kaldi语音识别实战pdf_Kaldi 学习基础篇(一)
Kaldi 介绍Kaldi 是由 C++ 编写的语⾳识别工具,其目的在于为语⾳识别研究者提供一个研究和使用的平台。Docker 基础命令本节简单介绍在安装 Kaldi 过程中使⽤到的 Docker 基础命令,如读者需要更加详细的学习 Docker ,请主动寻找相应的专业书籍、文档学习。 本章中所用到的 Docker 命令如下:注意: 如果读者需要使用GPU来进⾏计算,需要安装 Nvidia-doc
Kaldi 介绍
Kaldi 是由 C++ 编写的语⾳识别工具,其目的在于为语⾳识别研究者提供一个研究和使用的平台。
Docker 基础命令
本节简单介绍在安装 Kaldi 过程中使⽤到的 Docker 基础命令,如读者需要更加详细的学习 Docker ,请主动寻找相应的专业书籍、文档学习。 本章中所用到的 Docker 命令如下:

注意: 如果读者需要使用GPU来进⾏计算,需要安装 Nvidia-docker , 该软件的运⾏命令与 Docker 的运⾏命令一致。Docker 与 Nvidia-docker 的安装过程这⾥不做介绍。
Kaldi 环境搭建
本⽂主要通过使⽤ Docker 和 Nvidia-docker 构建 Ubuntu 环境对 Kaldi 进⾏搭建。Docker 针对的是⽆ GPU 的环境,Nvidia-docker 针对的是需要使用 GPU 计算的环境,如果读者机器器上存在 GPU 计算资源, 请使用Nvidia-docker,使⽤ Nvidia 官⽅提供的 CUDA 镜像,可以省去安装 CUDA 的麻烦。Kaldi 的环境搭建分为两部分,一部分为依赖⼯具安装,另一部分为⾃自身源码编译。
Kaldi 环境搭建
这⾥假设读者电脑已经安装 Docker 和 Nvidia-docker ,如果未安装,请先安装再进行如下操作。
首先通过 Docker 获取相应的 Ubuntu 系统。

之后启动该镜像,并安装相应软件
接下来进⾏ Kaldi 的第⼀部分安装,第⼀部分主要是针对 Kaldi 依赖⼯具的安装比如 Openfst、Portaudio等。安装步骤如下:

Kaldi 安装的第⼆部分为源码编译部分,这⾥的⾸要条件是第一部分正常安装之后,第⼆部分才能顺利完成。安装步骤如下:
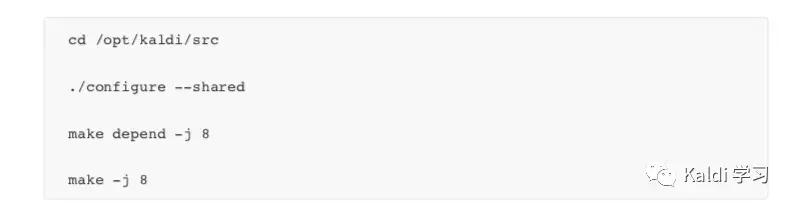
只有以上两部顺利安装,Kaldi 的安装才算成功。 最后读者可以退出终端,使⽤命令:

