
机器学习实验五 / 神经网络
实验五 神经网络代码已开源:https://github.com/LinXiaoDe/MachineLearning/tree/master/lab5参考链接https://blog.csdn.net/tangyuanzong/article/details/78922874https://blog.csdn.net/loveliuzz/article/details/78982928https:
实验五 神经网络
参考链接
-
https://blog.csdn.net/tangyuanzong/article/details/78922874
-
https://blog.csdn.net/loveliuzz/article/details/78982928
-
https://blog.csdn.net/fanxin_i/article/details/80212906
-
问题描述
公路运量主要包括公路客运量和公路货运量两个方面。据研究,某地区的公路运量主要与该地区的人口数量、机动车数量和公路面积有关。 下面数据表中给出了某地区公路运量相关数据。根据相关部门数据,该地区 2010 年和 2011 年的人口数量分别为 73.39 和75.55 万人,机动车数量分别为 3.9635 和 4.0975 万辆,公路面积将分别为 0.9880和 1.0268 万平方千米
- 实验要求
(1) 请利用 BP 神经网络预测该地区 2010 年和 2011 年的公路客运量和公路货运量。
(2) 请利用其他方法预测该地区 2010 年和 2011 年的公路客运量和公路货运量,并比较神经网络和其他方法的优缺点
- 数据集
| 年份 | 人口数量 | 机动车数量 | 公路面积 | 公路客运量 | 公路货运量 |
|---|---|---|---|---|---|
| 1991 | 22.44 | 0.75 | 0.11 | 6217 | 1379 |
| 1992 | 25.37 | 0.85 | 0.11 | 7730 | 1385 |
| 1993 | 27.13 | 0.9 | 0.14 | 9145 | 1399 |
| 1994 | 29.45 | 1.05 | 0.2 | 10460 | 1663 |
| 1995 | 30.1 | 1.35 | 0.23 | 11387 | 1714 |
| 1996 | 30.96 | 1.45 | 0.23 | 12353 | 1834 |
| 1997 | 34.06 | 1.6 | 0.32 | 15750 | 4322 |
| 1998 | 36.42 | 1.7 | 0.32 | 18304 | 8132 |
| 1999 | 38.09 | 1.85 | 0.34 | 19836 | 8936 |
| 2000 | 39.13 | 2.15 | 0.36 | 21024 | 11099 |
| 2001 | 39.99 | 2.2 | 0.36 | 19490 | 11203 |
| 2002 | 41.93 | 2.25 | 0.38 | 20433 | 10524 |
| 2003 | 44.59 | 2.35 | 0.49 | 22598 | 11115 |
| 2004 | 47.3 | 2.5 | 0.56 | 25107 | 13320 |
| 2005 | 52.89 | 2.6 | 0.59 | 33442 | 16762 |
| 2006 | 55.73 | 2.7 | 0.59 | 36836 | 18673 |
| 2007 | 56.76 | 2.85 | 0.67 | 40548 | 20724 |
| 2008 | 59.17 | 2.95 | 0.69 | 42927 | 20803 |
| 2009 | 60.63 | 3.1 | 0.79 | 43462 | 21804 |
实验过程
