mysql in查询不要去重_MySQL 数据库(三):查
掌握 单表查询掌握 多表查询掌握 order by 排序方法掌握 in 查询用法掌握 like 模糊查询用法掌握 count() 统计用法掌握 group by 分组用法掌握 distinct 去重用法掌握 between 用法掌握 limit 方法掌握 mysql 常用函数掌握 select 语句查询结构掌握 左右内连接查询掌握单表查询不加条件的查询:查询特定字段,语法selectfrom ..
掌握 单表查询
掌握 多表查询
掌握 order by 排序方法
掌握 in 查询用法
掌握 like 模糊查询用法
掌握 count() 统计用法
掌握 group by 分组用法
掌握 distinct 去重用法
掌握 between 用法
掌握 limit 方法
掌握 mysql 常用函数
掌握 select 语句查询结构
掌握 左右内连接查询
掌握单表查询
不加条件的查询:
查询特定字段,语法select from ;
示例:
查询会员表里所有用户的手机号码和可用余额select MobilePhone, LeaveAmount from member:
查询所有字段:
语法
select * from :
示例
查询会员表的所有用户信息。select * from member;
掌握 多表查询
问题一:
对于不同类型的信息该怎么存储呢?是放一个表呢,还是不同类型数据放不同表。(结合仓库去理解)
放在一个表的缺点:
字段过多
难以维护
表数据庞大
数据冗余,重复数据多
问题二:
既然不同类型的数据放在了不同的表,那原本有联系的数据怎么保持原有的联系呢?
解决方案:
设计表的时候两个表之间维持一个关联即可。
掌握 order by 排序方法
对结果集进行排序 asc、desc
语法:select 查询字段名 from 表名 order by 字段名A asc 或 desc;select ... from ... order by 字段A asc(desc);select ... from ... order by 字段A asc(desc), 字段B asc(desc);==============
asc: 升序(默认)desc: 降序==============
示例:SELECT regname, leaveamount from member ORDER BY LeaveAmount desc;
掌握 in 查询用法
使用场景:查询的时候,条件字段的值存在于某个数据集
语法
select ... from 表名 where 条件字段 in (数据集)
数据集可以是具体的某几个值:值a, 值b.....值n;也可以是通过一个子查询 得到的数据集
示例
查询用户Id为1001,1002, 1003的用户信 息
select * from member where Id in(1001, 1002, 1003) ;
拓展
not in 的用法:条件字段的值不存在于某个数据集
查询用户Id不为1001, 1002,1003的用户
--查询会员 id 为 1,2,3,7,15 的会员信息;
SELECT * from member where id in (1,2,3,7,15);--查询会员 id 不为 1,2,3,7,15 的会员信息;
SELECT * from member where id not in (1,2,3,7,15);
掌握 like 模糊查询用法
like:模糊查询 “%xx”,“xx%”,“%xx%”
条件字段的值以任意字符串开头,以xx结尾的值---(大熊猫)
select from where like '%XX';select * from member WHERE RegName like "%猫";
条件字段的值以xx开头,以任意字符串结尾---(大熊猫)
select from where like 'XX%'
SELECT * from member where RegName like "大%";
条件字段的值包含了xx---(大熊猫)
select from where like '%XX%'
SELECT * from member where RegName like "%熊%";
掌握 count() 统计用法、group by 分组用法
使用场景:group by顾名思义就是按照某-一个,或者多个字段来分组,它必须有“聚合函数”来配合才能使用,使用时至少需要一个分组字段。 某某信息来进行分组
语法
select 查询字段,聚合函数 from 查询涉及到的表 group by 分组字段 having 过滤条件;
语法解释:
聚合函数:对一组值执行计算并返回单一的值的函数。聚合函数经常与 SELECT 语句的 GROUP BY子句一同使用
常见的聚合函数有:
sum(求和)、
count(计数)、
avg(平均数)、
min(最小)、
max(最大)
having:在分完组以后如果想在这个分组结果的基础上继续过滤的话就必须把过滤条件写在 having 后面
示例:
请按项目分组,统计投资表中各个项目的投资次数。
