
MySQL - 大量 sending data 状态进程,让数据库性能急剧下降。
问题现象日志库大量进程阻塞,导致服务不可用。日志库状况描述数据特点数据库是用于存储用户点击、激活、登录、付费等所有日志,使用了 Tokudb 存储引擎。特别是点击数据,现在已经达到 2亿 量级。进程状态当时登录到数据库中查询到有很多进程处于 Sending data 和 open table 状态,数据库处于极度阻塞的状态。Sending data 和 open table 状态的进程是来自 se
问题现象
日志库大量进程阻塞,导致服务不可用。
日志库状况描述
数据特点
数据库是用于存储用户点击、激活、登录、付费等所有日志,使用了 Tokudb 存储引擎。特别是点击数据,现在已经达到 2亿 量级。
进程状态
当时登录到数据库中查询到有很多进程处于 Sending data 和 open table 状态,数据库处于极度阻塞的状态。
Sending data 和 open table 状态的进程是来自 select 语句,加上其他 insert 语句带来的进程,数据库实时的进程数在百级别了(这里稍微记一下,后面分析open table会用到)。
机器状态
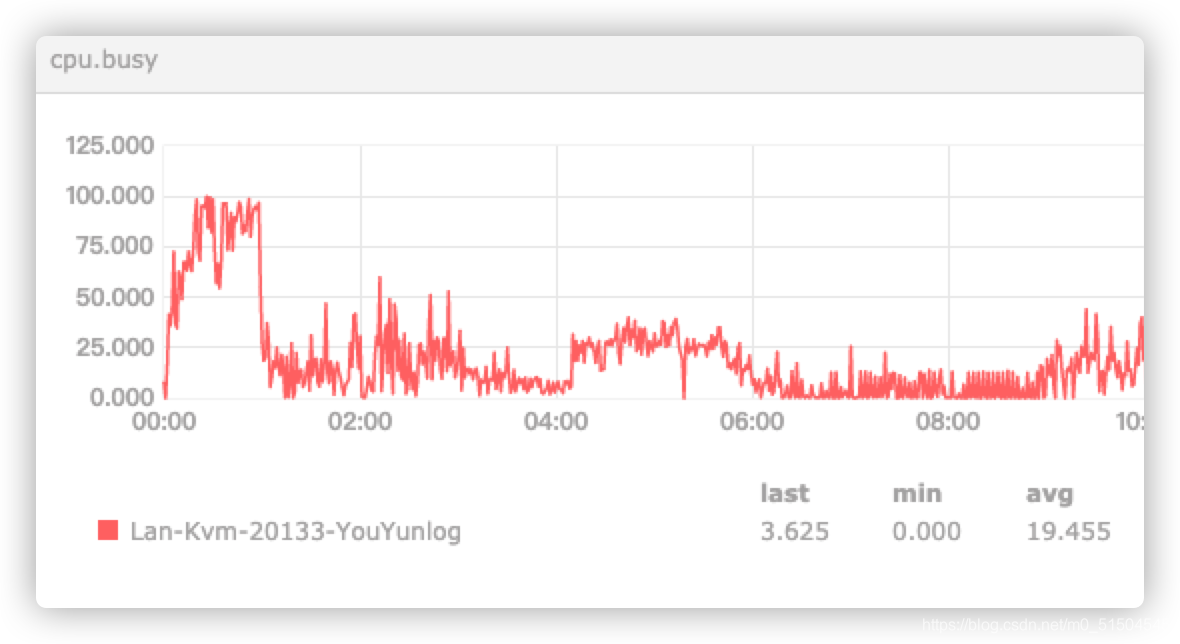
主要关注 00:00~00:57左右,这个时间cpu是处于一个十分繁忙的状态。因为此时数据库在进行大量的回表读操作(下面会分析到)。
00:57分后人工干预了,机器就瞬间恢复到正常水平。

但此时内存使用却是一天中的较低水平,这里没想清楚、
业务描述
上面处于 Sending data 和 open table 状态的进程都是来自同一个业务的查询。
eg:
select adv_position_id, id, pf, click_time, device_id, ua, channel, common_field from click_log where click_date >= '20210220' and pf = 1 and game_id = 200004426 and device_id in ('ffffffff-dcf1-4d3e-6036-c5de1c00c39e', '8fd962d037e694364092aee24c7cfd62', '8FD962D037E694364092AEE24C7CFD62', '', 'd41d8cd98f00b204e9800998ecf8427e', 'D41D8CD98F00B204E9800998ECF8427E', '863709034406035', 'acfeccc2df75e20f90be256cd33fa94e', 'ACFECCC2DF75E20F90BE256CD33FA94E');
这条语句会根据imei、oaid、device_id等多个纬度的不同的变形去找到对应的点击。原本是很简单的查询,但是耐不住量大。
以上述单体语句来说:符合这条查询的记录在20万左右。数据库同时有上百数据类似的语句同时查询。
这里插个题外话,这些点击基本上来自媒体:快手。这个倒不奇怪,快手这个媒体经常发很多很多的点击过来,一直怀疑这厮就是在撞归因。极度反感!