在本次实验中,我们小组实现了手工PB算法,对该地区 2010 年和 2011 年的公路客运量和公路货运量进行了预测。为比较不同算法之间的差异,丰富实验内容,我们实现了多元线性回归算法MLLR,后用使用sklearn实现SVM对结果进行预测。通过可视化实验结果,对不同算法进行了对比分析。
数据集处理
我们对将上表中的数据集保存为两种格式,一种为xls表格,另一种为csv文件,两种格式对应不同的读取方式,前者通过open_workbook打开并读取,后者通过readlines读取数据,最终返回xdata数据,和两组标签ydata1,ydata2即可,下面是对应实现。
- 读取xls
# 数据读取
def read_xls_file(filename): #读取训练数据
data = xlrd.open_workbook(filename)
sheet1 = data.sheet_by_index(0)
m = sheet1.nrows
n = sheet1.ncols
# 人口数量 机动车数量 公路面积 公路客运量 公路货运量
pop,veh,roa,pas,fre=[],[],[],[],[]
for i in range(m):
row_data = sheet1.row_values(i)
if i > 0:
pop.append(row_data[1])
veh.append(row_data[2])
roa.append(row_data[3])
pas.append(row_data[4])
fre.append(row_data[5])
dataMat = np.mat([pop,veh,roa])
labels = np.mat([pas,fre])
dataMat_old = dataMat
labels_old = labels
# 数据集合,标签集合,保留数据集合,保留标签集合
return dataMat,labels,dataMat_old,labels_old
- 读取csv文件
def loadData(): # 文件读取函数
f=open('./data/train.csv') # 打开文件
data = f.readlines()
print(data)
l=len(data) # mat为l*6的矩阵,元素都为0
mat=zeros((l,6))
index=0
xdata = ones((l,4)) #xdata为l*4的矩阵,元素都为1
ydata1,ydata2= [],[] #两列数据结果
for line in data:
line = line.strip() #去除多余字符
linedata = line.split(',') #对数据分割
mat[index, :] = linedata[0:6] #得到一行数据
index +=1
yearData = mat[:,0] # 得到年份
xdata[:,1] = mat[:,1] #得到第1列数据
xdata[:,2] = mat[:,2] #得到第2列数据
xdata[:,3] = mat[:,3] #得到第3列数据
ydata1 = mat[:,4] #得到第4列数据
ydata2 = mat[:,5] #得到第5列数据
return yearData,xdata,ydata1,ydata2
数据集处理好之后,我们就要实现不同的算法以实现最终的预测了。
1.手工BP
(1) 基本原理
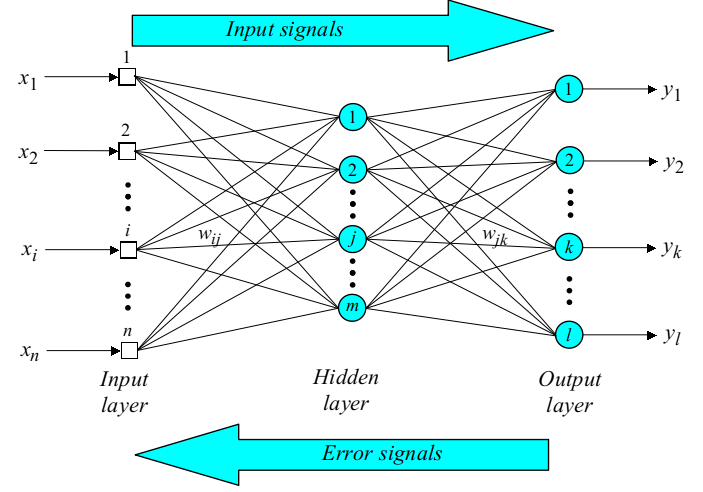
back propagation
- 算法思想:
训练数据输入到神经网络中,神经网络计算真实输出与实际输出之间的差异,然后通过调节权值来减小这种差异 - 两阶段
训练数据输入,通过前向层层计算到输出层输出结果
计算真实输出与实际输出之间的错误,通过反向从输出层-隐藏层-输入层的调节权值来减少错误
BP算法步骤:
- 第一步,初始化
设定初始的权值w1,w2,…,wn和阈值θ为如下的一致分布中的随机数
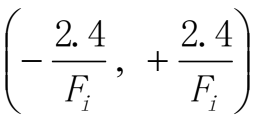
Fi是输入神经元数量总和
- 第二步:计算激活函数值
根据输入x1§, x2§,…, xn§ 和权值w1,w2,…,wn计算输出y1§, y2§,…, yn§
