
2021-03-10自训练self-training
自训练,对未标注数据进行自适应采样。
文章[1],介绍了4篇顶会的self-training的文章。目录如下:
文章目录
- 01 What is self-training?
- 02 ICCV 2019 Confidence Regularized Self-Training
- 03 NeurlPS 2020 Uncertainty-aware Self-training for Text Classification with Few Labels
- 04 CVPR 2020 Self-Training With Noisy Student Improves ImageNet Classification
- 05 CVPR 2021 CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning
- 参考
01 What is self-training?
Self-training 是最简单的半监督方法之一,其主要思想是找到一种方法,用未标记的数据集来扩充已标记的数据集。算法流程如下:
-
利用已标记的数据来训练一个好的模型,然后使用这个模型对未标记的数据进行标记。
-
进行伪标签的生成,因为我们知道,已训练好的模型对未标记数据的所有预测都不可能都是好的,因此对于经典的 Self-training,通常是使用分数阈值(confidence score)过滤部分预测,以选择出未标记数据的预测标签的一个子集。
-
将生成的伪标签与原始的标记数据相结合,并在合并后数据上进行联合训练。
-
整个过程可以重复 n 次,直到达到收敛。
Self-training 最大的问题在就在于伪标签非常的 noisy,会使得模型朝着错误的方向发展。以下文章大多数都是为了解决这个问题。
02 ICCV 2019 Confidence Regularized Self-Training
论文标题:
Confidence Regularized Self-Training
论文链接:
https://arxiv.org/abs/1908.09822
代码链接:
https://github.com/yzou2/CRST
这篇文章通过对模型进行正则化,迫使输出的 vector 不那么 sharp(参考 label smooth 的作用),从而减轻使用软伪标签学习的伪标签不正确或模糊所带来的误导效果。
Main Contribution
该文的大致流程可见下图:

03 NeurlPS 2020 Uncertainty-aware Self-training for Text Classification with Few Labels
04 CVPR 2020 Self-Training With Noisy Student Improves ImageNet Classification
05 CVPR 2021 CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning
论文标题:
CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning
论文链接:
https://arxiv.org/abs/2102.09559
在类别不平衡的数据上施展半监督学习的研究很少,而这个问题又非常具有研究价值。该文章通过根据每个 class 样本数目对带伪标签的数据进行抽样,从而提升模型在少量样本上的表现。
Motivation
文章的出发点在于,我们通常认为样本少的类表现效果不好,但是这只是部分正确,从下图中我们可以看到,对于样本数目非常少的点,他只是 recall 非常的差,但是 precision 却出乎意料的高。这个发现促使我们去寻找一种方法来提升他的 recall。[precision, recall]

文章就提出了这样一种框架,与传统工作不同,我们对打上伪标签的数据根据类别多少来进行采样。

那么这里最重要的问题就是,我们怎么知道 unlabelled 数据中的类别信息?这里采取了简单的,从有标签样本中进行估计。对于一个被预测为 的 unlabelled 数据,它会被加入下一轮的训练集的概率为:
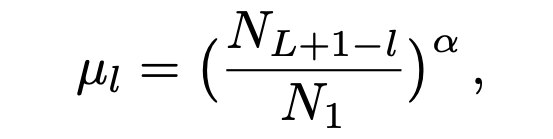
α
>
0
\alpha > 0
α>0 控制着采样频率。比如对 10- 分类问题,被分为第 10 类的所有样本(minority class)都会被选中 (文章假设了各个类是按照样本数目从多到少排序的),而第一类的样本(majority class)只有很少一部分被选中
这种做法有两个好处:1)因为 minority class 的预测精度都很高,因此将他们加入训练集合风险比较小;2)minority class 样本数目本来就少,对模型更加重要。
参考

鸿蒙生态一站式服务平台。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)