
java id生成器 分布式_百度分布式Id生成器改造
百度的分布式ID,叫UidGenerator,Java实现, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中,支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。 在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成
百度的分布式ID,叫UidGenerator,Java实现, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中,支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。 在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费,同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题。 最终单机QPS可达600万(笔者跑测试用例只有70~90W,不知道这个数据咋跑的)。
为什么不根据雪花算法自己来实现一套?笔者对位移运算不是很熟,另外组件功力还没那么深厚,容易把组件写成bug。
其他详情参考官网,本片文章只说明对该项目的内部改造。
位数分配
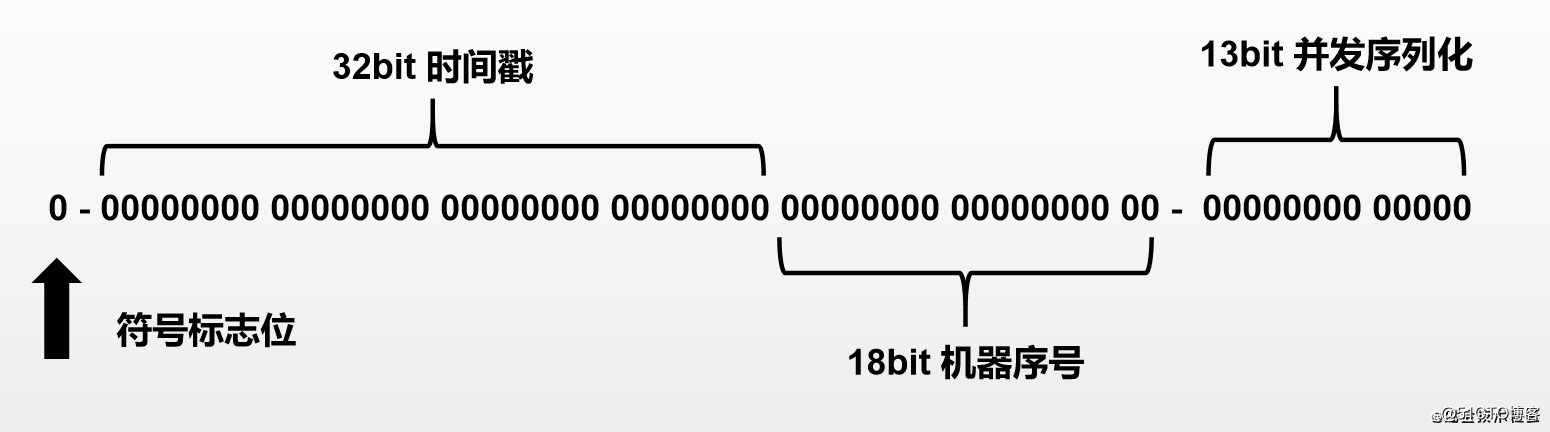 符号标志位,省不掉的
符号标志位,省不掉的
时间戳,雪花算法,41位的时间戳太长了,百度的28位太短了,在百度的28位之上,加上四位,使用时间变为五六十年
机器序号,原先雪花算法的10位只能支持一千台机器,百度的22位能支持420W台机器,一个太少、一个太多,中和一下就好啦,取18位,能支持20W台机器。笔者维护的是一个内部系统,机器比较少,而使用时间会很长,在内部,零几年的系统现在还在使用。
并发序列,内部系统,并发量还不是很大,13位已经能支持8000多的并发了
类图分析
总体类图:

从这个大类图中可以看到,原项目可以分为三个部分:
1、缓存生成器,一个高性能的ID生成器实现
2、默认生成器,雪花算法实现
3、WorkId分配器,为上面的两个生成器分配WorkId
默认生成器类图分析

UidGenerator:
生成器的接口,不过这个名字不适合在内部系统使用,得改一改,改成我们内部使用的规范。
DefautlUidGenerator :
雪花算法的默认实现,这个生成器存在并发限制。
BitsAllocator:
Id的位数分配、id生成。
WorkerIdAssigner:
WorkId的分配接口。我们系统的内部,WorkId要么是配置的,要么是依赖于另一个中心系统生成的。而该接口的实现是这么一坨:

这一部分完全不会用到。官网上也说了,这一部分可以被拿掉。那就干掉好了。
DateUtils:
日期工具类,查看该类的使用情况,可以看到该类主要是为了格式化时间而搞的,实际上可以用Java8的日期API代替,就再省掉一个类了。或者,集成进内部的话,这些配置都是可以写死的,没必要搞一个类。

简化后的类图:
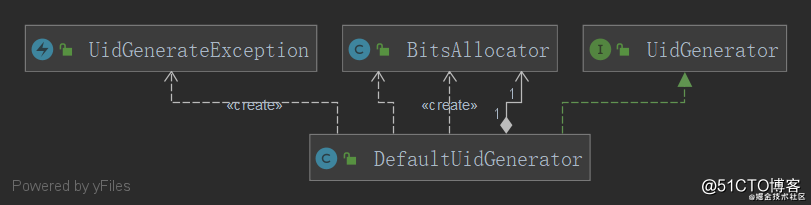
workId手动配置、只使用雪花算法的情况下,只需要四个类。
缓存生成器