(a)计算隐藏层神经元的输出
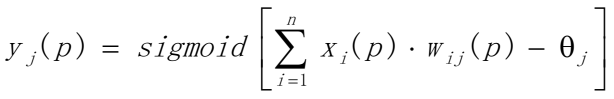
n是第j个隐藏层神经元的输入数量,sigmoid是激活函数
(b)计算输出层神经元的输出
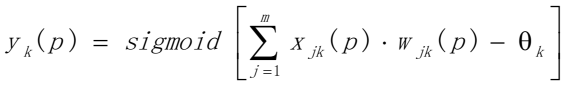
m是第k个输出神经元的输入数量
- 第三步:权值更新(从后往前)
(a)计算输出层的错误梯度
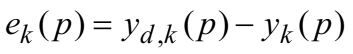
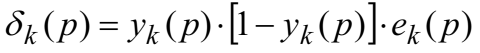
计算权值纠正值
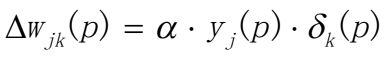
更新输出层的权值
(b)计算隐藏层的错误梯度

计算权值纠正值
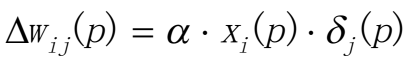
更新隐藏层的权值
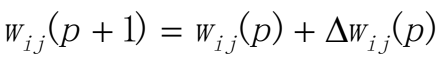
- 第四步:迭代循环
增加p值,不断重复步骤二和步骤三直到收敛
(2) 归一化处理
由于数据数量级相差太大,我们要先对数据进行归一化处理,常见的标准化方法有(0,1)标准化,Z-score标准化,Sigmoid标准化,这里我们采用(0,1)标准化:
x
n
o
r
m
a
l
i
z
a
t
i
o
n
=
x
−
μ
σ
{x}_{normalization}=\frac{x-\mu }{\sigma }
xnormalization=σx−μ
def Norm(dataMat,labels):
dataMat_minmax = np.array([dataMat.min(axis=1).T.tolist()[0],dataMat.max(axis=1).T.tolist()[0]]).transpose()
dataMat_Norm = ((np.array(dataMat.T)-dataMat_minmax.transpose()[0])/(dataMat_minmax.transpose()[1]-dataMat_minmax.transpose()[0])).transpose()
labels_minmax = np.array([labels.min(axis=1).T.tolist()[0],labels.max(axis=1).T.tolist()[0]]).transpose()
labels_Norm = ((np.array(labels.T).astype(float)-labels_minmax.transpose()[0])/(labels_minmax.transpose()[1]-labels_minmax.transpose()[0])).transpose()
return dataMat_Norm,labels_Norm,dataMat_minmax,labels_minmax
(3) 激活函数
激活函数我仍然选择的是Sigmoid函数,具有良好的阈值,在(0, 0.5)处中心对称,在(0, 0.5)附近有比较大的斜率,而当数据趋向于正无穷和负无穷的时候,映射出来的值就会无限趋向于1和0,是个人非常喜欢的“归一化方法”,之所以打引号是因为我觉得Sigmoid函数在阈值分割上也有很不错的表现,根据公式的改变,就可以改变分割阈值,这里作为归一化方法,我们只考虑(0, 0.5)作为分割阈值的点的情况:
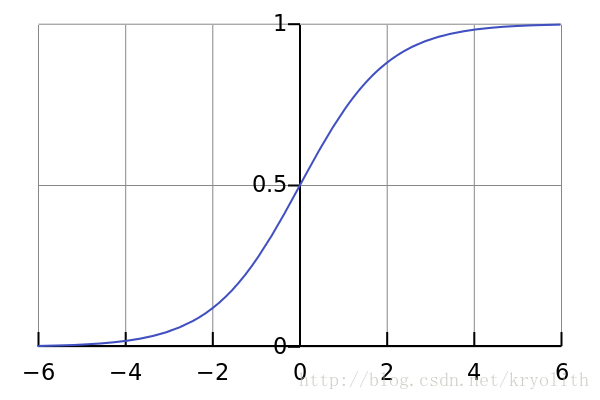
- 代码实现:
# 激活函数
def sigmod(x):
return 1/(1+np.exp(-x))
(4) Back Propagation反向传播实现
设计神经网络的结构
# 超参数
maxepochs = 60000 # 最大迭代次数
learnrate = 0.030 # 学习率
errorfinal = 0.65*10**(-3) # 最终迭代误差
indim = 3 # 输入特征维度3
outdim = 2 # 输出特征唯独2
