研读《基于AXI总线的SOC架构设计与分析》-AXI协议理解(四)
基于AXI总线的SoC架构,越来越成为高性能SoC系统架构的发展方向。这篇论文根据AXI总线的特点, 设计几种不同架构的AXI bus matrix ,包括有多通道、共享通道与混合通道的AXI bus matrix,然后总结了其特点及应用场合。搭建了AXI bus matrix验证平台,可自动**统计带宽、延时、访问时间**等总线性能指标。
基于AXI总线的SoC架构,越来越成为高性能SoC系统架构的发展方向。这篇论文根据AXI总线的特点, 设计几种不同架构的AXI bus matrix ,包括有多通道、共享通道与混合通道的AXI bus matrix,然后总结了其特点及应用场合。搭建了AXI bus matrix验证平台,可自动统计带宽、延时、访问时间等总线性能指标。
文章目录
论文下载地址: 基于AXI总线的SoC架构设计与分析.pdf
1.1 AXI 总线协议要点补充
细节可参考接口与协议学习笔记-AMBA片上通信协议_APB_AHB_AXI_AXI4不同版本(二),只记录一下小点。

AHB 协议需要一次突发传输的所有地址,地址与数据是锁定对应关系,后一次突发传输必须在前次传输完成才能进行。
AXI 只需要一次突发的首地址,可以连续发送多个突发传输首地址。
1.2 基于AXI总线的SOC系统设计流程小结
SoC 内部硬件划分的目的, 在于把各种功能的IP模块, 合理地分配到基于 AXI 总线的 SoC 系统中,使它们有机地结合起来,能够满足系统的各种场景应用。硬件划分的原则是:
- 总体把握带宽、延时需求, 对于高带宽/低延时(High bandwidth/low latency) 的IP模块分配在AXI matrix上,譬如: CPU,Memory controller、视频处理模块等等;对于带宽相对比较低,延时要求不高的IP模块,可分配在AHB总线 Matrix上,譬如USB DMA、SD DMA等等;对于一些低速的外设,可以分配在APB总线上;
- 根据总线接口,对于SoC内部的大部分IP来说,都是固定总线接口的可复用 IP,可以把他们合理地分配在对于的总线上;
- 根据时钟域,因为很多有特殊要求的IP模块,有固定的工作频率,为此可以把有相同工作频率的IP模块,挂在同一个总线矩阵上。
最大传输时间:单位时间内,设备在总线传输中进行的最长传输所需要的时间;
平均传输时间:单位时间内,设备进行的总线传输平均需要的时间。
影响传输时间的因素:
1.读/写多少数据;
2.传输过程中的握手环节;
3.被访问资源的响应速度;
4.从主设备到从设备,需要穿越的bus层数、bridge等。
1.3 AXI bus matrix设计总结
2-MASTER —- 2 SLAVE结构图

信息流由AXI主设备流向AXI从设备,每一个主设备端口有三个分配器,分别是AW、AR、W;每一个从设备端口有三个仲裁器,来仲裁三路信息,每次只允许一组信息通过并传递到AXI从设备。
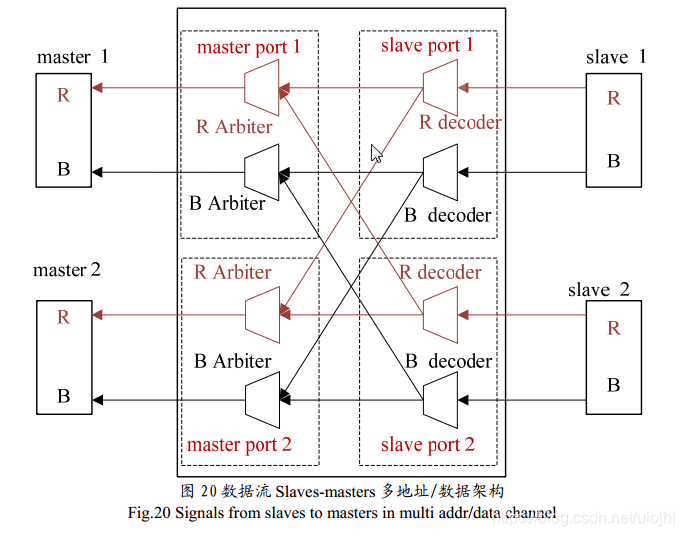
信息流由AXI从设备流向AXI主设备,每一个从设备端口都有两个分配器,来决定来自AXI从设备的读数据通道和写响应通道两个通道的信息,传输到那个AXI主设备端口;每一个主设备端口都有两个仲裁器,来仲裁信息传输给对应的主设备。
1.3.1 共享某些通道的AXI bus matrix架构设计实现

N to 1继而 1 to N为一个读地址、写地址通道共享的实例分析。 Master1/2通过一 个读/写地址的共享通道来把读/写的地址信息,传递给slave1/2。在此结构中,省去slave1/2 port端口的仲裁器等仲裁的逻辑,比多地址/多数据的AXI bus matrix更节省面积的原因。与此类似,其他三个通道的共享型架构原理相同。
混合型地址/数据通道的AXI bus matrix既有全通道的连接,又有共享性的连接。

