
编程实现按日期统计访问次数_基于图的代码统计语言模型
摘要N-Gram统计语言模型在捕捉编程模式(programming pattern)、支持代码补全上面取得了很大成功。然而,使用该方法在捕捉高层次编程模式上面临很多挑战,因为源代码序列在N-gram不匹配不代表在语义或语法上的匹配。本文提出Gralan,一种基于图的统计语言模型并将它应用在代码推荐(code suggestion)上。Gralan能够从源代码数据集中学习并根据数据集中观察到的图计算

摘要
N-Gram统计语言模型在捕捉编程模式(programming pattern)、支持代码补全上面取得了很大成功。然而,使用该方法在捕捉高层次编程模式上面临很多挑战,因为源代码序列在N-gram不匹配不代表在语义或语法上的匹配。本文提出Gralan,一种基于图的统计语言模型并将它应用在代码推荐(code suggestion)上。Gralan能够从源代码数据集中学习并根据数据集中观察到的图计算任何当前的图的概率。我们使用GraLan来建立一个API推荐引擎以及基于AST的语言模型,我们叫他ASTLan。ASTLan支持关于下一个合法模板的推荐和当前相同语法模板的检测。在开源数据集上的测试效果显示我们的引擎在API推荐上超过了代表行业先进水平的方法,在一些情况下,我们的准确率达到75%。它能够在仅给出5个候选API的情况下准确推荐API。ASTLan在下一个语法模板推荐上也能够有很高的准确率,同时它也能够检测很多有用且常见的语法模板。
1.INTRODUCTION(引言)
源码具有重复性。编程模式检测在软件工程的许多应用中都有巨大的用处,包括IDE支持(代码补全、代码推荐)、代码搜索、文档化、框架自适应、代码修复、语言迁移等等。由于它们的重要性,许多关于代码模式检测的方法被提了出来。他们大致分为两种。一种是基于确定模式挖掘算法,比方说挖掘频繁项集、频繁序列、频繁图、关联规则等。当这些东西出现超过一个指定次数后就被视为模式。
另一种是基于统计的语言模型。统计语言模型L是一个生成模型,它由三个部分组成:作为基本单元的词典V、生成过程G、似然函数P(.|L)。P(s|L)指的是在L这个模型条件下,生成序列s的概率,s由V中的词组成。软件工程最近的研究表明,N-gram语言模型在捕捉细粒度上的代码模式从而进行代码推荐上非常有用(代码推荐指的是给定一部分代码,推荐完整代码)。
N-gram模型是一个基于两个假设的统计语言模型。首先,它假设序列从左到右生成。其次生成一个词的概率只取决于它的局部上下文如,前n个词。N-gram在自然语言处理的文本分析领域非常流行。但是,根据编程语言的要求,源代码有着定义好了的语法和语义。这些语法以及不同层次的语义能够由树形结构(比如抽象语法树AST)或者基于图的结构(比如控制流图、程序依赖图)表示。这些不同层级的编程模式在之前列出的软工应用中都很有用。然而,使用N-gram容易造成结构化数据表示的失配问题,因此某种程度上说,它不是很适合检测编程模式。举例而言,使用N-gram模型捕捉API使用模式就面临很多问题。
首先,在使用模式(usage pattern)上,两个API方法在调用上要求有先后顺序,譬如Scanner和FileWriter这两个对象的实例在关于“用Scanner和FileWriter从文件中读数据然后写到另一个文件”的模式上就存在调用先后顺序。但是,为了建模这个模式,n-gram要求关于API调用的整个序列。否则,它就会认为两个实例的顺序不存在关系。其次,代码的模式通常和具体任务有关,比如在处理从文件中读数据时通常便随着关于文件中数据的处理操作。N-gram不能够准确的捕捉和项目相关的模式使用。所以,模型可能会丢失掉准确的模式并推荐错误的API调用。
