
混淆矩阵怎么看_分类模型评判指标--混淆矩阵
简介混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。一句话解释就是 :混淆矩阵就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。这个表就是混淆矩阵。定义以分类模型中最简单的二分类为例,对于这种问题,我们的模型最终需要判断样本的结果是0还是1,或者说是positive还是negative。我们通过样本的采集,能够直接知道
简介
混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。
一句话解释就是 :混淆矩阵就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。这个表就是混淆矩阵。
定义
以分类模型中最简单的二分类为例,对于这种问题,我们的模型最终需要判断样本的结果是0还是1,或者说是positive还是negative。
我们通过样本的采集,能够直接知道真实情况下,哪些数据结果是positive,哪些结果是negative。同时,我们通过用样本数据跑出分类器模型的结果,也可以知道模型认为这些数据哪些是positive,哪些是negative。
因此,我们就能得到这样四个基础指标,我称他们是一级指标(最底层的):
- 真实值是positive,模型认为是positive的数量(True Positive=TP)
- 真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第一类错误(Type I Error)
- 真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第二类错误(Type II Error)
- 真实值是negative,模型认为是negative的数量(True Negative=TN)
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):
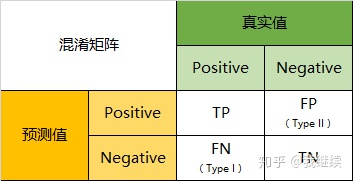
混淆矩阵的指标
预测性分类模型,肯定是希望越准越好。那么,对应到混淆矩阵中,那肯定是希望TP与TN的数量大,而FP与FN的数量小。所以当我们得到了模型的混淆矩阵后,就需要去看有多少观测值在第二、四象限对应的位置,这里的数值越多越好;反之,在第一、三象限对应位置出现的观测值肯定是越少越好。
二级指标
但是,混淆矩阵里面统计的是个数,有时候面对大量的数据,光凭算个数,很难衡量模型的优劣。因此混淆矩阵在基本的统计结果上又延伸了如下4个指标,我称他们是二级指标(通过最底层指标加减乘除得到的):
- 准确率(Accuracy)—— 针对整个模型
- 精确率(Precision)
- 灵敏度(Sensitivity):就是召回率(Recall)
- 特异度(Specificity)

三级指标
通过上面的四个二级指标,可以将混淆矩阵中数量的结果转化为0-1之间的比率。便于进行标准化的衡量。
在这四个指标的基础上在进行拓展,会产生另外一个三级指标,这个指标叫做F1 Score。他的计算公式是:
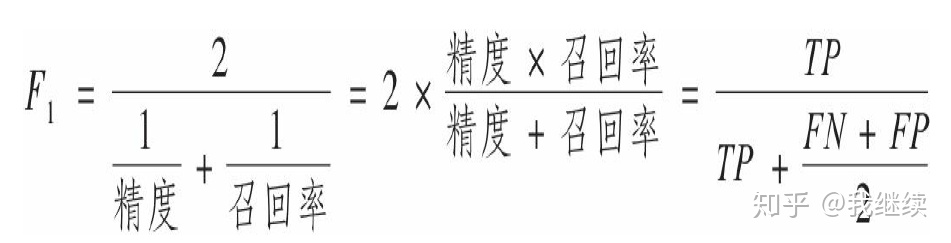
F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
多分类的情况
当分类问题是二分问题是,混淆矩阵可以用上面的方法计算。当分类的结果多于两种的时候,混淆矩阵同时适用。
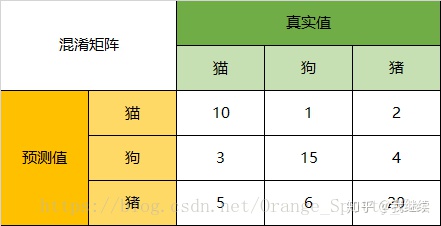
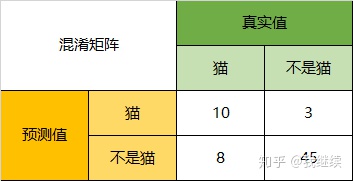
Accuracy
在总共66个动物中,我们一共预测对了10 + 15 + 20=45个样本,所以准确率(Accuracy)=45/66 = 68.2%。
Precision
所以,以猫为例,模型的结果告诉我们,66只动物里有13只是猫,但是其实这13只猫只有10只预测对了。模型认为是猫的13只动物里,有1条狗,两只猪。所以,Precision(猫)= 10/13 = 76.9%
Recall
以猫为例,在总共18只真猫中,我们的模型认为里面只有10只是猫,剩下的3只是狗,5只都是猪。所以,Recall(猫)= 10/18 = 55.6%
Specificity
以猫为例,在总共48只不是猫的动物中,模型认为有45只不是猫。所以,Specificity(猫)= 45/48 = 93.8%。虽然在45只动物里,模型依然认为错判了6只狗与4只猫,但是从猫的角度而言,模型的判断是没有错的。
F1-Score
通过公式,可以计算出,对猫而言,F1-Score=(2 * 0.769 * 0.556)/( 0.769 + 0.556) = 64.54%
同样,我们也可以分别计算猪与狗各自的二级指标与三级指标值。
F1分数对那些具有相近的精度和召回率的分类器更为有利。这不一定能一直符合你的期望:在某些情况下,你更关心的是精度,而另一些情况下,你可能真正关心的是召回率
遗憾的是,鱼和熊掌不可兼得:你不能同时增加精度并减少召回率,反之亦然。这称为精度/召回率权衡。
sklearn实现
- 根据预测标签和真实标签计算混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(真实标签向量,预测标签向量)
注意:如果是二分类,计算出的矩阵,左上角是TN(真负类),右下角是TR(真正类)