# 隐藏层默认为3个节点,1层
- 黄金分割法
算法的主要思想:首先在[a,b]内寻找理想的隐含层节点数,这样就充分保证了网络的逼近能力和泛化能力。为满足高精度逼近的要求,再按照黄金分割原理拓展搜索区间,即得到区间b,c,在区间[b,c]中搜索最优,则得到逼近能力更强的隐含层节点数,在实际应用根据要求,从中选取其一即可。

我们确定了n=3, 输入层,l=2,输出层,m=(3+2)^1/2 = 2.449489743,由于alpha可以取1~10之间的数,所以我测试了以下几个层数2值,3, 4, 5,6,7,8最终对比训练结果,我选择了4个节点的中间层。
for i in range(maxepochs):
# 激活隐藏输出层
hiddenout = sigmod((np.dot(w1,sampleinnorm).transpose()+b1.transpose())).transpose()
# 计算输出层输出
networkout = (np.dot(w2,hiddenout).transpose()+b2.transpose()).transpose()
# 计算误差
err = sampleoutnorm - networkout
# 计算代价函数(cost function)sum对数组里面的所有数据求和,变为一个实数
sse = sum(sum(err**2))/m
errhistory.append(sse)
if sse < errorfinal: #迭代误差
break
# 计算delta
delta2 = err
delta1 = np.dot(w2.transpose(),delta2)*hiddenout*(1-hiddenout)
# 计算偏置
dw2 = np.dot(delta2,hiddenout.transpose())
db2 = 1 / 20 * np.sum(delta2, axis=1, keepdims=True)
dw1 = np.dot(delta1,sampleinnorm.transpose())
db1 = 1/20*np.sum(delta1,axis=1,keepdims=True)
# 更新权值
w2 += learnrate*dw2
b2 += learnrate*db2
w1 += learnrate*dw1
b1 += learnrate*db1
(5) 可视化训练情况
为了对训练情况有一个详细的了解,我将训练好的模型用训练集合进行预测,并且将真实 / 预测 公路客运量和真实 / 预测 公路货运量四条曲线绘制在一张图片上,除此之外,为了观察训练过程,我将训练的误差也绘制在图像中,下面是我可视化的代码核心部分:
def show(sampleinnorm,sampleoutminmax,sampleout,errhistory,maxepochs): # 图形显示
matplotlib.rcParams['font.sans-serif']=['SimHei'] # 防止中文乱码
networkout2[0] = networkout2[0]*diff[0]+sampleoutminmax[0][0]
networkout2[1] = networkout2[1]*diff[1]+sampleoutminmax[1][0]
sampleout = np.array(sampleout)
fig,axes = plt.subplots(nrows=2,ncols=1,figsize=(12,10))
line1, = axes[0].plot(networkout2[0],'k',markeredgecolor='b',marker = 'o',markersize=7)
line2, = axes[0].plot(sampleout[0],'r',markeredgecolor='g',marker = u'$\star$',markersize=7)
line3, = axes[0].plot(networkout2[1],'g',markeredgecolor='g',marker = 'o',markersize=7)