第三,在许多情况下,先前的n个API调用不足以提供足够多的上下文支持来进行代码推荐,因为同一个模式可能距离很远从而在n个元素之外。把n扩展成很大的值也不能解决这个问题因为许多无关的API就会被包含进来。同样地,使用n-gram捕获语法模板也不是很好因为AST节点的结构化和内容并没有被考虑到。
在这篇成果中,我们引入GraLan,一个基于图的统计语言模型。它能够从源码训练集中总结出一堆图,从而计算图B在一系列上下文图C的情况下出现的概率。C包含B的部分子图。我们进一步考虑当B只比A多一个节点和一条边的情况。A成为B的父图。在训练中,我们在数据集上定义图的父子关系并用贝叶斯方法计算这些概率,计算图和子图共现次数以及出现次数。
为了验证GraLan的可用性,我们把它用在一个代码推荐引擎上来推荐“下一个”(next)API。API元素(API element)是API方法的调用和访问,与API使用中的控制单元(如if,while,for)相关。“下一个”API元素用来填充当前的编辑位置L(不一定要是当前代码的末尾)。首先,当前代码被解析并建立成Groum。Groum是一种图API表示方法。为了推荐代码,我们把API usages看做上下文环境,使用GraLan来推荐候选API列表,这些API候选根据概率排序。
我们同时还开发了一个ASTLan,一个基于AST的语言模型。它是从GraLan中发展出来的用来支持下一个合法模板推荐及当前常用模板检测的。IDE通过这些工具能够给开发人员在编辑过程中提供许多常见的语法模板。
我们用实验来苹果GraLan和ASTLan的代码推荐能力。考虑一个推荐的条件下,GraLan有1/3的样例是能够正确推荐API元素的。在1/2的样例中,正确的API元素可以在两个推荐中找到。在3/4的样例中,正确的API元素可以在被推荐的前5项中找到。
我们同事比较了GraLan和两种行业先进方法(Bruch等、Raychev等)的准确率。Bruch他们的方法是基于数据集上的一个API元素集合。Raychev他们的方法是基于N-gram。我们的结果显示GraLan的top5准确率比基于集合的方法和基于N-gram的方法分别高出7.1-10.2%和20.4-35.2%。ASTLan同样也能够实现很高的准确率。在63%的样例中,正确的下一个模板存在于ASTLan的top5候选列表中。更重要的是,ASTLan能够挖掘许多正确的语法模板。我们的主要贡献如下:
1、GraLan和ASTLan,基于图和基于树的面向对象源码统计语言模型。
2、他们在API和语法模板推荐引擎上的应用以及语法模板检测。
3、对它们的表现进行了一系列的评估。
2.A MOTIVATING EXAMPLE(一个激动人心的例子)
让我们从一个例子开始来说明使用N-gram模型进行代码推荐会遇到的挑战以及GraLan的动机。图一的代码中,bookdata通过使用File和Scanner类从一个文本文件中读取数据,随后使用File和Filewriter类把数据存放在另一个文件。当元数据被读取后(第7-8行),一个while循环(10-15行)用来遍历第一个文件的所有行来抽取作者数据并写入到第二个文件。

图1 一个API使用样例
从这个例子中,我们可以发现,要实现一个编程任务,开发者要用到API元素。这些元素是一些由框架或者包提供的类、方法或域(field)。这些API元素在不同的数据或控制流依赖或控制结构下根据API的规约按指定顺序调用。使用一系列API元素实现一个编程任务称作一个API使用(API usage)。关于usage的一个例子就是从一个文件中读数据,这个操作涉及到File.new、Scanner.new、Scanner.hasNextLine、Scanner.nextLine、Scanner.close、while等多个操作。
