深度学习在训练时对图片随机剪裁(random crop)
文章目录为何要采取random crop?对图片进行随机裁减和缩放有些图片有4个颜色通道图像转换成torch.Tensor对象Reference为何要采取random crop?在训练学习器时对图片进行随机裁减,背后的一个直觉就是可以进行数据增广(data augmentation),防止学习器陷入过拟合。假设类别CCC的主要特征为FFF,采集得到的图片包含背景噪声BBB,即现在CCC表示为(F,
为何要采取random crop?
在训练学习器时对图片进行随机裁减,背后的一个直觉就是可以进行数据增广(data augmentation),防止学习器陷入过拟合。假设类别
C
C
C的主要特征为
F
F
F,采集得到的图片包含背景噪声
B
B
B,即现在
C
C
C表示为
(
F
,
B
)
(F, B)
(F,B),我们本来期望学习关系
f
∗
:
F
→
C
f^*: F \to C
f∗:F→C,结果现在可能学习成关系
f
^
:
(
F
,
B
)
→
C
\hat{f} : (F, B) \to C
f^:(F,B)→C,从而陷入过拟合。对图片进行随机裁减,类别
C
C
C的目标物一般处于图片正中间,
F
F
F很大概率不会被裁减到,而
B
B
B则相反,这相当于在训练时对二者进行了权重分配,考虑极端情形(即权重分配只有0或1):
X
c
(
1
)
=
(
1
⋅
F
,
0
⋅
B
)
,
X
c
(
2
)
=
(
1
⋅
F
,
1
⋅
B
)
,
X
c
(
3
)
=
(
1
⋅
F
,
0
⋅
B
)
,
…
X_c^{(1)} = (1 \cdot F, 0 \cdot B), X_c^{(2)} = (1 \cdot F, 1 \cdot B), X_c^{(3)} = (1 \cdot F, 0 \cdot B), \dots
Xc(1)=(1⋅F,0⋅B),Xc(2)=(1⋅F,1⋅B),Xc(3)=(1⋅F,0⋅B),…
此时,
F
F
F的信息增益较大,学习器更有可能倾向于学习关系
f
∗
:
F
→
C
f^*: F \to C
f∗:F→C而忽略掉
B
B
B。
更多信息推荐阅读:深度学习训练中为什么要将图片随机剪裁(random crop)。
对图片进行随机裁减和缩放
对图片随机0.6~1.0比率大小的区域进行裁剪
def random_crop(image):
min_ratio = 0.6
max_ratio = 1
w, h = image.size
ratio = random.random()
scale = min_ratio + ratio * (max_ratio - min_ratio)
new_h = int(h * scale)
new_w = int(w * scale)
y = np.random.randint(0, h - new_h)
x = np.random.randint(0, w - new_w)
image = image.crop((x, y, x + new_w, y + new_h))
return image
def resize(image):
conf = configparser.ConfigParser()
conf.read('./config.txt')
receptive_field_size = eval(conf.get('net', 'receptive_field_size'))
image = image.resize((receptive_field_size, receptive_field_size))
return image
调用代码
from PIL.Image import open as imread
import random
import matplotlib.pyplot as plt
def data_handle(image_path):
res = None
# res = resize(image)
res = resize(random_crop(image))
plt.imshow(res)
plt.show()
return res
if __name__ == '__main__':
data_handle('./demo.jpg')
更多信息推荐阅读:【图像处理】python图片随机缩放(resize)和随机裁剪(crop)的三种方式。
有些图片有4个颜色通道
有些采集来的图片具有4个颜色通道,即RGBA,最后1个是透明度,我们要把它转换成3颜色通道,代码如下
from PIL import Image
img = Image.open('./demo.png')
img = img.convert("RGB") # 将一个rgba四通道转化为rgb三通道
更多信息推荐阅读:图片格式转换:4通道转换为3通道;批量改图片为.jpg格式。
图像转换成torch.Tensor对象
图片读取出来是 H × W × C H \times W \times C H×W×C格式,其中 C C C是特征通道个数,numpy和TensorFlow都可以正常处理,但PyTorch需要 C × H × W C \times H \times W C×H×W格式,我们需要转换一下:
image = imread(image_path).convert('RGB')
image = util.resize(util.random_crop(image))
image = np.transpose(np.array(image), (2, 0, 1))
此外,要注意
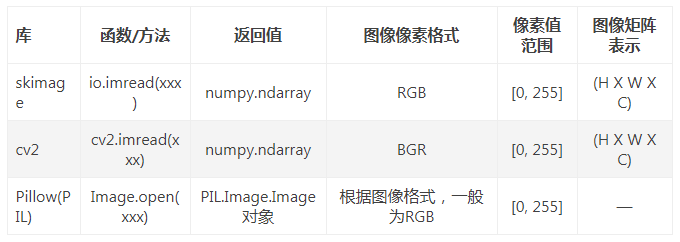
更多信息推荐阅读:pytorch学习(五)—图像的加载/读取方式。
Reference
深度学习训练中为什么要将图片随机剪裁(random crop)
【图像处理】python图片随机缩放(resize)和随机裁剪(crop)的三种方式
图片格式转换:4通道转换为3通道;批量改图片为.jpg格式
pytorch学习(五)—图像的加载/读取方式

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)