line4, = axes[0].plot(sampleout[1],'y',markeredgecolor='b',marker = u'$\star$',markersize=7)
axes[0].legend((line1,line2,line3,line4),(u'客运量预测输出',u'客运量真实输出',u'货运量预测输出',u'货运量真实输出'),loc = 'upper left')
axes[0].set_ylabel(u'公路客运量及货运量')
axes[1].set_xlabel(u'训练次数')
axes[1].set_ylabel(u'误差')
axes[1].set_title(u'误差曲线')
plt.savefig("./fig/BP6.png")
plt.show()
- 可视化结果:
BP神经网络
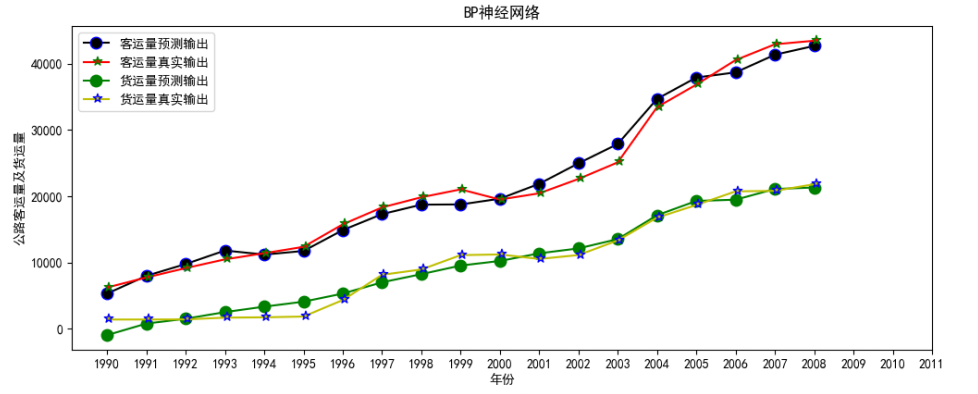
误差曲线
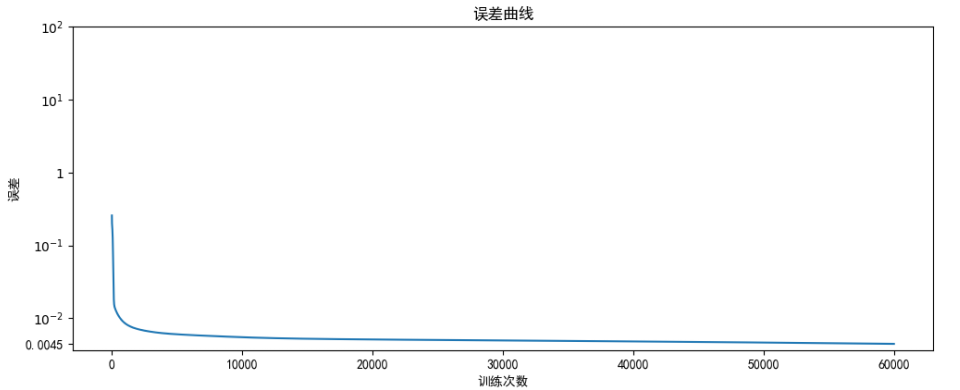
可以看到整体上预测数据和实际数据比十分吻合,训练误差收敛很快。
(6) 预测结果
为了对结果进行预测,我们要先将测试数据归一化,然后再作为神经网络的输入,然后计算两层的输出结果,进行预测
def pre(dataMat,dataMat_minmax,diff,sampleoutminmax,w1,b1,w2,b2): #数值预测
# 归一化数据
dataMat_test = ((np.array(dataMat.T)-dataMat_minmax.transpose()[0])/(dataMat_minmax.transpose()[1]-dataMat_minmax.transpose()[0])).transpose()
# 然后计算两层的输出结果
# 隐藏层
hiddenout = sigmod((np.dot(w1,dataMat_test).transpose()+b1.transpose())).transpose()
# 输出层
networkout1 = (np.dot(w2,hiddenout).transpose()+b2.transpose()).transpose()
networkout = networkout1
# 计算结果
networkout[0] = networkout[0]*diff[0] + sampleoutminmax[0][0]
networkout[1] = networkout[1]*diff[1] + sampleoutminmax[1][0]
print("2010年预测的公路客运量为:", int(networkout[0][0]),"(万人)")
print("2010年预测的公路货运量为:", int(networkout[1][0]),"(万吨)")
print("2011年预测的公路客运量为:", int(networkout[0][1]),"(万人)")
print("2011年预测的公路货运量为:", int(networkout[1][1]),"(万吨)")
-
预测结果:

-
结论:
2010年预测的公路客运量为: 54145 (万人),2010年预测的公路货运量为: 28907 (万吨),2011年预测的公路客运量为: 56138 (万人),2011年预测的公路货运量为: 30094 (万吨)。
2.线性回归
(1) 基本思路

这个代价函数是 x(i) 的估计值与真实值 y(i) 的差的平方和,前面乘上 1/2,是因为在求导的时候,这个系数就可以消去。
- 梯度下降法的流程:
1)首先对 θ 赋值,这个值可以是随机的,也可以让 θ 是一个全零的向量。
2)改变 θ 的值,使得 J(θ) 的值按梯度下降的方向减小。
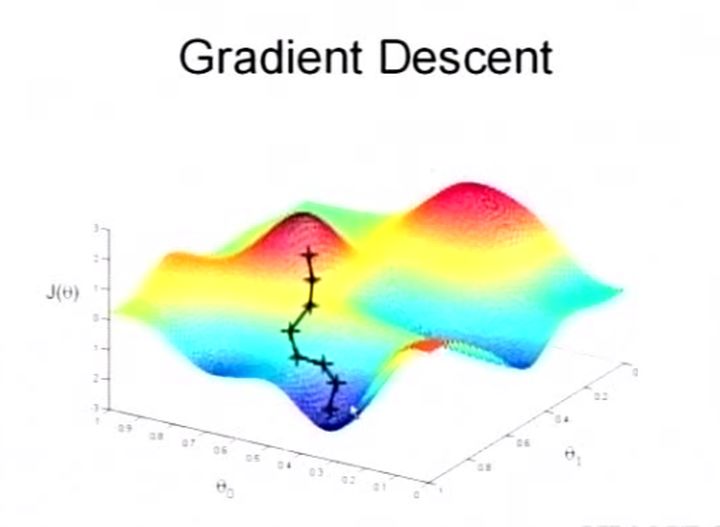 参数 θ 与误差函数 J(θ) 的关系图
参数 θ 与误差函数 J(θ) 的关系图