1.3.2 Decoder的设计与实现
所有的从设备都是统一编址的,AW/AR可以根据每个从设备的地址段不同,来选择读或者写地址通道上的信息流向哪个从设备。
写数据通道分配器,它负责把写数据通道的信息传输到相应的从设备端口,写数据通道分配器的判断依据是进行ID对比。WID与事先发生到从设备端口的AWID进行对比,如果匹配,就将写数据通道的信息传输到该从设备端口。AXI4 不存在WID信号,就需要保证写入数据顺序与AWADDDR保持一致。
1.3.3 Arbiter的设计与实现
仲裁主要涉及优先级问题,参见常见的AXI总线仲裁器概述-AXI协议理解(一)。
1.4 优化AXI bus matrix的策略与方法
- 在信息流由源流向目的的的路径中,插入一级寄存器,以此来打断此长路径的组合电路。这种切割,将会增加Bus matrix的面积,同时也会增加一个时钟周期的延迟(Latency)。以面积换性能,提频
- 插入FIFO的方法,来提高整个Bus matrix的整体性能。
在AXI bus的5个通道插入异步/同步FIFO。能够显著提高总线数据的流水作业的性能,提高系统的吞吐量,增加了系统的灵活性,同时提高了系统的运行频率。倘若该FIFO为异步FIFO,能够实现数据跨时钟域的转换,实现了AXI bus matrix的异步设计。
- 采用ASIC的设计思路,可根据系统设计的需求,设置master2slave的连接性,这样可节省大量的逻辑。在SOC架构的设计过程中,MASTER与SLAVE的连接可以具体设计,不考虑通用性时可节省大量逻辑。
1.5 外围bridge的设计分析

AHB转AXI类似。
1.6 带宽的分析统计
对带宽的分析代码如下:
reg[31:0] m1_cnt_w;
reg[31:0] m1_cnt_r;
integer [31:0]m1_bw;
always @ (posedge aclk or negedge presetn )
begin
if ( !resetn )
counter_w <= 12'b0;
else if (m1_wvalid & m1_wready )
counter_w <= counter_w +1 ;
end
always @ (posedge aclk or negedge presetn )
begin
if ( !resetn )
counter_r <= 12'b0;
else if (m1_rvalid & m1_rready )
counter_r <= counter_r +1 ;
end
m1 = (counter_r + counter_w)*8/T_all /*T_all: simulation
duration,bus data width:32*/
带宽的统计,主要是在Testbench的Top里,加入相关的统计逻辑,引出相关的 valid & ready信号(包括读写)同时有效的个数,即可统计出在有效的仿真时间内 T_all,对于Master或Slave的带宽。
对 write latency 的统计代码分析如下:
reg[31:0] cmd_cnt_wlatency;
reg[31:0] m1_cnt_r;
reg cmd_valid;
integer [31:0]m1_wlatency;
always @ (posedge aclk or negedge presetn )
begin
if ( !resetn )
cmd_valid <= 1'b0;
else if (m1_awvalid)
cmd_valid <= 1'b1 ;
else if (m1_wready )
cmd_valid <= 1'b0 ;
end
always @ (posedge aclk or negedge presetn )
begin
if ( !resetn )
cmd_cnt_wlatency <= 12'b0;
else if (cmd_valid ) //统计cmd_valid持续时间
cmd_cnt_wlatency <= cmd_cnt_wlatency +1 ;
end
m1_wlatency = cmd_cnt_wlatency * T_aclk; /* T_aclk: aclk period */
写延时的统计代码分析。主要是在Testbench的顶层里,加入相关的统计逻辑,统计相关的Awvalid 和 Awready信号之间有效的Clock个数,再乘以时钟的周期,即是写延时。统计的是一段时间的数据,花费的无效时间。cnt计数是在不断累加过程。
对write操作访问时间的统计代码分析如下:
reg[31:0] access_cnt;
reg access_valid;
integer [31:0]m1_access;
always @ (posedge aclk or negedge presetn )
begin
if ( !resetn )
access_valid <= 1'b0;
else if (m1_awvalid & m1_wready)
access_valid <= 1'b1 ;
else if (m1_bvalid & m1_bready )
access_valid <= 1'b0 ;
end
always @ (posedge aclk or negedge presetn )
begin
if ( !resetn )
access_cnt <= 12'b0;
else if (access_valid) //统计有效时间,也就是有效访问时间
access_cnt <= access_cnt + 1 ;
end
m1_access = access_cnt * T_aclk; // T_aclk: aclk period
读写操作的访问时间的统计方法类似,只需要将读操作计时的计数器的清零信号,换成rlast&rvalid即可。主要是在Ttestbench的顶层里,加入相关的统计逻辑,统计相关的Awvalid和Awready与信号bvalid & bready之间有效的Clock个数,再乘以时钟的周期,即是写访问。统计有效时间,也就是有效访问时间
参考文档

开源、云原生的融合云平台
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)