
compare基于规则的快速比较_如何基于kafka来实现一个全功能的关系型数据库
kafka作为一个重要内容,今天我们就来讲一讲。在本文中,我将介绍如何通过扩展 KCache来实现一个全功能的关系型数据库,我把这个数据库叫作 KarelDB。另外,我也将分享如何通过组装开源组件来实现新的数据库架构,就像 Dropwizard那样。在深入介绍组成 KarelDB 的组件之前,先让我们来了解一下如何快速让它运行起来。首先要把它下载下来,解压缩,修改 config/kareldb.p


kafka作为一个重要内容,今天我们就来讲一讲。
在本文中,我将介绍如何通过扩展 KCache来实现一个全功能的关系型数据库,我把这个数据库叫作 KarelDB。另外,我也将分享如何通过组装开源组件来实现新的数据库架构,就像 Dropwizard那样。
在深入介绍组成 KarelDB 的组件之前,先让我们来了解一下如何快速让它运行起来。首先要把它下载下来,解压缩,修改 config/kareldb.properties,把它指向 Kafka 服务器,然后运行下面的命令:

在 KarelDB 运行的同时,可以在另一个终端输入以下命令来启动 sqlline,然后用它来访问 JDBC 数据库。
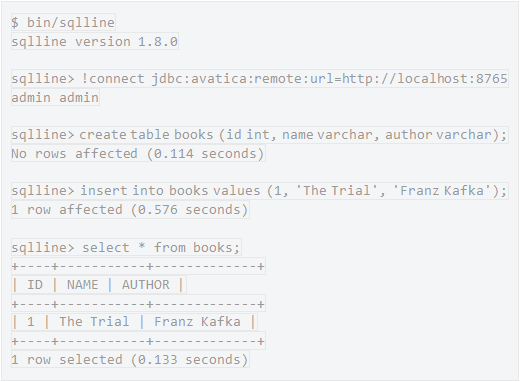

SQL:Calcite
Apache Calcite 是一个 SQL 框架,可以用来解析、优化和执行查询语句,但不包含数据存储。Calcite 使用内置的枚举调用方式来处理查询,把底层的数据存储表示成一系列元组,这样就可以使用迭代接口来访问它们。元组可以使用内置键值存储来表示,所以 KarelDB 支持键的查询和键区间过滤(利用 Avro 的排序功能),只是把查询交给了 Calcite。
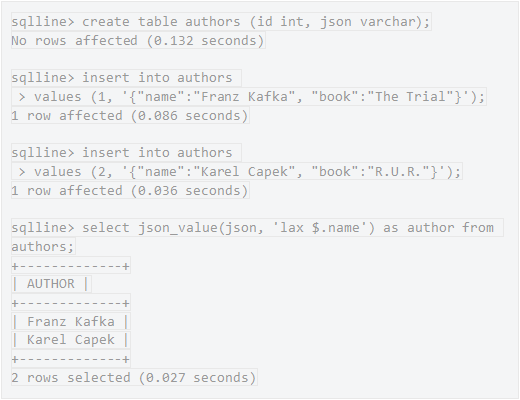
事务和 MVCC:OMID
Apache Omid 最初是为 HBase 设计的,但它其实是一个可以为键值存储提供事务支持的通用框架。另外,Omid 使用了底层的键值存储来持久化与事务有关的元数据。所以,将 Omid 与已有的键值存储(比如 KCache)集成在一起是很容易的。
实际上,Omid 需要用到键值存储的一些功能,比如多版本数据和原子 CAS(Compare-And-Set)能力。KarelDB 在 KCache 之上组合了这些能力,所以可以利用 Omid 来支持事务管理。Omid 使用键值存储的这些能力来实现 MVCC 快照隔离。在其他数据库(比如 Oracle 和 PostgreSQL)中,MVCC 经常被用来实现快照隔离。
在下面的例子中,我们可以看到如何通过回滚事务让数据库回到事务开始之前的状态。