select LoanId, count() from invest GROUP BY LoanId;
理解:我感觉分组这里还是以理解为主,个人是按照这样理解的;
语法:select 查询字段,聚合函数 from 表名 group by 分组字段 having过滤条件;1、统计每个投资用户的累计投资额select查询字段,累计投资额from表名group by投资用户;2、统计每个投资用户的累计投资额,并且显示出每个用户的昵称
几张表?需要分组吗?有过滤条件吗?select查询字段,累计投资额from表名a,表名bwhere关联条件group by投资用户;3、统计a表每个投资用户的累计投资额,并且显示b表 id < 5的每个用户的昵称
几张表?需要分组吗?有过滤条件吗?select查询字段,累计投资额from表名a,表名bwhere关联条件group by投资用户having表名.id< 5;
示例:
语法select 查询字段,聚合函数 from 查询涉及到的表 group by 分组字段 having过滤条件;1、统计每个项目的平均投资额;SELECT * ,AVG(amount) from invest GROUP BYLoanId;2、扩展:统讦每个投资用户的累计投资额,并且显示出每个用户的昵称、id:
分析:
几张表==invest, member 关联?;要分组吗? 有条件过滤吗?SELECTmember.RegName,
member.id,SUM(invest.Amount)FROMinvest, memberWHEREinvest.MemberID=member.idGROUP BYinvest.MemberIDHAVINGmember.id< 10;
掌握 distinct 去重用法
使用场景:去除查询结果中的重复数据
语法:(译:抵死真可特)select distinct字段名1 from表名;
示例:
查询所有有投资的用户Idselect distinct MemberID from invest;
掌握 between 用法
使用场景:条件字段的取值处于两个数据范围内的情况
语法:select .... from 表名 where 条件字段 between 数值A and数值B;
示例:
id 在10到20 之间数据SELECT * from member where id BETWEEN 10 and 20;
掌握 limit 查询分页方法
使用场景:取查询结果的前n条
语法:select 查询字段 from表名 limit 开始m,每页显示几条;
m开始,n取几条
每页展示x条,取第 y页
x 乘(y-1),x
4页。20条20 乘 3,20
示例:
每页取十条展示。
第一页为: limit 0, 10 -----表示取索引从0开始取10条记录。
第二页为: limit 10, 10 -----表示取索引从10开始取10条记录。
第三页为: limit 20, 10 -----表示取索引从20开始取10条记录。
思考:
若每页展示x条数据,则取第y页时,分页语句中的m和n值分别为多少。
拓展:
请用sql将member表数据按照id降序排列后取前三条数据数据。
掌握 常用 mysql 函数
数值相关函数
求字段A的最小值:
min(字段A)
求字段A的最大值:
mag(字段A)
求字段A的平均值:
avg(字段A)
求字段A的和:
sum(字段A)
求字段A的最小值: min(字段A)SELECT min (Amount) frominvest;
求字段A的最大值:max(字段A)SELECT max (Amount) frominvest;
求字段A的平均值:avg(字段A)SELECT avg (Amount) FROMinvest;
求字段A的和:sum(字段A)SELECT sum (Amount) from invest;
掌握 select 语句查询结构
SELECT....FROM....WHERE....GROUP BY....HAVING....ORDER BY....
LIMIT
....
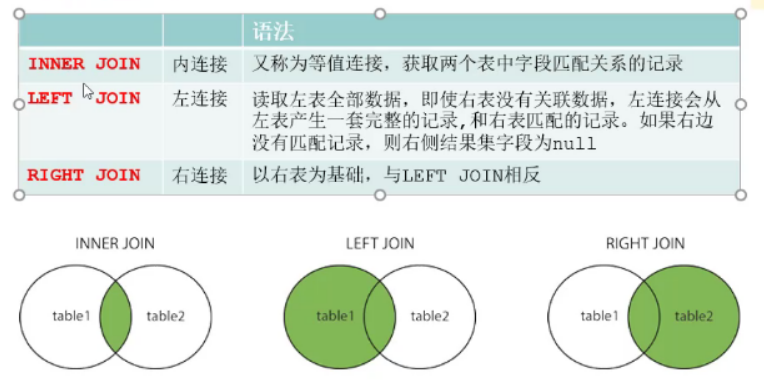
左右内外 连接查询
内连接为例语法:selecta.查询字段名,b.查询字段名froma表名inner join b表名 on关联关系;
示例:selecta.*, b.*
fromainner join b on a.id =b.parent_id;inner join内连接left join左连接right join右链接full join 完全链接
外连接,查询从表为空的数据
select * from emp as a left join dept as b on a.dept_id =b.idwhere b.id is null;
#on: (两张表如何关联) on在where之前
# 和where(结果集的基础上做条件筛选)的区别
*******请大家尊重原创,如要转载,请注明出处:转载自:https://www.cnblogs.com/shouhu/,谢谢!!*******

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)