
CSPDarkNet53学习
文章目录CSP结构Applying CSPNet to ResNe(X)tApplying CSPNet to DenseNetDarkNet53介绍CSPDarknet53架构参考CSP结构Applying CSPNet to ResNe(X)t原文如此介绍:设计出Partial transition layers的目的是最大化梯度联合的差异。其使用梯度流截断的手段避免不同的层学习到重复的梯度信
CSP结构
Applying CSPNet to ResNe(X)t

原文如此介绍:设计出Partial transition layers的目的是最大化梯度联合的差异。其使用梯度流截断的手段避免不同的层学习到重复的梯度信息。得出的结论是,如果能够有效的减少重复的梯度学习,那么网络的学习能力能够大大提升.
Applying CSPNet to DenseNet

DarkNet53介绍
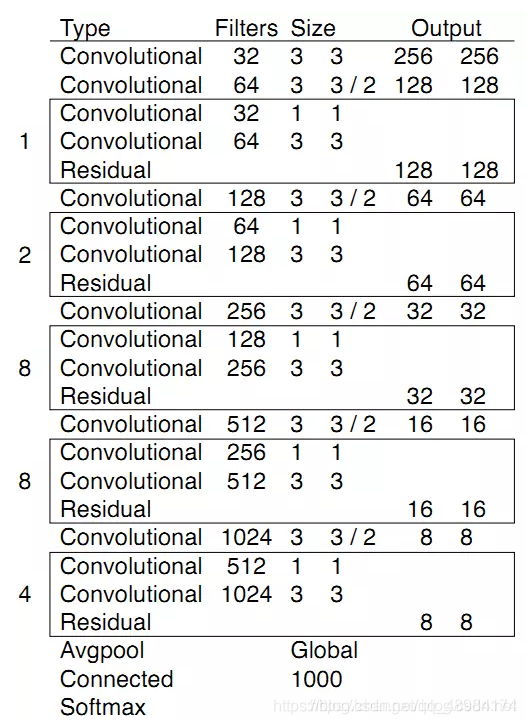
由上我们可以对比ResNet50得出其使用了kernel_size=3,stride=1的卷积代替了kernel_size=7,stride=1的卷积,减少了计算量。使用了kernel_size=3,stride=1的卷积代替了maxpool,因此作者认为Max-Pooling降采样会使得输出变得“高频高幅”,因此在后面会导致网格效应。此外DarkNet含有5个Residual相比于Resnet的4个stage,其中Residual Block中分支路使用的为kernel_size=1,kernel_size=3,stride=1的Conv,注意此处并没有进行降采样,而是在concat操作后stride=2的卷积进行下采样。
CSPDarknet53架构

采用博主@Bubbliiiing的YOLOV4实现讲解
import torch
import torch.nn.functional as F
import torch.nn as nn
import math
from collections import OrderedDict
#-------------------------------------------------#
# MISH激活函数
#-------------------------------------------------#
class Mish(nn.Module):
def __init__(self):
super(Mish, self).__init__()
def forward(self, x):
return x * torch.tanh(F.softplus(x))
#-------------------------------------------------#
# 卷积块
# CONV+BATCHNORM+MISH
#-------------------------------------------------#
class BasicConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1):
super(BasicConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, kernel_size//2, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.activation = Mish()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activation(x)
return x
#---------------------------------------------------#
# CSPdarknet的结构块的组成部分
# 内部堆叠的残差块
#---------------------------------------------------#
class Resblock(nn.Module):
def __init__(self, channels, hidden_channels=None, residual_activation=nn.Identity()):
super(Resblock, self).__init__()
if hidden_channels is None:
hidden_channels = channels
self.block = nn.Sequential(
BasicConv(channels, hidden_channels, 1),
BasicConv(hidden_channels, channels, 3)
)
def forward(self, x):
return x+self.block(x)
#---------------------------------------------------#
# CSPdarknet的结构块
# 存在一个大残差边
# 这个大残差边绕过了很多的残差结构
#---------------------------------------------------#
class Resblock_body(nn.Module):
def __init__(self, in_channels, out_channels, num_blocks, first):
super(Resblock_body, self).__init__()
self.downsample_conv = BasicConv(in_channels, out_channels, 3, stride=2)
if first:
self.split_conv0 = BasicConv(out_channels, out_channels, 1)
self.split_conv1 = BasicConv(out_channels, out_channels, 1)
self.blocks_conv = nn.Sequential(
Resblock(channels=out_channels, hidden_channels=out_channels//2),
BasicConv(out_channels, out_channels, 1)
)
self.concat_conv = BasicConv(out_channels*2, out_channels, 1)
else:
self.split_conv0 = BasicConv(out_channels, out_channels//2, 1)
self.split_conv1 = BasicConv(out_channels, out_channels//2, 1)
self.blocks_conv = nn.Sequential(
*[Resblock(out_channels//2) for _ in range(num_blocks)],
BasicConv(out_channels//2, out_channels//2, 1)
)
self.concat_conv = BasicConv(out_channels, out_channels, 1)
def forward(self, x):
x = self.downsample_conv(x)
x0 = self.split_conv0(x)
x1 = self.split_conv1(x)
x1 = self.blocks_conv(x1)
x = torch.cat([x1, x0], dim=1)
x = self.concat_conv(x)
return x
class CSPDarkNet(nn.Module):
def __init__(self, layers):
super(CSPDarkNet, self).__init__()
self.inplanes = 32
self.conv1 = BasicConv(3, self.inplanes, kernel_size=3, stride=1)
self.feature_channels = [64, 128, 256, 512, 1024]
self.stages = nn.ModuleList([
Resblock_body(self.inplanes, self.feature_channels[0], layers[0], first=True),
Resblock_body(self.feature_channels[0], self.feature_channels[1], layers[1], first=False),
Resblock_body(self.feature_channels[1], self.feature_channels[2], layers[2], first=False),
Resblock_body(self.feature_channels[2], self.feature_channels[3], layers[3], first=False),
Resblock_body(self.feature_channels[3], self.feature_channels[4], layers[4], first=False)
])
self.num_features = 1
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
x = self.conv1(x)
x = self.stages[0](x)
x = self.stages[1](x)
out3 = self.stages[2](x)
out4 = self.stages[3](out3)
out5 = self.stages[4](out4)
return out3, out4, out5
def darknet53(pretrained, **kwargs):
model = CSPDarkNet([1, 2, 8, 8, 4])
if pretrained:
if isinstance(pretrained, str):
model.load_state_dict(torch.load(pretrained))
else:
raise Exception("darknet request a pretrained path. got [{}]".format(pretrained))
return model
好,讲完了。嘻嘻
首先3x3,stride=1的卷积通道压缩,进入Resblock1。
ResBlock1先降采样(减小后续计算量),走paritial transition路线,分支为两个1x1,stride=1的卷积。其中一个分支走residual block路线。
结束后进行x0,x1拼接,拼接后在进行一次卷积
由于先进行降采样,因此计算量,计算速度大大减小。
参考

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)