当然,事务可以跨多行和多张表。
持久化:Kafka
KarelDB 的核心组件是 KCache。KCache 是一个基于 Kafka 的嵌入式键值存储引擎。有很多组件将 Kafka 作为简单的键值存储,比如 Kafka Connect 和 Confluent Schema Registry。但 KCache 更进一步,它提供了一套基于 Map 的 API,方便用户使用。另外,KCache 还支持不同的嵌入式键值存储实现,只要它们是基于 Kafka 的。
KarelDB 的默认 KCache 配置是 RocksDB,所以它支持海量数据集,启动速度也很快。当然,KCache 也可以被配置成使用内存缓存,而不是 RocksDB。
序列化和 schema 演化:Avro
Kafka 将 Apache Avro 作为事实上的数据格式标准。Avro 不仅提供了紧凑的二级制格式,对 schema 演化也提供了很好的支持。这也就是为什么 Confluent Schema Registry 会将 Avro 作为 schema 格式的首选。
KarelDB 用 Avro 来定义表间关系,也用它来序列化关系数据,所以我们可以通过 ALTER TABLE 命令来修改 KarelDB 的 schema。
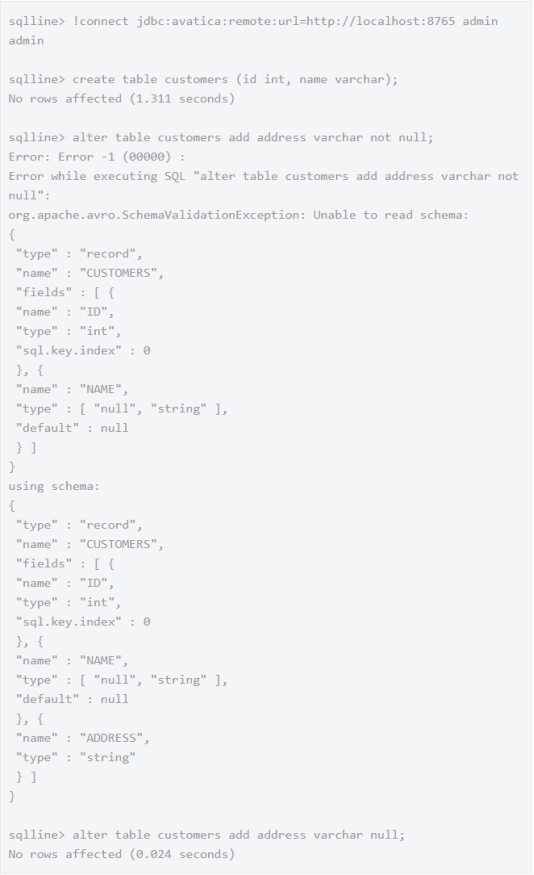
从上面的例子可以看到,在我们第一次尝试添加一个 NOT NULL 的列时,Avro 拒绝了 schema 的变更,因为 NOT NULL 会导致不包含该字段的旧记录反序列化失败。但当我们使用 NULL 时,ALTER TABLE 命令执行成功了。
在用 Avro 进行反序列化时,添加到 schema 中的字段(没有使用 NOT NULL)会被赋予默认值,或者如果这个字段是可选项的,它的值就是 null。Avro 框架会自动处理这些。
另外,Avro 定义了标准的数据排序顺序和比较函数,可以直接操作二进制数据,而不需要进行反序列化。这样 KarelDB 就可以高效地进行区间查找。
JDBC:Avatica
KarelDB 支持两种运行模式,可以是嵌入式的,也可以作为服务器。在作为服务器运行时,KarelDB 借助 Apache Avatica 来提供 RPC 支持。Avatica 不仅提供了一个服务器框架,还提供了一个 JDBC 驱动,可以通过 Avatica RPC 与服务器通信。
使用 Kafka 的一个好处是多台服务器可以消费相同的主题,所以,可以将多台 KarelDB 组成集群,避免单点故障。其中一台服务器被选为首领,其他的是追随者(或者叫副本)。当一个追随者服务器收到 JDBC 请求时,它会通过 Avatica JDBC 驱动程序将请求转发给首领。如果首领发生故障,一个追随者会被选举为新的首领。
用组件组装数据库
现如今的开源库已经做到了多年前基于组件的软件开发所希望做到的事情。现在可以基于开源库组装出复杂的系统,比如,通过集成一些设计良好的组件,就可以组装出一个关系型数据库,这些组件在系统中扮演了各自擅长的角色。
在上面的例子中,我分享了如何使用已有开源组件来组装 KarelDB:
1.Apache Kafka:用于持久化,使用 KCache 作为嵌入式的键值存储;
2.Apache Avro:用于序列化和 schema 演化;
3.Apache Calcite:用于解析、优化和执行 SQL;
4.Apache Omid:提供事务管理和 MVCC 支持;
5.Apache Avatica:用于支持 JDBC。
目前的 KarelDB 是单节点数据库,它可以拥有副本,但不是一个分布式数据库。另外,KarelDB 是一个普通的关系型数据库,不支持流式处理。如果需要分布式流式关系型数据库,可以考虑 KSQL
虽然 KarelDB 还很年轻,但如果你想要一个基于 Kafka 的普通关系型数据库,可以尝试一下它。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)