使用N-gram捕捉常见使用(又称模式)并给出代码推荐面临以下多个挑战:
1、总顺序问题。一个使用中的API元素并没有特定的顺序要求。比方说,Scanner和FileWriter对象的实例化。然而,N-gram要求API有特定的顺序。因此,它不会认为FileWriter.new-Scanner.new和Scanner.new-FileWriter.new是同一个模式。使用图模型能够帮助解决这个问题。
2、代码模式和具体项目代码的关联问题。模式“从一个文件读数据再写入另一个文件”的代码和具体项目逻辑密切相关。比如,读元数据(7-8行),检查信息合法性(12行)以及提取作者信息(13行)。N-gram模型可能不能准确包含这些和项目相关的使用,从而导致错误的推荐。
3、同一个模式中的API元素可能相距甚远。举个例子,从文件中读数据设计到File.new和Scanner.new(1-2行),while循环和Scanner.hasNextLine(10行)以及Scanner.nextLine(11行)和Scanner.close(18行)。这样的模式很难由N-gram模型捕捉,因为它具有长度限制。然而,使用图模型能够考虑到API元素的这些依赖。
4、不按序列顺序编码。举例来说,开发人员在写while循环(10行)之前可能会写它的条件。N-gram可能会用第10行之前的代码来进行推荐。然而,在这之后的代码比如bookSc.nextLine可能暗示着bookSc.hasNextLine的使用,因为他们经常一起出现。这些告诉我们,在进行代码推荐的时候,应该把上下文延伸到推荐位置往后的部分。
3.GRAPH-BASED STATISTICAL LANGUAGE MODEL(基于图的统计语言模型)
为了解决上述问题,我们提出了GraLan,一个基于图的统计语言模型。我们将在API源码推荐这样一个背景下展示我们的方法。但是,GraLan并不只是可以用于API图表示,他可以用于更广泛的从源码抽取图的应用中。接下来我们陈述API推荐的一些特定概念。
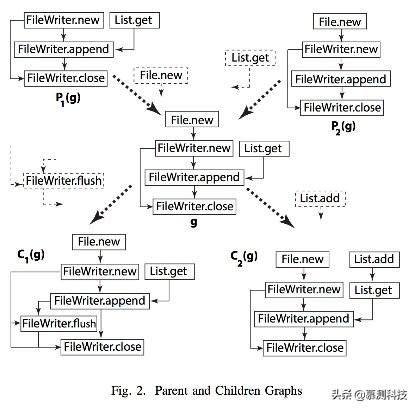
图2 父图和子图
A. API使用表示(API Usage Representation)
定义1(API Usage):一个API Usage是一个在客户端代码中相关API元素的集合(比方说类、方法调用、接口访问和操作),同时还包括特定顺序的控制单元(条件、循环)以及API元素间的数据流依赖。
在我们之前的成果中,我们开发了一个基于图的表示模型,叫做Groum,用来表示API usage。
定义2(Groum):一个Groum是一个图,这个图中,节点表示动作(如方法调用、重载、接口访问)和控制点(如控制单元的分支点if、while等)。边表示控制流和数据流在节点间的依赖。节点的标签由类名、方法名或控制单元名表示。
我们之前的成果表面一个API使用能够用Groum图的形式表示。在图2 ,P2(g)将FileWriter表示为Groum形式。动作节点如File.new、FileWriter.new等表示API调用、接口访问或者操作。节点标签由名称、动作节点API的参数类型修饰。一条边连接两个有数据依赖或控制依赖的两个动作节点。比如,FileWriter.new会在FileWriter.append之前调用并且创建的对象会在之后被用到。因此者之间存在一条边。如果一个使用设计while循环(比如图1)。一个叫做WHILE的控制节点会在条件节点之后创建并与之相连。如果一个方法调用是另一个方法调用的参数,比如m(n()),内部调用的节点会在外部调用之前创建并且他们也会有边相连。
B.生成过程(Generation Process)