红色部分表示 J(θ) 有着比较高的取值,我们希望能够让 J(θ) 的值尽可能的低,也就是取到深蓝色的部分。θ0、θ1 表示 θ 向量的两个维度。上面提到梯度下降法的第一步,是给 θ 一个初值,假设随机的初值位于图上红色部分的十字点。然后我们将 θ 按梯度下降的方向进行调整,就会使 J(θ) 往更低的方向进行变化,如图所示,算法的结束将在 θ 下降到无法继续下降为止。
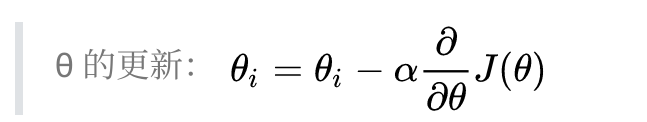
θi 表示更新前的值,减号后边的部分表示按梯度方向减少的量,α 表示步长,也就是每次按梯度减少的方向变化多少。
梯度是有方向的,对于一个向量 θ,每一维分量 θi 都可以求出一个梯度的方向,我们就可以找到一个整体的方向,在变化的时候,我们就朝着下降最多的方向进行变化,就可以达到一个最小点,不管它是局部的还是全局的。
算法步骤
-
代价函数J(θ)的变量是θ,迭代过程中,使用:
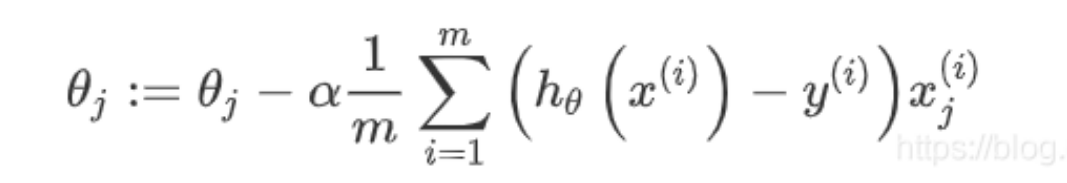
对θ进行迭代,不断更新 θ的值,同时记录代价函数cost,预计cost将会在迭代过程中不断趋近一个稳定值。
-
检查梯度下降:是打印出每一步代价函数J(θ)的值,看他是不是一直都在减小,并且最后收敛至一个稳定的值。
-
θ最后的结果会用来预测。
(2) 归一化数据
由于数据数量级相差太大,我们要先对数据进行归一化处理,常见的标准化方法有(0,1)标准化,Z-score标准化,Sigmoid标准化,这里我们采用(0,1)标准化:
x
n
o
r
m
a
l
i
z
a
t
i
o
n
=
x
−
μ
σ
{x}_{normalization}=\frac{x-\mu }{\sigma }
xnormalization=σx−μ
# 归一化数据
def Min_Max(xdata): #归一化数据
index = 1
while index < len(xdata[0,:]):
item = xdata[:,index].max()
item1 = xdata[:,index].min()
xdata[:,index] = (xdata[:,index] - item1)/(item-item1) #归一化数据
index = index+1
return xdata
(3) 代价函数
计算公式:
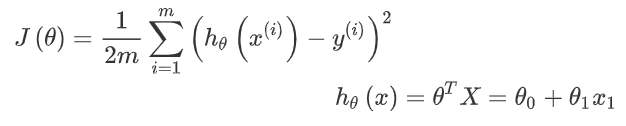
J(θ)为代价函数,h(θ)(x)为线性回归给出的结果,(表达式为2D线性线性回归模型),θi是迭代模型,用于做迭代处理,采用向量化的形式进行计算以优化计算速度,然后:根据上述的回归方程,定义代价函数:
# 代价函数
def cost(theta,xdata,ydata,l): #代价函数
SUM = 0
idex = 0
ydata = mat(ydata)
ydata = ydata.T
for line in ydata:
yp = model(theta,xdata[idex ,:])
yp = yp - ydata[idex ,:]
yp = yp**2
SUM = SUM + yp
idex =idex +1
return SUM/2/l #返回代价
(4) 梯度下降求解
- 代价函数J(θ)的变量是θ,迭代过程中,使用:
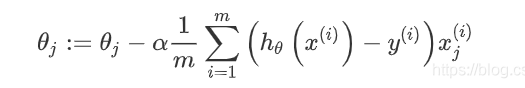
对θ进行迭代,不断更新 θ的值,同时记录代价函数cost,预计cost将会在迭代过程中不断趋近一个稳定值。
-
检查梯度下降:是打印出每一步代价函数J(θ)的值,看他是不是一直都在减小,并且最后收敛至一个稳定的值。
-
θ最后的结果会用来预测。
def OLS(xdata,ydata): #梯度下降求解函数
theta = [0,0,0,0]
iters = 0
iters = int(iters)
l = len(ydata)
l = int(l)
cost_record = []
it = []
sigmal = 0.1
cost_val = cost(theta,xdata,ydata,l) #计算代价