来构建⼀个可以⻓期使⽤的 Docker 镜像,当然读者也可以使⽤作者已经做好的Dockerfile ⽂文件来生成Docker 镜像,或者直接拉取作者已经做好的 Docker 镜像。
Kaldi ⽬目录介绍
本节主要对 Kaldi 的⽬录进⾏详细介绍。
Kaldi 一级目录
在Kaldi 的⼀级主⽬录中(也就是进⼊Kaldi⽬录之后,⼤家所看到的所有目录)包括:egs、misc、scripts、src、tools、windows。
- egs : 此⽬录为 Kaldi 例⼦⽬录,其中例⼦包含了不乏语⾳识别、语种识别、声纹识别、关键字识别等。
- misc : 此⽬录包含了⼀些 pdf、以及相关 docker、htk 等资源
- scripts: 此⽬录只用来存放 Rnnlm,以及相应的运⾏脚本。
- src : 此⽬录为 Kaldi 的源代码⽬录,Kaldi 的多数算法的源代码都存放于此,其中不乏GMM、Ivector、Nnet等⼀系列的算法。
- tools: 此⽬录主要存放 Kaldi 依赖库的安装脚本
- windows: 此目录为在windows平台运⾏所必须的脚本以及相关的执⾏程序。
Kaldi ⼀级⽬录 egs
Egs ⽬录主要用于存放 Kaldi 的所有例程,这⾥会统⼀罗列出相关⽂件所包含的相关例⼦子。
- aishell : 此⽬录为中⽂语⾳识别和声纹识别相关例⼦
- aishell2 : 此⽬录为中⽂语⾳识别例⼦,但是针对aishell在脚本⽅面更加规整。
- ami : 此⽬录主要涉及到多信道语⾳识别的例子
- an4 : 此例⼦为CMU提供语⾳识别例子,并没有涉及神经⽹络。
- apiai_decode: 此例⼦为解码器使⽤的例子,其中包含了如何使⽤预训练模型,这⾥主要针对的是Nnet3解码
- aspire: 此为ASpIRE 挑战赛的例⼦,其中包含了怎样使⽤噪声数据构建多条件数据的例子
- aurora4: 此例子主要介绍RBM 预训练
- babel: 此例子主要是⽤来训练 KWS (Key Word Search)
- babel_multilang: 此例子为训练多语⾳ KWS
- bentham: ⼿写笔识别的例⼦
- bn_music_speech : ⾳音与语⾳区分的例子
- callhome_diarization : 说话⼈分割的例⼦
- callhome_etyptian: 埃及语语⾳识别例⼦
- chime1-5 : 主要针对CHiME 竞赛开放的例子
- cigar : 图像分类的例子
- commonvoice: Mozilla Common Voice 语⾳识别的例子
- csj : 日语语⾳识别例子
- dihard_2018 : DiHARD Speech Diarization CHALLENGE 的例子
- fame : 富⾥⻄语语⾳识别和声纹识别的例子。
- farsdat: 主要⽤来声学语⾳研究和语⾳音识别的例子
- fisher_callhome_spanish : 使⽤Callhome预料进⾏语⾳识别的例子
- fisher_english: 英⽂双声道 8000 Hz 对话电话语⾳数据集的语⾳识别例子
- fisher_swbd: 包含 fisher 数据集以及 swbd 数据集的语⾳识别例子
- gale_arabic: 阿拉伯语语⾳识别例子
- gale_mandarin: 普通话语⾳识别例子
- gp: 全球电话语⾳识别例子(多语种语⾳识别例子)
- heroico: ⻄班⽛语⾳识别例子