一个图能够由它的一个子图通过增加节点和边来构造。因此图的生成过程可以被建模成不断添加节点和边到已有子图的过程。因此,我们定义如下概念:
定义3(Parent and Children Graphs):如果添加一个新的节点N和一条边到P(g)能够生成图g,则连接图P(g)是图g的父图,g是P(g)的一个子图。一个图能有很多父图和子图。
这个关系对于所有图都适用。但我们在这主要用在API适用图上面(Groums)。如图2所示,P1(g)是g的一个父图因为把节点File.new和边File.new-FileWriter.new添加到P1(g)中就能够构造出g。g也有子图C1(g)和C2(g)。通过考虑已经观察到的Groum g来推荐API相当于把g的所有子图都考虑了。我们把父关系扩展到祖先,把子关系扩展到后代这一概念。
定义4(Context):从图g中生成新图C(g)这一过程的上下文由一个包含g的图集组成,这些图集用来生成C(g)。
我们用Pr(C(g)|Ctxt) = Pr((g,N+,E+)|Ctxt)表示生成概率。N+是添加的节点,E+是一系列添加的边。所有Ctxt中的图包括g对C(g)的生成存在影响。对于API推荐应用,上下文包括子图g1…gn。这些子图非常有利于预测。对于每个从子图gi生成的孩子图,相关添加节点Nj将被收集起来并排序。所有新节点将被添加到G中生成候选图G’最为推荐内容。
C.基于贝叶斯统计推理的计算(Computation based on Bayesian Statistical Inference)
让我们解释下如何使用贝叶斯统计推理计算图的生成概率,我们有:
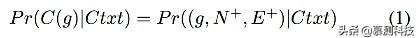
我们希望计算添加一个节点和边到g的生成率。这个概率通过统计学习的方法从训练集中学习。为了实现这些,我们从这开始:
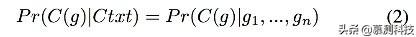
上式中,Pr(…)表示子图C(g)由父图g生成的概率。
贝叶斯模型基于贝叶斯理论给定先验概率,估计后验概率:
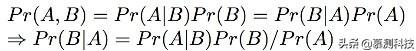
上式中,Pr(B|A)是隐变量B在观察到的变量A下的概率。Pr(A|B)是从相关关系中学到的概率。Pr(A)和Pr(B)是A和B分别的先验概率。在GraLan中,隐变量B表示图C(g)出现,A表示给定图g以及上下文Ctxt。因此公式(2)变为:
和N-gram模型类似的,我们假设g1…gn条件独立,因此:
Pr(gj|C(g))(j=1..n)是gi在C(g)条件下出现的概率。它可以由贝叶斯公式估计为:
因为g属于上下文,让g=gi。G(g)和g在一个方法中至少共现一次,并且他们有父子关系,因此我们给出这个对的概率:
由此可得公式(5):
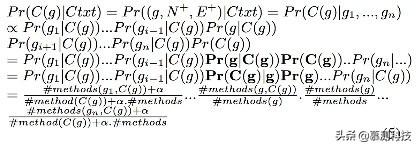
关于概率乘积的计算由于在[0,1]区间内,所以弹性很小。因此我们把它换成log。从而得到公式(6):
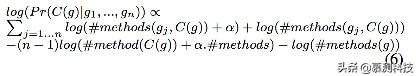
4.GRALAN IN API ELEMENT SUGGESTION(GRALAN在API推荐中的使用)
本节解释如何把GraLan用在API元素推荐引擎上。API推荐任务指的是在某个正在编辑的代码的某个位置(不一定是代码末尾)推荐一个API元素。图3a显示了部分正在编辑的代码例子。一个开发人员请求引擎在while循环处(11行)推荐API。
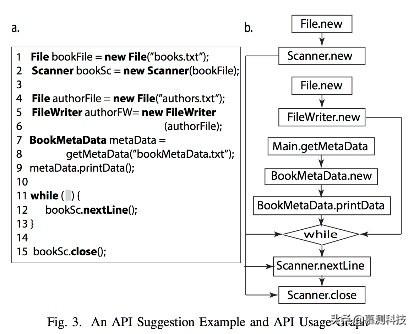
图3 API推荐示例及API使用图
A.算法(Algorithm)