cost_record.append(cost_val)
it.append(iters)
while iters <1500:
theta = gradlient(theta,xdata,ydata,sigmal,l) #计算梯度
cost_updata = cost(theta,xdata,ydata,l) #计算代价
iters = iters + 1
cost_val = cost_updata
cost_record.append(cost_val)
it.append(iters)
return mat(theta).T,cost_record,it,theta
(5) 可视化训练情况
为了对训练情况有一个详细的了解,我将训练好的模型用训练集合进行预测,并且将真实 / 预测 公路客运量和真实 / 预测 公路货运量四条曲线绘制在一张图片上,除此之外,为了观察训练过程,我将训练的误差也绘制在图像中,下面是我可视化的代码核心部分:
def show(pre1,pre2,ydata1,ydata2): # 图形显示
matplotlib.rcParams['font.sans-serif']=['SimHei'] # 防止中文乱码
fig,axes = plt.subplots(figsize=(12,10))
line1, = axes.plot(pre1,'k',markeredgecolor='b',marker = 'o',markersize=9)
line2, = axes.plot(ydata1,'r',markeredgecolor='g',marker = u'$\star$',markersize=9)
line3, = axes.plot(pre2,'g',markeredgecolor='g',marker = 'o',markersize=9)
line4, = axes.plot(ydata2,'y',markeredgecolor='b',marker = u'$\star$',markersize=9)
axes.legend((line1,line2,line3,line4),(u'客运量预测输出',u'客运量真实输出',u'货运量预测输出',u'货运量真实输出'),loc = 'upper left')
axes.set_ylabel(u'公路客运量及货运量')
xticks = range(0,22,1)
xtickslabel = range(1990,2012,1)
axes.set_xticks(xticks)
axes.set_xticklabels(xtickslabel)
axes.set_xlabel(u'年份')
axes.set_title(u'多元线性回归MLR')
plt.savefig("./fig/MLR.png")
plt.show()
plt.close()
- 下面是训练过程的预测:
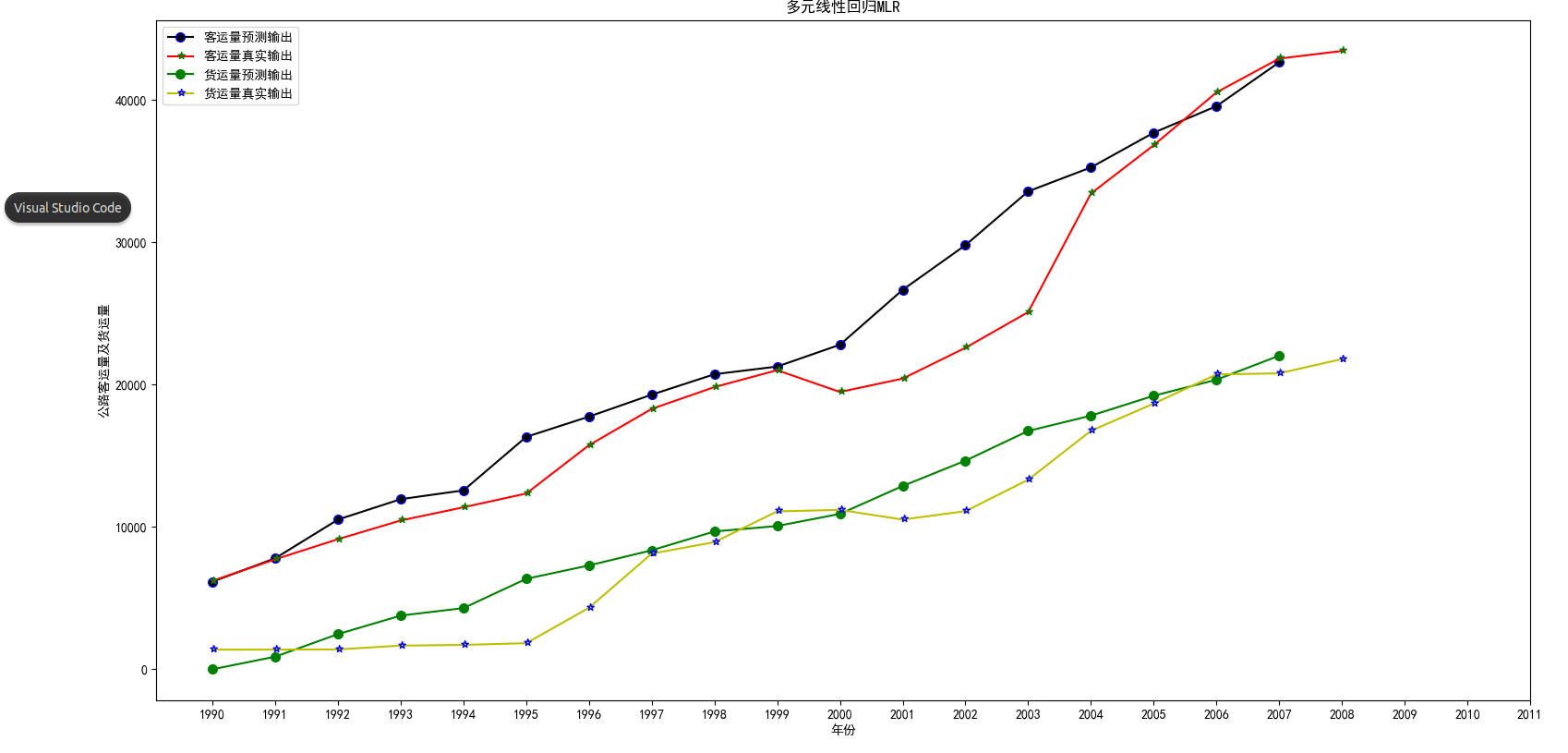
可以看到整体上呈现线性的趋势,但是在局部数据预测有较大的差异,误差较大。
(6) 预测结果
为了对结果进行预测,我们要先将测试数据归一化,然后再作为参数代入直线方程:
test1 = [1,73.39,3.9635,0.9880]
test2 = [1,75.55,4.0975,1.0268]
test1=Normal(test1,xcopy)
print("2010年预测的公路客运量为:", (test1*ws1)[0,0],"(万人)")
print("2010年预测的公路货运量为:", (test1*ws2)[0,0],"(万吨)")
test2=Normal(test2,xcopy)
print("2011年预测的公路客运量为:", (test2*ws1)[0,0],"(万人)")
print("2011年预测的公路货运量为:", (test2*ws2)[0,0],"(万吨)")
-
预测结果:

-
结论