缓存生成器,继承于默认生成器,所以上文的默认生成器是必须要予以实现的。
这个缓存生成器,是构建了一个环,存放id,一端消费id,一端生产id。
那生产赶上了消费怎么办?这时候会触发RejectedPutBufferHandler,该接口是一个函数式接口,实现在RingBuffer中,在源码中可以看到:
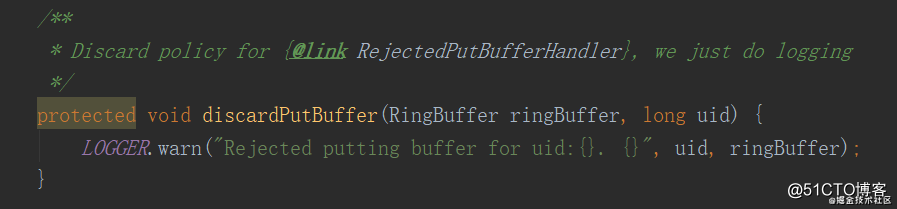
赶上了就打印一个警告,不继续生产了,也没啥好处理的。
那消费赶上了生产怎么办?这时候会出发RejectedTakeBufferHandler,该接口也是一个函数式接口,源码:

抛了一个运行时异常。这好像不太好,如果消费赶上了生产,那么就再获取一次就好了,干嘛要抛异常出来。。
抛了异常,影响业务逻辑呀!
这个地方需要改掉的,查看调用该方法的地方:public long take() {long currentCursor = cursor.get();long nextCursor = cursor.updateAndGet(old -> old == tail.get() ? old : old + 1);
Assert.isTrue(nextCursor >= currentCursor, "Curosr can't move back");long currentTail = tail.get();if (currentTail - nextCursor
LOGGER.info("Reach the padding threshold:{}. tail:{}, cursor:{}, rest:{}", paddingThreshold, currentTail,
nextCursor, currentTail - nextCursor);
bufferPaddingExecutor.asyncPadding();
}if (nextCursor == currentCursor) {
rejectedTakeHandler.rejectTakeBuffer(this);
}int nextCursorIndex = calSlotIndex(nextCursor);
Assert.isTrue(flags[nextCursorIndex].get() == CAN_TAKE_FLAG, "Curosr not in can take status");long uid = slots[nextCursorIndex];
flags[nextCursorIndex].set(CAN_PUT_FLAG);return uid;
}复制代码
把其中的if (nextCursor == currentCursor) {
rejectedTakeHandler.rejectTakeBuffer(this);
}复制代码
改成if (nextCursor == currentCursor) {
return take();
}复制代码
那么什么情况下,会调用RejectedTakeBufferHandler?该生成器中,消费超过一半的id,会触发生产任务。
而消费属于业务处理,速度是比较慢的。而生产只需要对环进行填充即可,速度很快,纳秒级别的响应。
所以,几乎不会调用RejectedTakeBufferHandler,亿万分之一的概率。
简化后的类图
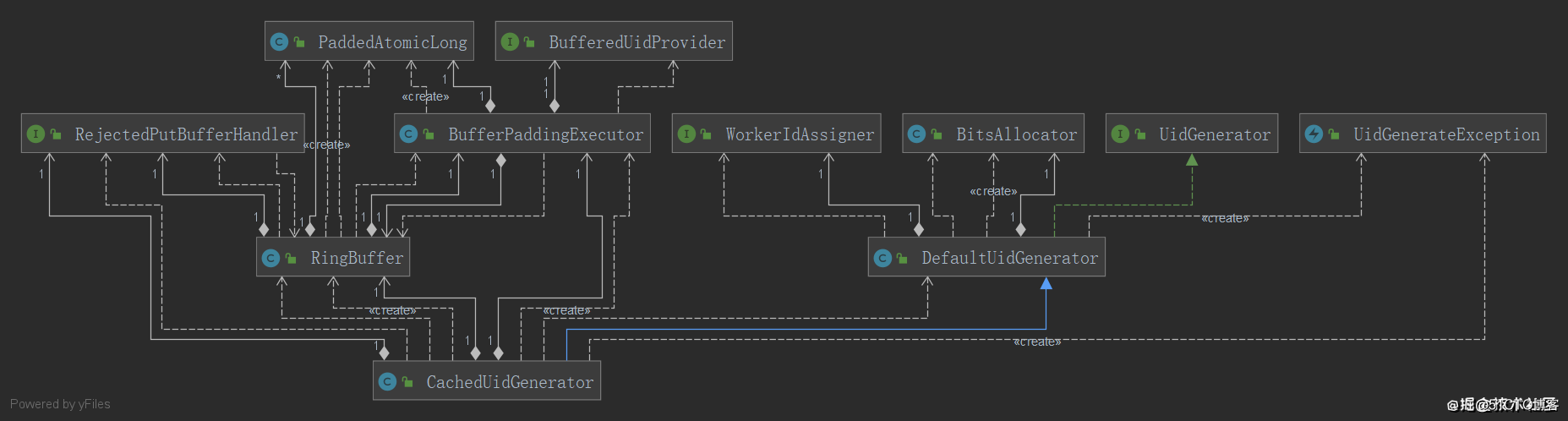
WorkerIdAssigner的实现设计到内部系统的逻辑,不做过多展示啦。剩下的类都是关键的部分,无法减法。
看这类图,集成进系统就比较简单了。

鸿蒙生态一站式服务平台。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)