概述:API推荐算法的核心思想是从当前正在编辑的文档中抽取出使用子图(Groums),把它们视为上下文。然后算法利用GraLan计算孩子图在给定使用图的情况下的概率。每个孩子图有一个相关的额外节点。这些孩子图被收集并排序作为候选API元素进行推荐。这些概率用来作为候选排序的分数。
算法细节:图4展示了我们算法的pseudo-code描述。输入包括当前代码C、当前位置L以及训练好的模型和图数据库GD。首先我们用Eclipse的JAVA解析器生成AST。如果正在编辑的代码不完整从而无法解析,那么我们使用PPA工具进行解析。PPA工具接收部分代码并返回AST。

图4 API推荐算法
然而,在一些情况下,可能存在一些尚未解决的节点。比方说,他们的语法或者数据类型是不确定的。因此,它们被设定为未知(unknown)类型。接着我们从AST利用Groum构建算法构建Groum(2行)。由于当前节点可能存在不完整性,如果AST中存在尚未解决的节点,那么就把它当做一个图。图3a的Groum在图3b中。
接着,APISuggestion从Groum Ghetto当前位置L中确定上下文图列表(3行)。我们使用环绕L的API图作为上下文。一个或多个子图通过添加附加节点和边生成,这些字图作为候选者放入列表中。关于上下文图的细节在IV-C中详细讲。图5展示了图3中代码的上下文图。
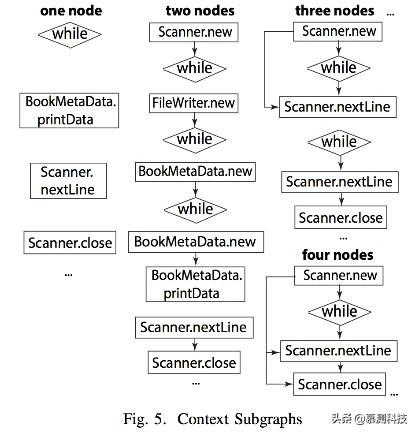
图 5 上下文子图
接着,对于上下文中的每个图,我们从图数据库GD中搜索并用公式6计算每个子图的得分。根据得分排序,从而得到候选API推荐(10行)。
表1展示了一些图3代码的上下文图和它的相关子图。有趣的是,我们把这些图当做节点标签的序列。添加一个额外节点贝表示为加粗体,如Scanner.hasNextLine来自孩子图#4。更重要的是,一个附加节点N+将考虑到位置信息L。N+和其他节点的相对顺序与它们进入图的顺序有关。比如,Scanner.nextLine是在当前位置L和WHILE之后的。因此拥有Scanner.nextLine的子图在N+或WHILE之前的将不被考虑。任何图有条件β。β用来限制子图的数量,否则子图会指数级增长。举例来说给定一个集合S,集合有BookMetaData.printData, WHILE, Scanner.nextLine, Scanner.close并设定β=5,它的上下文图的一部分在图5中。
5.AST-BASED LANGUAGE MODEL(基于AST的语言模型)
我们进一步由GraLan得到ASTLan。ASTLan是一个基于AST的语言模型。它用来支持语法模板推荐以及流行语法模板检测。图6是关于推荐的例子。卡法人员写了一个while循环并声明了一个字符串变量bookInfo。游标指向bookInfo的尾部。由ASTLan构建的引擎能够提供一个由if和continue组成的语法模式,因为它经常出现在while中。这些常见语法结构(比如包含if-continue的while循环)称为语法模板。我们的引擎能够推荐这些模板从而实现代码补全。与现有使用预定义模板的IDE不同,我们的引擎能够推荐考虑当前位置及代码最有可能需要的语法模板。
A. 生成过程(Generative Process)
和GraLan类似,生成过程的基础是AST之间的父子关系。我们希望模型能够从小的AST中生成更大的AST。
定义5(Parent and Children ASTs):一个AST C是另一个AST P的子图的条件是向C中添加一个最小AST T能够形成P。并且P和C语法正确。
