
【论文解读 ACL 2020 | MixText】Linguistically-Informed Interpolation of Hidden Space for 半监督文本分类
论文题目:Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification论文来源:ACL 2020论文链接:https://www.aclweb.org/anthology/2020.acl-main.194/代码链接:https://github.com/GT-SALT/M

论文题目:Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
论文来源:ACL 2020
论文链接:https://www.aclweb.org/anthology/2020.acl-main.194/
代码链接:https://github.com/GT-SALT/MixText
关键词:半监督;数据增强;文本分类;Mixup;BERT
文章目录
1 摘要
本文提出了MixText,使用新提出的数据增强方法TMix,实现半监督的文本分类。
TMix通过将文本插入到隐藏空间中,构建了大量的增强训练样本。作者还使用数据增强的方法为无标签数据估计低熵标签。通过混合标签数据、无标签数据和增强数据,MixText在一系列文本分类任务上取得了很好的效果。
2 引言
已有的半监督文本分类方法可以分为以下几类:
1)使用VAEs重构句子并预测句子标签;
2)促使模型在无标注数据上输出预测用于自学习;
3)在加入对抗噪声或数据增强后,进行一致性训练;
4)使用无标注数据进行大规模的预训练,然后使用标注数据微调。
已有工作的不足:
大多数已有工作将标注数据和无标注数据区分对待,也就是监督信息不能从标注数据转移到无标注数据,反之亦然。
因此,大多数半监督模型很容易在非常有限的标注数据上过拟合,尽管无标注数据是充足的。

本文提出:
为了解决上述问题,受图像分类的Mixup[1,2]等方法的启发,本文提出了新的数据增强方法TMix。
如图 1所示,向TMix输入两个文本实例,并将他们插入到相应的隐藏空间中。TMix有潜力创建无限数量的新扩增数据样本,因此极大地避免了过拟合问题。
基于TMix,作者提出了用于文本分类的半监督学习模型MixTex来建模标注样本和无标注样本间的关联,克服了上述的其他半监督模型的局限性。
MixText首先为无标注数据预测低熵的标签,然后使用TMix插入标签数据和无标签数据。MixText可以挖掘句子之间的隐式关联,并在有标签的句子上进行学习时利用无标注的句子信息。同时,MixText利用了一些半监督学习的方法以进一步利用无标注的数据,包括self-target-prediction、entropy minimization和consistency regularization。
2 相关工作
1、Interpolation-based Regularizers
这类方法(例如Mixup)被提出应用于图像数据的有监督学习和半监督学习,并在图像分类等任务上实现了SOTA的效果。简单来说是将两张输入图像重叠并组合图像的标签,作为虚拟训练数据。
也有学者设计了这类方法的变形,例如在输入空间进行插值[3],在隐藏空间表示进行插值[4]。
但是这些插值方法还没有应用于NLP领域,因为大多数文本的输入空间是离散的,例如one-hot向量,和图像中连续的RGB数值不同;此外,文本在结构上更加复杂。
2、文本的数据增强
- 同义词替换、随机插入、随机交换、随机删除
- 重写
- 在无标注数据上应用back translations和单词替换以生成释义,用于一致性训练
3 TMix
作者将由[3]提出的用于图像的Mixup方法应用在文本建模上。
1、什么是Mixup
Mixup的核心思想:给定两个有标注的数据点 ( x i , y i ) , ( x j , y j ) (x_i, y_i), (x_j, y_j) (xi,yi),(xj,yj),其中 x x x是图像, y y y是标签的one-hot表示。通过如下的线性插值构造虚拟的训练样本:
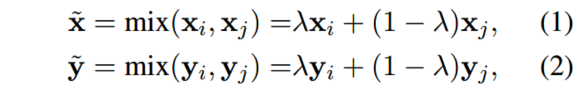
新构造的虚拟训练样本可用于训练神经网络模型。Mixup可以有多种解释:1)Mixup可以视为一种数据增强方法,也就是基于原始的训练集构造新的数据样本;2)Mixup强迫模型进行规范化,以实现在训练数据间的线性表现。
Mixup在连续的图像数据上有着较好的效果,然而将其扩展到文本是很有挑战性的,因为计算离散token的插值是不可行的。
2、将Mixup扩展到文本领域
作者提出新方法以解决上述在文本隐藏空间进行插值的挑战。首先,作者使用多层的模型例如BERT对句子进行编码。已有工作从两个隐藏向量的插值解码,生成混合了两个原始句子信息的新句子。受此工作启发,作者提出在隐藏空间进行插值作为文本的数据增强方法。对于有 L L L层的编码器,对第 m m m-th层的隐藏表示进行混合, m ∈ [ 0 , L ] m\in [0, L] m∈[0,L]。
(1)什么是TMix
如图 1所示,首先在底层分别计算两个文本的隐藏表示,然后在 m m m层混合隐藏表示,接着将插值过后的隐藏表示输入给上层。两个样本在低层的隐藏表示为:
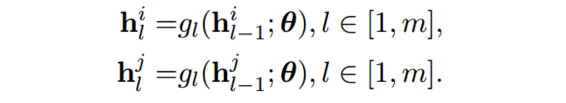
在第 m m m层的混合以及继续向上层传递定义为:

上述方法就称为TMix,将整个mixup操作定义成下式并得到 h ~ L \tilde{h}_L h~L:

(2)TMix和Mixup对比
和等式(1)描述的Mixup相对比,TMix依赖于编码器,因此插值计算的范围更广阔。为了简化,接下来将TMix形式化为 T M i x ( x i , x j ) TMix(x_i, x_j) TMix(xi,xj)。
(3) λ \lambda λ的选取
在实验中,每个batch都从Beta分布中采样混合参数 λ \lambda λ以进行插值,其中 α \alpha α是控制 λ \lambda λ分布的超参数:
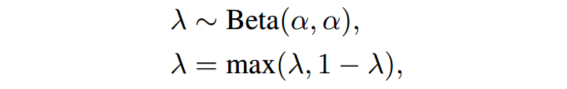
TMix在标签的混合上也采用等式(2)的方法,然后使用 ( h ~ L , y ~ ) (\tilde{h}_L, \tilde{y}) (h~L,y~)作为下游应用的输入。
(4)在哪层进行mixup
mixup哪层的隐藏表示是值得研究的问题。本文的实验中使用12层的BERT-base作为编码器。已有研究表明了BERT的不同层具有不同的表示能力。基于这些发现,作者使用同时包含了句法和语义信息的层作为混合层,即 M = { 7 , 9 , 12 } M={\{7, 9, 12}\} M={7,9,12}。对于每个batch,从 M M M中随机采样 m m m作为混合层的层数。
3、文本分类
TMix提供了一种通用的文本数据增强的方法,可以用于任意的下游任务中,本文只关注于文本分类任务。最小化混合标签和分类器预测的概率之间的KL散度作为损失:
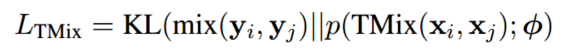
其中 p ( , : ϕ ) p(,: \phi) p(,:ϕ)是编码器上方的分类器。本文的实验中分类器是一个2层的MLP。
4 半监督MixText
1、明确任务
本节介绍如何使用TMix进行半监督学习。给定一个有限的带有标签的文本集合 X l = { x 1 l , . . . , x n l } X_l = {\{x^l_1, ..., x^l_n}\} Xl={x1l,...,xnl}和标签集合 Y l = { y 1 l , . . . , y n l } Y_l = {\{y^l_1, ..., y^l_n}\} Yl={y1l,...,ynl},以及大规模的无标签文本集合 X u = { x 1 u , . . . , x m u } X_u = {\{x^u_1, ..., x^u_m}\} Xu={x1u,...,xmu}。目标是有效地利用标注数据和无标注数据,学习得到分类器。
2、MixText
本文提出文本半监督学习框架MixText。核心思想是在有标签数据和无标签数据上利用TMix,以实现半监督学习。
作者提出标签猜测的方法,为无标签的数据猜测出一个标签,从而将这些无标签数据作为附加的标签数据,进行TMix后用于训练。此外,作者还将其他的数据增强技巧和TMix相结合,以生成大量的增强数据。最后,使用熵最小损失优化模型,鼓励模型在无标签样本上分配更加尖锐的概率分布。整体架构如图 2所示。

4.1 数据增强
使用back translation对无标签数据进行重写。对于无标签文本集合 X u X_u Xu中的每个 x i u x^u_i xiu,通过back translation并设置不同的中间语言,生成 K K K个增强样本 x i , k a = a u g m e n t k ( x i u ) , k ∈ [ 1 , K ] x^a_{i, k} = augment_k(x^u_i), k\in [1, K] xi,ka=augmentk(xiu),k∈[1,K]。
在增强文本的生成过程中,使用随机采样而不是beam搜索,以保证多样性。这些增强样本将被用于为无标签数据生成标签,接下来将详细介绍。
4.2 Label Guessing
给定一个无标签数据样本 x i u x^u_i xiu和他的 K K K个增强样本 x i , k a x^a_{i, k} xi,ka,使用如下的公式生成标签:

加权平均可能使得预测出的标签比较均衡,为了避免这一问题,使用如下的锐化函数让标签的分布更尖锐一些。其中 T T T是超参数,当 T → 0 T\rightarrow 0 T→0时,生成的标签就是one-hot向量。
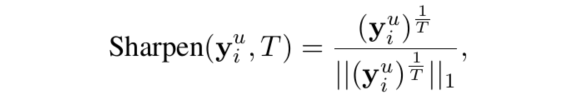
4.3 TMix on Labeled and Unlabeled Data
为无标签样本生成标签后,将有标签文本、无标签文本和无标签增强文本合并成一个大集合: X = X l ∪ X u ∪ X a , Y = Y l ∪ Y u ∪ Y a X = X_l \cup X_u\cup X_a, Y = Y_l\cup Y_u\cup Y_a X=Xl∪Xu∪Xa,Y=Yl∪Yu∪Ya。其中 Y a = { y i , k a } Y_a = {\{y^a_{i, k}}\} Ya={yi,ka},作者定义 y i , k a = y i u y^a_{i, k} = y^u_i yi,ka=yiu。
在训练时,随机采样两个数据点 x , x ′ ∈ X x, x^{'} \in X x,x′∈X,然后计算 T M i x ( x , x ′ ) , m i x ( y , y ′ ) TMix(x, x^{'} ), mix(y, y^{'} ) TMix(x,x′),mix(y,y′),并使用KL散度作为损失:

由于两个样本点是从 X X X中随机采样的,我们可以从不同的类别插值文本:混合有标签数据、混合有标签数据和无标签数据、混合无标签数据,基于样本的类型,损失可以划分为两类:
(1)有监督损失
当 x ∈ X l x\in X_l x∈Xl时,我们使用的大部分信息来自于有标签数据,因此使用有监督损失训练模型。
(2)一致性损失
当样本来自于无标签集合或者增强集合,即 x ∈ X u ∪ X a x\in X^u\cup X^a x∈Xu∪Xa,大多数信息来自于无标签数据。KL散度是一致性损失的一种。
4.4 Entropy Minimization
为了促使模型为无标签数据生成可信的标签,作者提出最小化预测概率的熵值作为自学习损失:
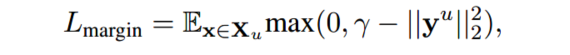
MixText最终的目标函数为:

5 实验
1、数据集

2、baselines
- VAMPIRE
- BERT
- UDA:无监督数据增强
3、实验结果



4、消融实验

6 总结
本文提出一个简单有效的半监督学习方法MixText,用于文本分类任务。本文还提出了一种基于插值的文本数据增强和规范化方法TMix。
未来工作:将MixText用于其他NLP任务,例如序列标注任务和其他标注数据有限的场景中。
本文的动机有两点:
(1)大多数半监督模型容易在有限的标注样本上过拟合;
(2)已有的半监督模型将有标注数据和无标注数据区分对待,不能建模两类数据间的关联。
本文提出:
(1)为了解决第一个问题,作者受图像领域的Mixup方法启发,提出一种新的文本数据增强的方法TMix,从而增加训练样本,避免过拟合问题。
由于文本类型的输入是不连续的one-hot向量,因此在文本领域应用mixup具有挑战。于是,作者使用了encoder(例如BERT),不在输入空间进行mixup,而是选择在实值的隐藏空间进行mixup。
(2)为了解决第二个问题,作者基于上述的TMix方法以及其他的数据增强方法,设计了半监督学习框架MixText,建模标注数据和无标注数据的关联。
对于无标注数据的处理:先使用back translation方法为每个无标注数据生成多个增强样本,然后利用这些样本猜测出该无标注数据的标签。为了使得标签的分布更加尖锐,还使用了锐化函数。将增强样本的标签定义为何该无标注样本的标签相同。
建模标注数据和无标注数据的关联:将标注数据、无标注数据和增强数据整合成一个大集合,随机采样两个样本点作为TMix的输入。由于TMix中有mixup的过程,自然也就建模了标注数据和无标注数据的关联。随机采样过程没有将有标注数据和无标注数据区别对待。
关于损失:损失一共有两部分,第一部分是针对TMix的损失,即标签mix和文本TMix的KL散度;第二部分是针对为无标注数据猜测标签的损失,也就是想让猜测出的标签的分布更加尖锐。
(3)关于数据增强
本文有两处数据增强,一处是使用TMix构建大量虚拟的训练样本,以避免过拟合问题;另一处是在MixText框架中,为了给无标签数据猜测标签,使用了back translation为其生成多个增强样本,从而利用这些增强样本为其猜测出标签。
本文的方法简单有效,其中受CV领域mixup方法启发的TMix方法的提出为NLP领域的数据增强提供了新思路。本文提出的半监督学习框架所使用的的损失值得学习,使用了KL散度,同时强调了猜测标签的分布锐化问题。
参考文献
[1] David Berthelot, Nicholas Carlini, Ian J. Goodfellow, Nicolas Papernot, Avital Oliver, and Colin Raffel. 2019. Mixmatch: A holistic approach to semisupervised learning. CoRR, abs/1905.02249.
[2] Suchin Gururangan, Tam Dang, Dallas Card, and Noah A. Smith. 2019. Variational pretraining for semi-supervised text classification. CoRR, abs/1906.02242.
[3] Hongyi Zhang, Moustapha Ciss´ e, Yann N. Dauphin, and David Lopez-Paz. 2017. mixup: Beyond empirical risk minimization. CoRR, abs/1710.09412.
[4] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. 2019. Cutmix: Regularization strategy to train strong classifiers with localizable features. CoRR, abs/1905.04899.

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)