2010年预测的公路客运量为: 54959.57130453731 (万人),2010年预测的公路货运量为: 29751.27273227173 (万吨),2011年预测的公路客运量为: 57130.95514474473 (万人),2011年预测的公路货运量为: 31066.13408367608 (万吨)和神经网络预测结果相近。
3.基于sklearn实现SVM支持向量积。
Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。
- sklearn库的结构
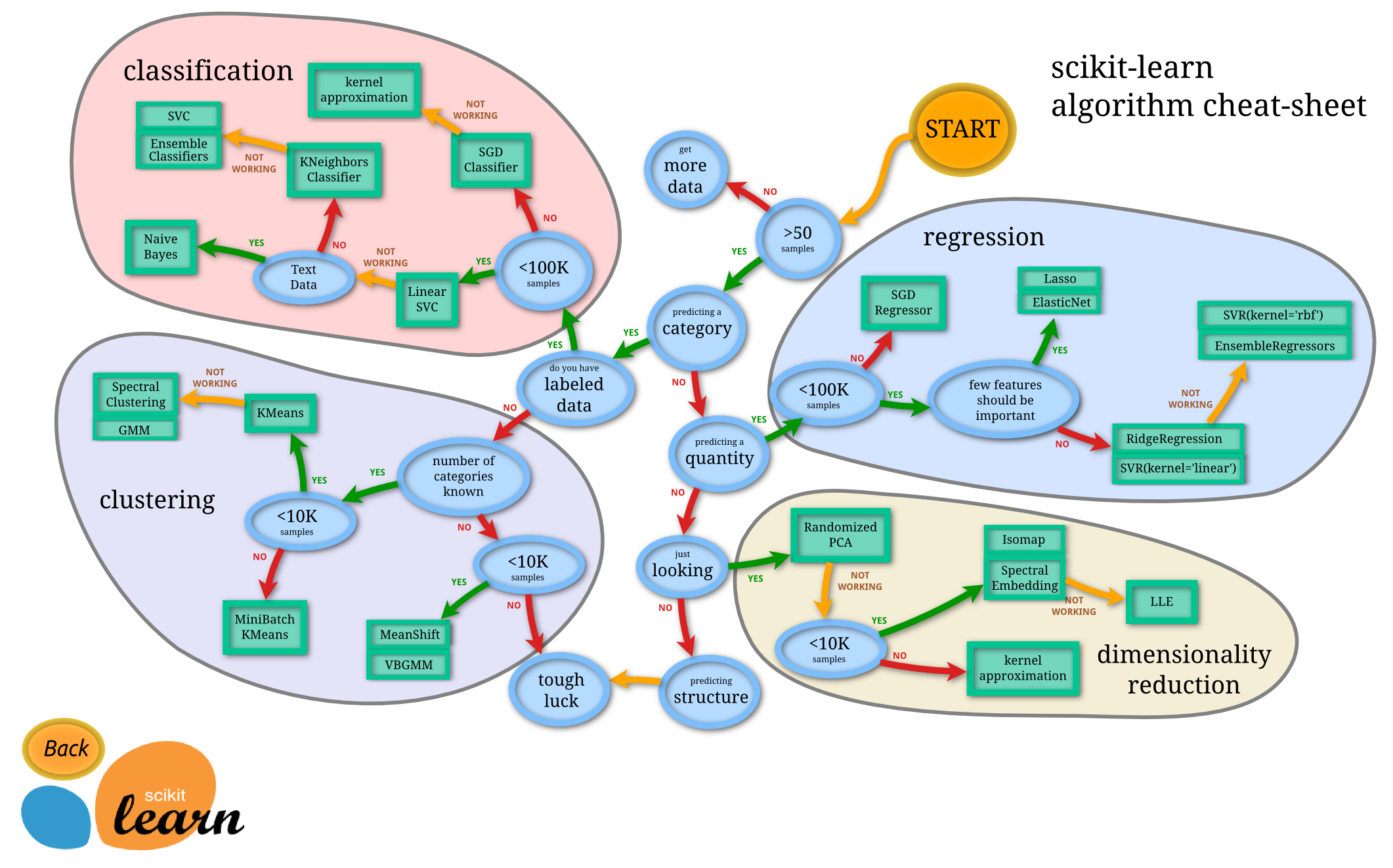
对于这个实验中的公路运量预测问题,我们可以用sklearn实现SVM支持向量积
(1) 进行标准化标签
# 进行标准化标签
def Encodeing(X):
label_encoder = []
X_encoded = np.empty(X.shape)
for i, item in enumerate(X[0]):
if item.isdigit():
X_encoded[:, i] = X[:, i]
else:
label_encoder.append(preprocessing.LabelEncoder())
X_encoded[:, i] = label_encoder[-1].fit_transform(X[:, i])
return X_encoded,label_encoder
(2) 预测
if __name__ == "__main__":
dataMat,labels_1,labels_2,label_encoder= read_xls_file('./data/train.csv')
dataMat_Norm = dataMat
print(dataMat)
print(labels_1)
print(labels_2)
params = {'kernel': 'rbf', 'C': 10.0, 'epsilon': 0.2}
regressor = SVR(**params)
regressor.fit(dataMat_Norm,labels_1)
input_data = ['22.44','0.75','0.11']
input_data_encoded = [-1] * len(input_data)
count = 0
for i, item in enumerate(input_data):
if item.isdigit():
input_data_encoded[i] = int(input_data[i])
else:
input_data_encoded[i] = int(label_encoder[count].transform([input_data[i]]))
count = count + 1
input_data_encoded = np.array(input_data_encoded)
print("Predicted traffic:", regressor.predict([input_data]))
(3) 结果分析
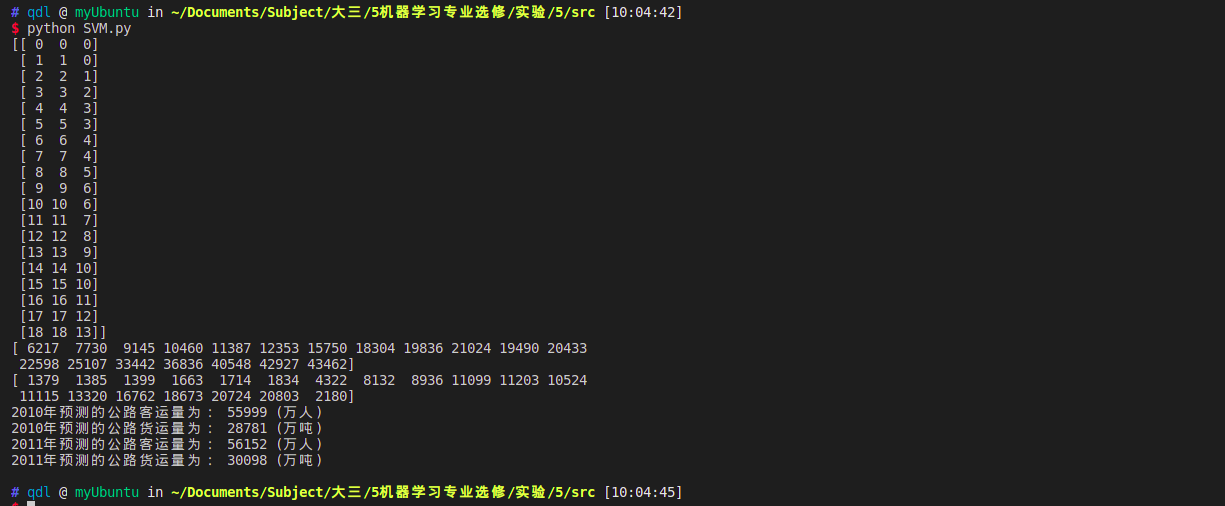
4. 实验结果对比分析
- 神经网络
- 梯度下降的线性回归
BP
优点:既能求解非线性问题,又能算法实现比较简单, 需要训求解线性问题。训练的参数比较少。
缺点:
(1)容易形成局部极小值而得不到全局最优值。BP神经网络中极小值比较多,所以很容易陷入局部极小值。
(2) 训练次数多使得学习效率低,收敛速度慢。
(3)隐含层的选取缺乏理论的指导。
(4)训练时学习新祥本有遗忘旧祥本的趋势
线性回归
优点:
算法实现比较简单, 需要训练的参数比较少。
缺点:
对于某些非线性问题,线性回归求解出的结果,误差比比较大
联系:
神经网络的每一个神经元都是一个线性回归模型,并且在此基础上,每个线性回归还添加了激活函数,因此能够学习到更多有用信息。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)