一个一个最小T意味着没有办法删除T中任何一个节点并且T还合法。第一个条件保证新添加的T是一个最小的T。举例来说,图6中的AST{a,b}是满足条件的,因为我们不能添加给BlockStatement任何其他更小的片段来形成一个合法的AST。三个节点IfStatement、Cond和ContinueStatement是必要的。我们之所以需要这些限制是因为我们要推荐最小模板。比如,下面这个代码推荐例子就不满足要求:

因为它们太大了并且包含图6b中的AST。
第二个限制条件的根本原因是因为语法正确性是我们推荐合法模板的必要条件。如果有人想要构建一个模板推荐引擎但不关心语法正确性,那么这个条件就不需要。在图6b中,推荐模板由if和continue语句组成。关于Ifstatement、Cond和ContinueStatemt的相关子树是合法的。但是如果我们只添加IfStatement->Cond。结果树将不合法。最后,和GraLan一样,父树有多个子树,孩子树有很多父树。
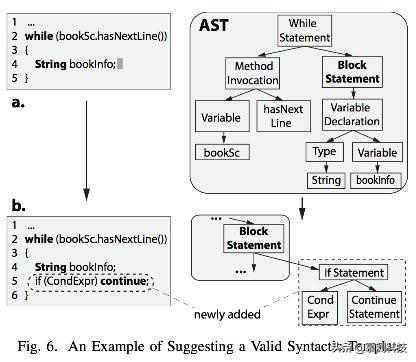
图6 推荐合法模板的例子
B. AST中的规范化
AST节点的值和位置有关。譬如,变量图6中的bookSc是一个和项目相关但是不一定在其他项目中存在的变量。为了检测语法模板并提升ASTLan的能力,我们需要在AST树上进行规范化。AST树通过对节点进行重标签来规范化。对于子树中的局部变量节点,它的新标签通过alpha-renaming来命名。举例来说,在图6a中,bookSc变成var1Scanner,bookInfo变成var2String。
C. 构建AST的父子数据库(Building Database of Parent and Children ASTs)
ASTLan的一个重要任务是挖掘从数据集中挖掘所有语法正确的父AST和子AST。给定一个方法,我们通过解析它建立AST。我们自顶向下定义该AST的父AST和子AST。
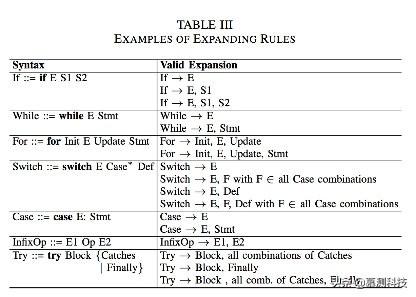
第一步是发现一个或者多个合法的AST片段,然后用它们作为初始AST。我们检查第一个方法的BlockStatement。取决于AST的节点类型c,我们考虑它的孩子节点的类型使得该树合法。举例来说,如果c是if节点,我们扩增c到它的孩子们有两种可能的方法。一种是连接if到E和S1。或者连接if到所有三个节点E,S1和S2(表3)。注意,连接if和E以及S2是一个非法的AST片段,因为if语句需要true分支。表3显示了一些扩增的规则。接着我们连接BlockStatement到c,并且对于c的孩子节点根据孩子节点二选一。对于每种可能,我们利用同样的扩展规则重复扩展直到看到叶子节点。接着,另外一种可能性也被探索到。对于每步,在寻找到c的孩子节点后,如果造成的AST片段是合法的,我们就把它作为一个初始父节点AST。图6a所示,经过这个阶段,我们有了两个初始化父AST,左边的是while右边的是while和node BlockStatement。
在第二个阶段,对于每个父AST,我们考虑AST以外的其他边。对于每个边,我们使用ni表示相关节点。比如,对于P1,ni是BlockStatement。对于P2,ni是VariableDeclaration。我们希望通过扩展P到ni找到子AST。为了达到这个目的,我们使用了和表3相同的扩增原则。之后,我们收集ni以及每个合法的组合。拥有最少节点的子树用来连接到P。拥有最多节点的将被用作孩子节点或者丢弃。距离来说,包含if的数将用来作为子树的一部分。这个过程是不断重复的。
为了找到其他父AST,我们把P的父AST和其他有关的数相连。如果结果树是合法的,它就是我们的其他父AST。
D. 上下文树(Context Trees)
