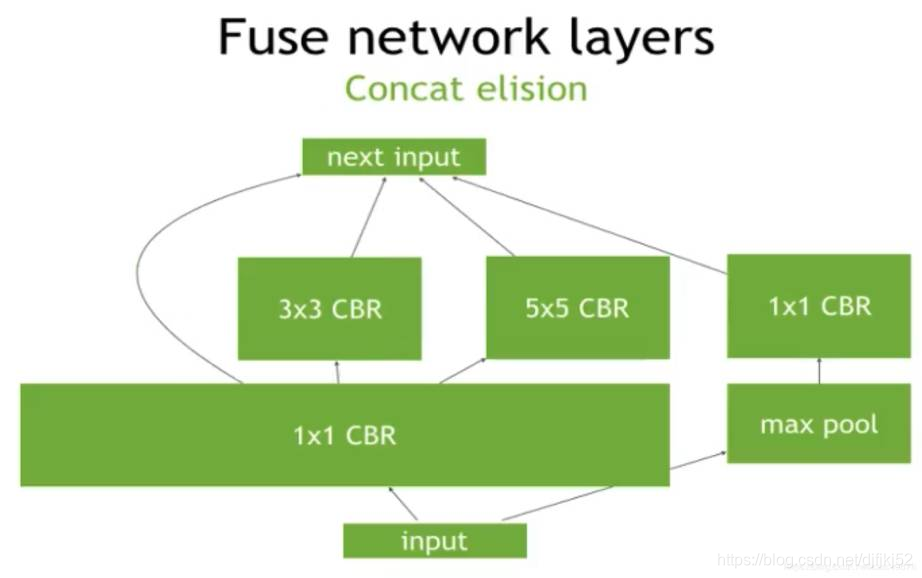
4、并发
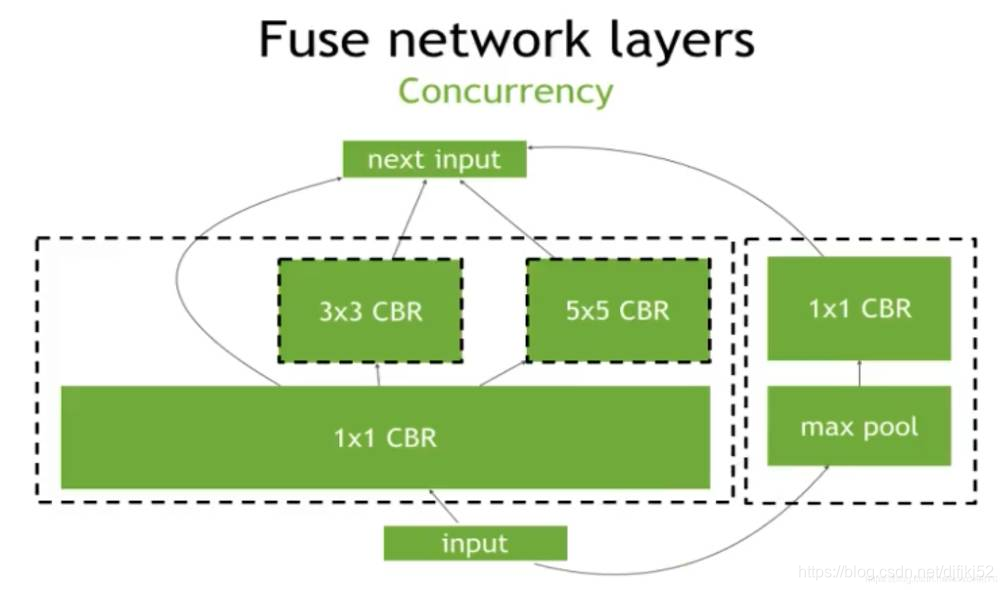
YOLOv2的模型优化策略:
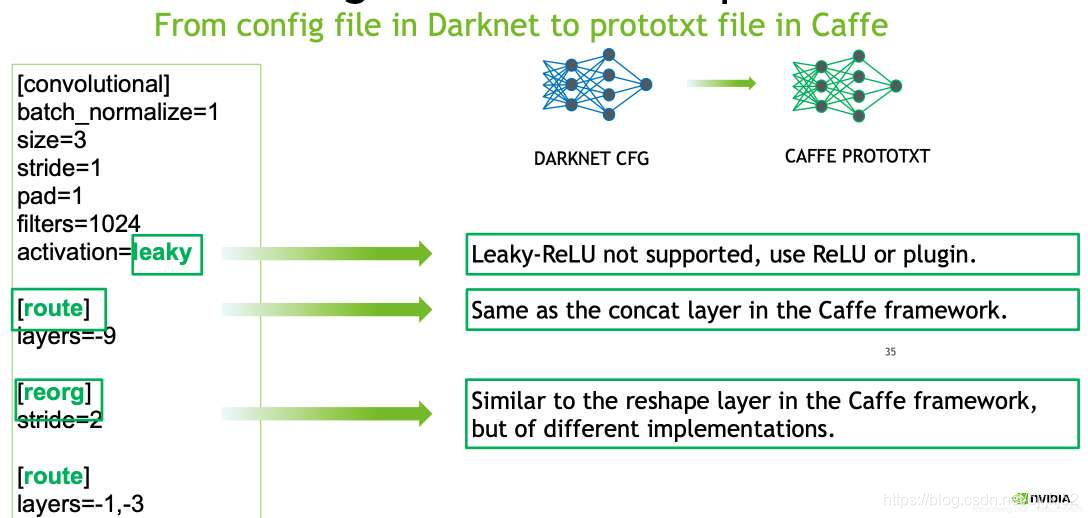
创建caffe 的模型格式的文件,把darknet转化过来。
使用ReLU 代替leaky-ReLU
不同的序列存储方式
不同的标准化层
不同的padding含义与实现方法

模型解析转换细节
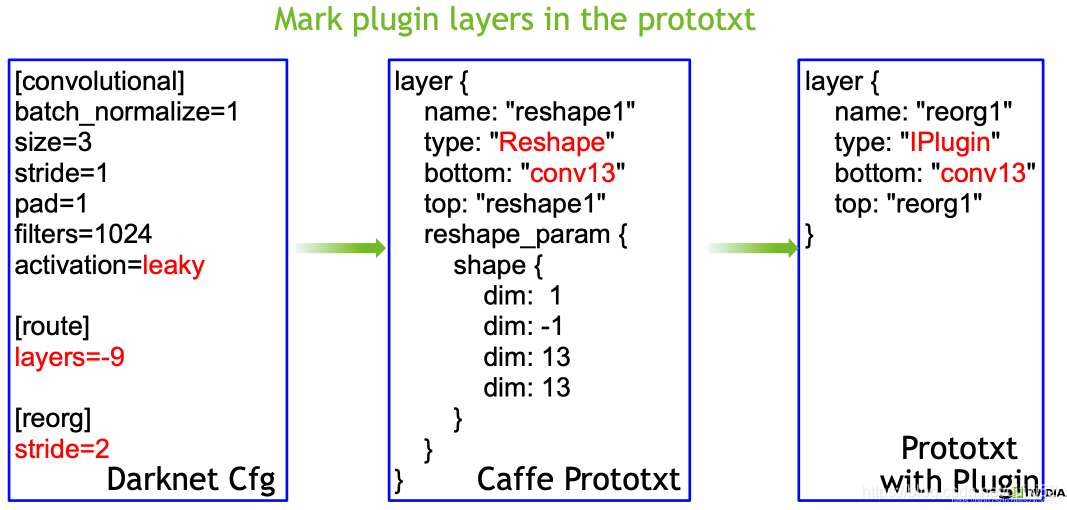
自定义插件
tensorRT 运行
https://www.jianshu.com/p/3c2fb7b45cc7
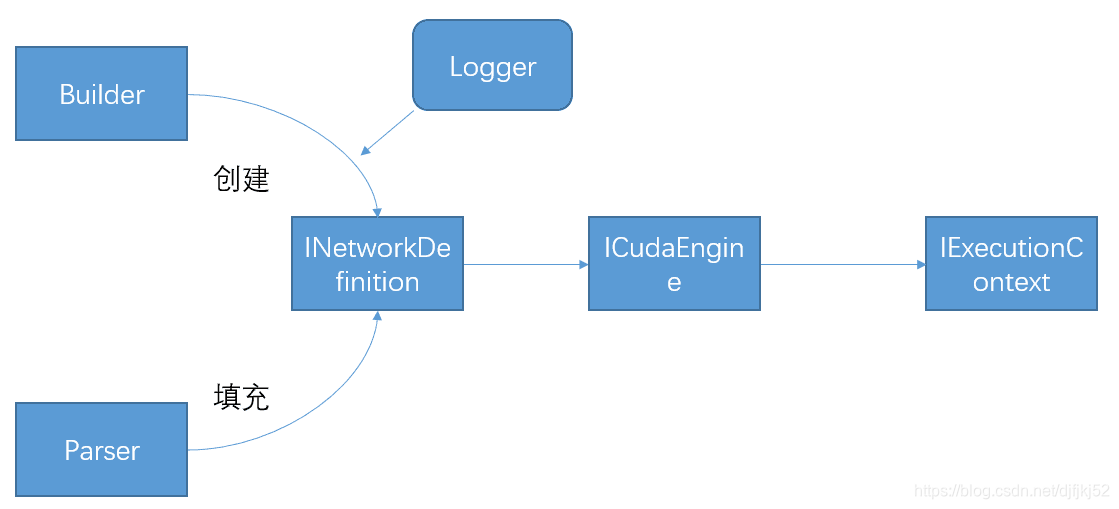
首先以trt的Logger为参数,使用builder创建计算图类型INetworkDefinition。
然后使用Parsers将onnx等网络框架下的结构填充计算图,当然也可以使用tensorrt的API进行构建。
由计算图创建cuda环境下的引擎
最终进行推理的则是cuda引擎生成的ExecutionContext。engine.create_execution_context()
我们可以通过下面python中调用tensorrt的实例代码看一些这个流程。
使用IExecutionContext进行推理的基本步骤:
先 进行空间分配,包括cuda上进行运算的输入输出缓存区间分配 cuda.mem_alloc
获得输入输出在cuda上的缓存地址,直接用int(input_mem)类似可获得
将输入数据由cpu复制到gpu: cuda.memcp_htod_async
执行引擎进行推理context.execute_async
将输出由cuda复制到cpu上,cuda.memcpy_dtoh_async
onnx使用python接口调用tensorrt
在了解了tensorrt创建推理环境的过程以及推理环境的使用方法后,就很容易理解
我们用另一篇文字来

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 15
15 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)