- 根据预测标签和真实标签计算精确率和召回率
from sklearn.metrics import precision_score, recall_score
precision_score(真实标签向量,预测标签向量)
recall_score(真实标签向量,预测标签向量)
- 根据预测标签和真实标签计算F1分数
from sklearn.metrics import f1_score
f1_score(真实标签向量,预测标签向量)
精度和召回率随阈值变化的曲线
调节阈值可以得到不同的精度和召回率,通过调用决策函数计算出每个实例的分数,然后根据这些分数确定决定阈值
1、cross_val_predict()函数获取训练集中所有实例的分数
from sklearn.model_selection import cross_val_predict
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision_function"),第一个参数是代表我们使用的算法
2、有了这些分数,可以使用precision_recall_curve()函数来计算 所有可能的阈值的精度和召回率。
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
提高阈值确实可以降低召回率,提高精度
3、使用Matplotlib绘制精度和召回率相对于阈值的函数图
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], "b--", label="Precision")
plt.plot(thresholds, recalls[:-1], "g-", label="Recall")
plt.xlabel("Threshold")
plt.legend(loc="upper left")
plt.ylim([0, 1])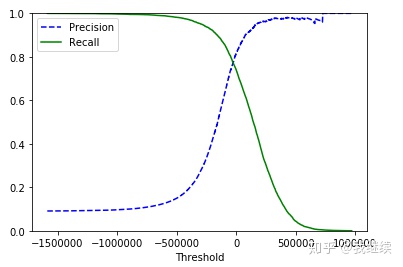
当你提高阈值时,精度有时也有可能会下降(尽管总体趋势是上升的),但是召回率只会下降,所以图中的精度曲线有点崎岖,召回率曲线看起来更平滑
精度/召回率的函数图
def plot_precision_recall(precisions, recalls):
plt.plot(recalls[:-1],precisions[:-1],"g-")
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.ylim([0,1])
plt.xlim([0,1])
plot_precision_recall(precisions, recalls)
plt.show()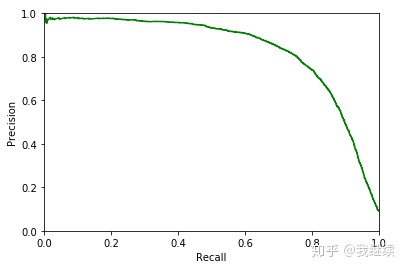
ROC曲线(受试者工作特征曲线)
首先要清楚两个指标定义:TPR = TP / (TP+FN)
1、首先需要使用roc_curve()函数计算多种阈值的TPR和FPR
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)2、使用Matplotlib绘制FPR对TPR的曲线
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1], [0, 1], 'k--')
plt.axis([0, 1, 0, 1])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plot_roc_curve(fpr, tpr)
plt.show()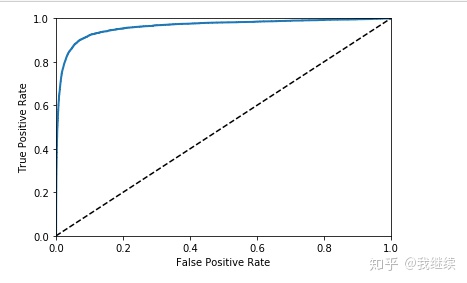
同样这里再次面临一个折中权衡:召回率(TPR)越高,分类器产生的假正类率(FPR)就越多。虚线表示纯随机分类器的ROC曲线;一个优秀的分类器应该离这条线越远越好(向左上角)
AUC
有一种比较分类器的方法是测量ROC曲线下面积(AUC)。完美的分类器的ROC,AUC等于1,而纯随机分类器的ROC,AUC等于0.5。Scikit-Learn提供计算ROC曲线的AUC的函数
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_5, y_scores)由于ROC曲线与精度/召回率(或PR)曲线非常相似,因此你可能会问如何决定使用哪种曲线。有一个经验法则是,当正类非常少见或者你更关注假正类而不是假负类时,你应该选择PR曲线,反之则是ROC曲线。
补充
如果训练的是一个随机森林的分类器,是没有决策函数的,需要用到predict_proba()方法得出一个数组,其中每行代表一个实例,每列代表一个类别,数组的每一个元素代表某个给定实例属于某个给定类别的概率。
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,
method="predict_proba")
y_scores_forest = y_probas_forest[:, 1]
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest)直接使用实例属于正类的概率值作为分数值

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 35
35 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)