首先,为了确定AST的上下文树,我们先找到最小的和源码及位置相关的合法树。我们把它的根叫做NL。接着,我们收集所有合法树ti,它们满足两个条件,1)ti包含NL;2)ti的高不超过上限β。
在GraLan中,这些相邻节点提供了生成下一节点的上下文。在图6a中,NL是BlockStatement。如果β=3,树的更是WhileStatment和BlockStatement,那么高小于4的就在上下文中。
E. 基于贝叶斯统计推理进行合法AST推荐(Valid AST Suggestion with Bayesian Statistical Inference)
利用AST父子关系和上下文树,我们可以将贝叶斯统计推理用在计算新的合法AST出现的概率上。公式如下:
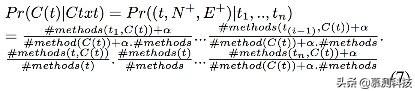
概率计算原理和过程和前面章节的GraLan相似。两个算法区别在于,一,PPA用在了AST构建上。二,我们收集上下文树而不是上下文图。三、对于每个环境树t,树库用来寻找子树AST。对于公式7的计算是基于环境树的。最后,我们把计算出来的概率作为AST子树排序的标准。
- 实验评估(EMPIRICAL EVALUATION)
我们在不同数据大小和不同参数情况下进行了多种实验来研究GraLan和ASTLan的代码推荐准确度。并且将GraLan于行业先进方法进行比较。实验在一台Inter Xeon E5-2620 2.1GHz(32G内存)的电脑上进行。
我们从Source-Forge.net上收集了大量Java项目源码。为了得到高质量的代码,我们过滤了一些不能解析或者是一些实验性、玩偶类型的代码。我们只保留了修改次数超过100次的项目。我们把最后一次修改的项目作为数据集。接着我们排除掉重复代码。对于每个项目,我们使用Eclipse的JAVA解析器解析代码并构建AST和使用图(Groums)。在实验中农,对于API我们只关注JDK中的API。我们构建Groums和AST的数据集。总的来说,我们构建了大概800M的图其中55M是不同的以及1.047B的AST。
A. API推荐准确率(API Recommendation Accuracy)
首先我们研究GraLan在API推荐上的准确率。我们选择了一个叫做“Spring Framework”的项目。这个项目不在我们数据集中。它有很长的历史和9042个方法。我们保留了3949个使用JDK API的方法。
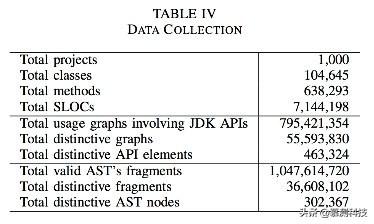
过程和设置:对每个方法体吗,我们收集一系列的API元素和控制单元(如while,if等)并且将它们按照出现顺序排序。接下来我把它们统称为API。我们从第二个API开始顺序遍历这个列表直到最后(之所以不从第一个开始是因为我们需要上下文)。在第i个位置,我们使用GraLan计算top-k可能的API。我们只预测JDK的API因为我们的数据集(表4)只建立了这些JDK的API。
为了达到这个目的,由于之前的代码可能是不完整的,我们首先使用PPA工具进行部分解析和语义分析并构建AST,接着构建Groum。对于尚未完成的节点我们把它视为单节点图。接着我们使用与位置i最近的θ之前的API。从这些API中,我们发掘上下文子图。接着我们使用GraLan推荐排好序的API。如果真是API在这些推荐的当中,我们就认为系统正确了。总的来说,对于所有方法,GraLan进行了10065次推荐。我们用毫秒测量这些推荐。
1)准确率敏感性分析-参数的影响:让我们来解释三个参数对于GraLan API推荐准确率的影响。我们首先是实验θ的影响。表5显示不同的θ的实验结果。可以看到当θ增加的时候,准确率也增加了。因此相关API应当被添加到上下文中。但是当θ高于8的时候,准确率变化不大。
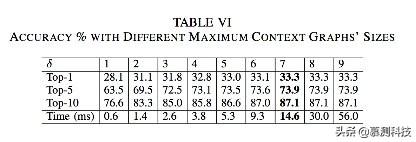