Sending data
在解析为什么很多进程卡在 Sending data 处先解释下 Sending data 是啥。这种状态的经常通常是来自 select 语句,一个简单的 select 会经历的阶段大致是如下:
THD::enter_stage: 'checking permissions'
THD::enter_stage: 'Opening tables'
THD::enter_stage: 'init'
THD::enter_stage: 'System lock'
THD::enter_stage: 'optimizing'
THD::enter_stage: 'statistics'
THD::enter_stage: 'preparing'
THD::enter_stage: 'executing'
THD::enter_stage: 'Sending data'
THD::enter_stage: 'end'
THD::enter_stage: 'query end'
THD::enter_stage: 'closing tables'
THD::enter_stage: 'freeing items'
Sending data 阶段数据库并不是单纯的发送数据,而是包括“收集 + 发送”过程。
发送是引擎把数据同步给数据库客户端,而收集则受查询使用索引区别有很大的影响。
- 不需要回表。如根据主键索引、联合索引(索引覆盖)查询,需要的数据就在索引树中。
- 需要回表。 上面的查询的语句不幸就是需要回表的。
回表就算了,查询中还有个字段(common_field)有点特殊,它是 varchar(1024)。
数据库有个操作是存储较长的字段时候,只会存储前768字节的长度,剩余的数据存放到“溢出页”中。这不就更雪上加霜!一旦采用了这种方式存储,返回数据的时候本来是顺序读取的数据,就变成了随机读取了,所以导致性能急剧下降。
我这边测试上述举例的语言原本需要十几秒,去掉common_field后,节省了几秒。
数据条数多、列数据长度加起来,就让单条查询需要花费十几秒以上。然后这些查询是3分钟一次的频率不停的查询,导致大量的进行处于 sending data 状态。
然后这并不是最糟的,不停的堆积引发了另一种状态 Opening tables 的产生。
Opening tables
当 open_tables 值大于 table_open_cache 值时,每次新的 session 打开表,有一些无法命中 table cache,而不得不重新打开表。这样反应出来的现象就是有大量的线程处于 opening tables 状态。
这个数据库总的在使用的表就7张,所以引发这种情况的原因就是大量的 Sending data 进程。
Opened_tables状态变量,该变量指示自服务器启动以来表打开操作的数量。
使用 SHOW GLOBAL STATUS LIKE ‘Opened_tables’;
+---------------+-------+
| Variable_name | Value
+---------------+-------
| Opened_tables | 38466 |
+---------------+-------+
而数据库设置的 table_open_cache 值是1024。为啥打开表数量那么多昵?
数据库使用的版本是 10.0.13-MariaDB,故直接看对应的 MySQL 5.6的文档即可。
N 代表所执行的任何查询中每个连接的最大表数。我这边虽然都是单表查询,但是数量取胜(session太多)。
故有着大量的 opening tables 状态进行的产生。
但我没这么做,我清楚这一切的产生都是 sql 的问题导致的。
总结
当时看到两种状态的大量进程存在,我原本是按照查询的阶段顺序看,所以先从 Opening tables 入手,然后发现不对。所以转头从 sending data 入手,最后基于对业务、机器的了解,完成了这次问题的排查。

无需安装部署,在线快速体验 Byzer
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)