- houst: 普通话电话语⾳识别例子
- hub4_english : 英语新闻⼴播语⾳识别例子
- hub4_spanish: ⻄班⽛新闻⼴播语⾳识别例子
- iam: IAM 手写笔识别例子
- iban: 语⾳识别例子
- ifnenit: 阿拉伯语⼿写笔识别例子
- librispeech: 英语语音识别例子
- re/lre07 : 语种识别例子
- madcat_ar : ⼿写笔识别例子
- madcat_zh: 中⽂⼿写笔识别例子
- mini_librispeech: 英语语⾳识别例子
- mult_en: 英语LVCSR 例子
- pub: RNNLM 模型构建例子
- reverb: REVERB 挑战赛例子
- rimes: 法语手写笔识别例子
- rm: 英语语音识别例子,包含了如何进⾏迁移学习
- sitw: sitw 说话⼈识别挑战赛的例子
- sprakbanken: 丹麦语语⾳识别例子
- sprakbanken_swe: 瑞典语⾳识别例子
- sre08/10/16: 说话⼈识别的例子
- svhn: 图像分类的例子
- swahili: 班图人语⾳识别例子
- swab: 双声道对话语⾳识别例子
- tedium: 英语语⾳识别例子
- thchs30: 普通话语⾳识别例子
- tidigits: 基础语⾳识别的例子
- timit: 主要是GMM/HMM 语⾳识别例子
- tunisian_msa: 阿拉伯语⾳识别例子
- uw3: OCR 识别例子
- voxceleb: 说话⼈识别例子
- vystadial_cz: 捷克语语⾳识别例子
- voxforge: 基础语⾳识别例子,以及对应的在线demo的例子
- vystadial_en: 英⽂语⾳识别例子
- wsj: wsj 英⽂语⾳音识别例子
- yesno: 独⽴词语音识别例子
- yomdle_fa/korean/russian/tamil/zh: OCR 识别例子
- zeroth_korean: 朝鲜语语音识别例子
注意: 虽然 Egs 中存放了⼤量的例子,但由于某些外部原因并不是所有例子的数据都能免费获得。
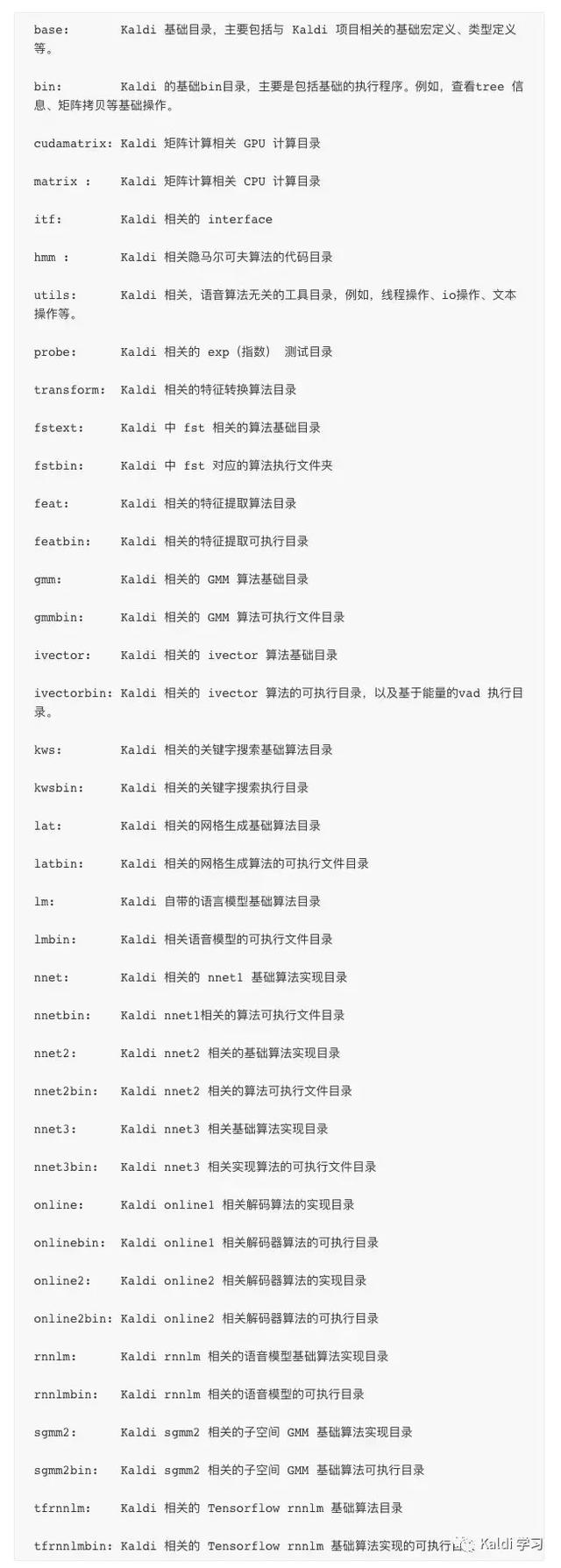
Kaldi ⼀一级⽬目录 src
src⽬目录为 Kaldi 的源码目录,主要保存了包括GMM、HMM等在内的⼤部分 Kaldi 语⾳项⽬目源代码。这里分别对相关算法⽬录进⾏介绍。
在 src ⽬录中,有两类文件夹,⼀类是算法原⽬录,一类为算法组合⽣成bin(可执⾏行行程序)目录。
Kaldi Egs Aishell 例子黑箱运行
本节的目的在于,让读者在不了解 Kaldi 语音识别相关的算法的情况下,能过顺利运行 Aishell 的例子,并顺利获得语音识别模型。
首先需要有几个注意点:
- 如果需要运行神经网络相关的算法,确保机器拥有GPU运算能力。
- 确保以上 Kaldi 编译成功。
- 如果网络下载速度有限,请离线下载相关数据集。
- 确定运行代码机器内存和硬盘大小。
本例子完全运行需要硬盘资源为76G,所以需要确定硬盘是否有足够的空间。
Aishell 例子运行
为了能过顺利黑箱运行 Aishell 语音识别的例子。需要对 /opt/kaldi/egs/aishell/s5 中的 run.sh 脚本进行几点修改。
假设 Aishell 的语音数据已经全部下载,目录存放于/newdata/corpus/aishell , 那么对应的 run.sh 脚本修改如下:

同时,由于我们的数据集已经下载,故需要注释掉 Aishell 数据相关的下载脚本,修改如下:

由于大家机器、内存和CPU数量的不同,在部分脚本相对应的运行进程上也要进行部分修改,这里需要大家根据自己实际机器情况。假设运行的机器为16G 内存,run.sh 脚本修改为,vim 打开 run.sh ,进入命令模式:

同时,需要修改 local/nnet3/run_ivector_common.sh 该脚本中对应的 nj 个数,修改方法如上一步。
注意: 由于在运行神经网络计算之前会进行 ivector 计算,因此需要根据运行机器的内存情况进行重新设置。这里建议:如果运行机器内存不到32G,在此例子中 ivector 的 nj 个数设置为 1,对应之上脚本的 118 行。
最后,需要注意,如果需要进行神经网络相关训练操作,需要对 local/chain/run_tdnn.sh 进行修改,修改操作为将 num_jobs_initial 和 num_jobs_final 统一修改成该训练机器所对应的GPU个数。修改如下图:

最后,回到 run.sh 的目录中,使用命令:

确保 run.sh 能够在后台运行。直至出现错误或者运行成功自动结束。
运行结束之后,我们可以在 exp 目录下的对应目录下找到对应的错误率,以及识别结果。例如,使用chain 来构建的神经网络,目录位置如下:

目录中存放的解码所需要的大部分信息。
如何在黑箱情况下,使用独立语音进行模型构建
本节假设读者已经成功运行上一节黑箱的例子,相信大家做语音识别的初衷亦或者兴趣点在于如何使用自己的语音训练模型,那么本节的主要目的就在于告诉大家如何在aishell的基础上,使用自己的语音构建模型。
学习本节,读者依旧不需要了解任何的 Kaldi 语音识别相关内容。此时,读者可能会有疑问,既然是黑箱,那如何能够使用独立语音训练集训练出自己的模型呢?
其实很简单,我们这里有两种方法提供给大家:
方法一: 我们只需要模仿 Aishell 的数据存放规律进行存放即可。
方法二: 如果我们现有的独立数据集有自己的规律存放,那么只需要修改针对性的修改 run.sh 中的两个脚本即可。
方法一这里不做详细说明,大家根据上一节使用的aishell的数据方式模仿存储即可。这里针对方法二进行示范。
再次回到 run.sh 脚本中,我们可以发现,Aishell 的数据处理逻辑主要存在于两个子脚本中。他们分别为如图所示:

这两个脚本即是我们需要修改的数据处理脚本。
首先看第一个脚本: local/aishell_prepare_dict.sh,此脚本的作用在于处理aishell 语音数据集所包含的发音字典信息。由于我们使用的是我们自己的独立数据集合,因此,我们需要通过我们自己的独立语音数据集获取相对应的发音词典。对应于aishell 数据集中的lexicon.txt 文件。
第二步:修改local/aishell_data_prep.sh 脚本。该脚本主要是用来读取训练数据集、验证集以及测试集相对应的语音和语音相对应文本的对应关系。
由于第一步只需要进行匹配和人工标注,这里不多赘述。这里简单说明一下第二部分如何修改。
假设我们的语音数据集的分布为如图所示:
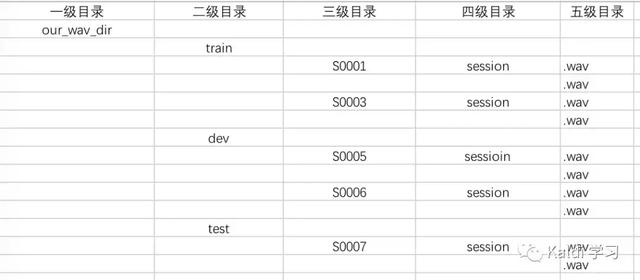
同时,我们可以通过aishell 的数据,看出数据存放格式如下图所示:
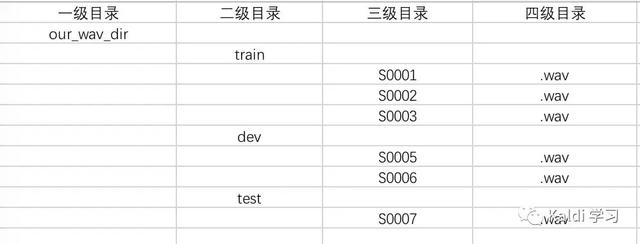
那么,我们只需要将我们的数据集中session文件夹去除掉,亦或者修改脚本中如下图所示的代码即可:
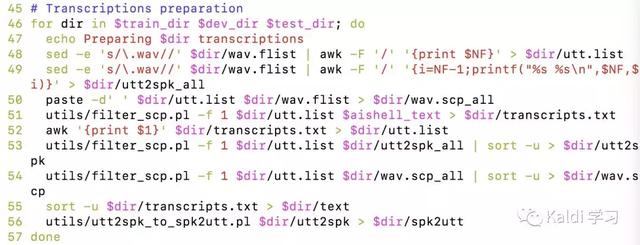
只需要将49行的NF-1 修改为 NF-2即可。这样就可以顺利运行我们自己的独立语音数据集合。
总结
本章主要介绍了Kaldi 相关的 Docker 基础操作,并介绍了如何正确安装 Kaldi 以及 Kaldi 相关的目录结构,之后介绍了黑盒运行 AIshell 的例子,最后简单介绍了如何修改脚本来运行自己的独立语音数据集。
欢迎各位关注Kaldi 语音学习公众号:Kaldi 学习

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)