接着我们研究δ对准确率的影响。δ是实验中的第二个界限,来限制环境图中的节点数量。我们把θ设置为8.可以在表6中看到δ增长到7准确率达到最高值。
我们也分析了训练集对准确率的影响。在这个实验当中,我们把θ设置为8,δ为7.首先我们从原始1000项目随机选择300个项目。接着在300个项目中又随机选择100个项目。建立了3个数据库。在这上面训练不同的GraLan。实验结果在表7中。随着训练集的增加,准确率提升了1-5%。
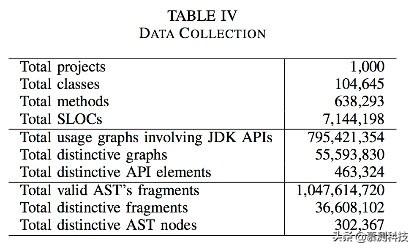
在表7最后一行可以看到,GraLan实现了很高的准确率。对于*考虑一个推荐的条件下,GraLan有1/3的样例是能够正确推荐API元素的。在1/2的样例中,正确的API元素可以在两个推荐中找到。在3/4的样例中,正确的API元素可以在被推荐的前5项中找到。*
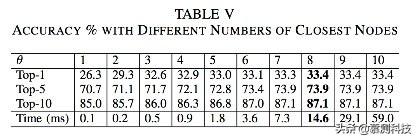
更重要的是,表5和表6显示,θ和δ增加,推荐效率将增加。对于交互式IDE的使用,这是很好的。
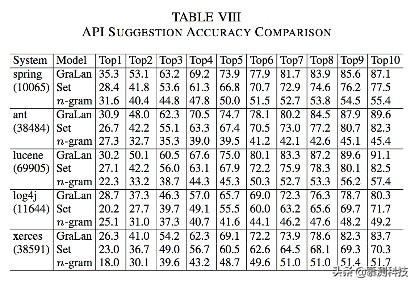
2)准确率比较: 接下来我们把GraLan和两种行业先进水平的方法比较,一种是基于集合的,一种是基于n-gram的。表4显示我们的实验结果远远好于它们。
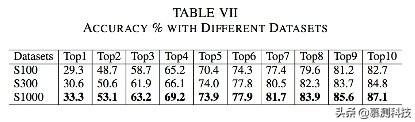
表8显示在准确率的比较上,GraLan在top1的准确率比他们的方法高出3.1-8.5%。在top5的准确率上比基于集合的方法提升了7.1-10.2%,比基于N-gram的方法提升了20.4-35.2%。这些提升在top-10上是7.3-13.4%和31.1-44.2%。
B. AST 推荐准确率
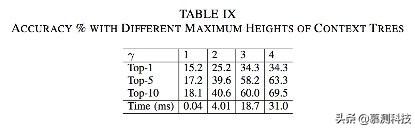
1)准确率敏感性分析:我们的第一个实验室研究参数γ(最大环境树高度)对推荐准确率的影响。我们使用不同的伽马,如表9所示,当γ增加时,准确率增加。
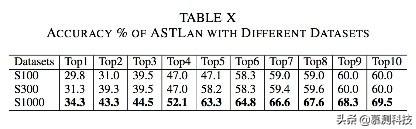
接着我们构建不同大小的数据集并在其上训练ASTLan。我们把γ设定为4.结果在表10所示。更多的数据集能够提高准确率。
从表10的最后一行可以看到,ASTLan具有很好的准确率表现。对于单个建议,在34%的用例上取的了正确的效果。对于考虑5个候选集,正确率可以达到63%。
注意,n-gram模型不能实现正确推荐模板的效果。因此我们没有把ASTLan和N-gram比较。
2)常见语法模板挖掘:我们使用ASTLan的数据集挖掘常用的语法模板。这里是两个例子:

我们挖掘了400个模板,其中366个正确。
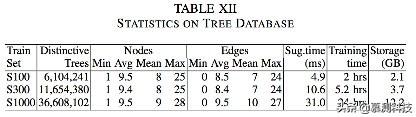
C.图和树数据库以及推荐时间
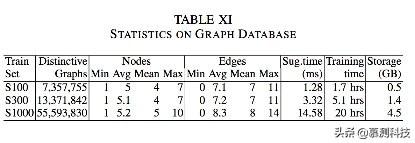
我们还研究了模型进行推荐所花的时间。表11和12显示了在图和AST上的统计。
7.结论
我们提出了GRALAN,一种基于图的统计语言模型。它从源码库中学习并计算使用图的概率。我们使用GraLAN建立了一个API推荐引擎以及一个基于AST的语言模型,ASTLAn.ASTLAN能够给出合法模板推荐。我们的实验效果超过了现存的行业先进水平。
致谢
本文由南京大学软件学院2019级硕士袁为翻译转述。
感谢国家重点研发计划(2018YFB1403400)和国家自然科学基金(61690200)支持!

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)