opencv 骨架提取_深度学习——OpenCV实现银行卡号识别,字符识别算法你知多少?
以下文章来源于AI科技大本营 ,作者李秋键随着计算机视觉在我们生活中的应用越来越广泛,大量的字符识别和提取应用逐渐变得越来越受欢迎,同时也便利了我们的生活。像我们生活中的凭借身份码取快递、超市扫码支付的机器等等。字符识别是模式识别的一个重要应用,首先提取待识别字符的特征;然后对提取出来的特征跟字符模板的特征匹配;最后根据准则判定该字符所属的类别。不同的训练方法,不同的特征提取, 不同的匹配规则,就
以下文章来源于AI科技大本营 ,作者李秋键
随着计算机视觉在我们生活中的应用越来越广泛,大量的字符识别和提取应用逐渐变得越来越受欢迎,同时也便利了我们的生活。像我们生活中的凭借身份码取快递、超市扫码支付的机器等等。
字符识别是模式识别的一个重要应用,首先提取待识别字符的特征;然后对提取出来的特征跟字符模板的特征匹配;最后根据准则判定该字符所属的类别。不同的训练方法,不同的特征提取, 不同的匹配规则,就相应的有不同的字符识别方法,基本上很多就是在这些地方做改进,或者是采用新的规则。但是万变不离其宗。
1、模板匹配字符识别算法。
模板匹配字符识别算法是图像识别中的经典算法之一,该算法的核心思想是:通过比较待识别字符图像的字符特征和标准模板的字符特征,计算两者之间的相似性,相似性最大的标准模板的字符即为待识别的字符。
2、神经网络字符识别算法
主要思想:通过神经网络学习大量字符样本,从而得到字符的样本特征。当对待识别的字符进行识别时,神经网络就会将待识别字符的特征和之前得到的样本特征匹配,从而识别出字符。
3、支持向量机
主要思想:同上,都是先得到样本特征,进行训练,然后再分类。SVM应该算是用的最多的分类方法,一般大多适合于二分类问题,在这里就需要使用多分类器来构造。
今天我们就简单的利用OpenCV处理通过提取轮廓和匹配等方式来实现模式匹配的字符识别。
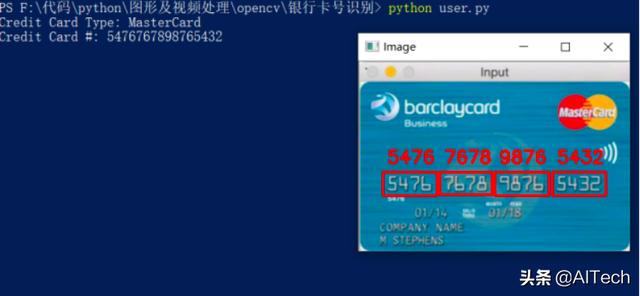
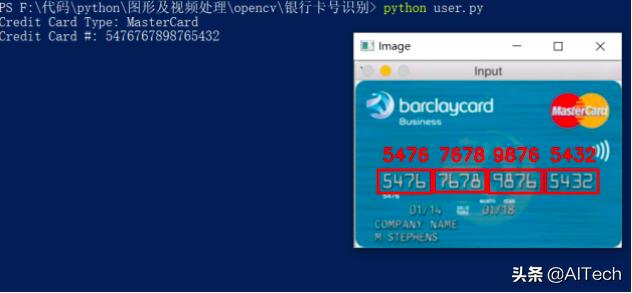
效果图如下:

实验前的准备
首先我们使用的python版本是3.6.5所用到的库有cv2库用来图像处理;
Numpy库用来矩阵运算,这里主要用来对图像像素值相关性处理;imutils库可以轻松实现基本图像处理功能,如平移,旋转,调整大小,骨架化和显示Matplotlib图像。

程序的搭建
1、参考图像的读取和处理:
参考图像如下,因为银行卡号主要只有0~9这几个数字,为了方便识别数字,我们直接利用这张图片里的数值作为匹配样式:
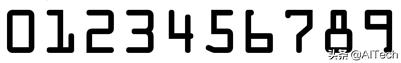
所以下面我们要做的事很明显,就是要将其中每个数字隔开方便后面匹配。
代码如下:
#定义了一个字典 FIRST_NUMBER ,它将第一个数字映射到相应的信用卡类型。FIRST_NUMBER = { "3": "American Express", "4": "Visa", "5": "MasterCard", "6": "Discover Card"}#参考数字图像,用于匹配#灰度化及二值化ref=cv2.imread("1.png")ref = cv2.cvtColor(ref, cv2.COLOR_BGR2GRAY)ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]#查找轮廓,从左往右排序refCnts = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)refCnts = imutils.grab_contours(refCnts)refCnts = contours.sort_contours(refCnts, method="left-to-right")[0]digits = {}#对于其中每一个轮廓进行提循环,i为数字名称,c为轮廓,我们将每个数字0-9(字典键)与第30行的每个roi 图像(字典值)相关联 。for (i,c) in enumerate(refCnts): (x,y,w,h)=cv2.boundingRect(c) roi=ref[y:y+h,x:x+w] roi=cv2.resize(roi,(57,88)) digits[i]=roi#初始化几个结构化内核,构造了两个这样的内核 - 一个矩形和一个正方形。我们将使用矩形的一个用于Top-hat形态运算符,将方形一个用于关闭操作。rectKernel=cv2.getStructuringElement(cv2.MORPH_RECT,(9,3))sqKernel=cv2.getStructuringElement(cv2.MORPH_RECT,(5,5))2、获取数字位置分组:
这里需要识别的图片为:

我们需要进行的处理包括二值化和Top-hat形态操作,最后通过findContours函数框出位置。
其中代码如下:
#加载信用卡图像image=cv2.imread("3.jpg")image=imutils.resize(image,width=300)gray=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)#执行Top-hat形态操作,将结果存储为 tophat,Top-hat操作显示了深色背景下的亮区(即信用卡号)tophat=cv2.morphologyEx(gray,cv2.MORPH_TOPHAT,rectKernel)#计算沿x方向的渐变在计算gradX 数组中每个元素的绝对值之后 ,我们采取一些步骤将值缩放到范围[0-255](因为图像当前是浮点数据类型)。要做到这一点,我们计算 MINVAL# 和 MAXVAL 的 gradX (线72),然后由我们的缩放方程上显示 线73(即,最小/最大归一化)。最后一步是将gradX转换 为 uint8 ,其范围为[0-255]gradx=cv2.Sobel(tophat,ddepth=cv2.CV_32F,dx=1,dy=0,ksize=-1)gradx=np.absolute(gradx)(minval,maxval)=(np.min(gradx),np.max(gradx))gradx=(255*((gradx-minval)/(maxval-minval)))gradx=gradx.astype("uint8")#执行gradX 图像的Otsu和二进制阈值,然后是另一个关闭操作,对数字分段gradx=cv2.morphologyEx(gradx,cv2.MORPH_CLOSE,rectKernel)thresh=cv2.threshold(gradx,0,255,cv2.THRESH_BINARY|cv2.THRESH_OTSU)[1]thresh=cv2.morphologyEx(thresh,cv2.MORPH_CLOSE,sqKernel)#找到轮廓并初始化数字分组位置列表cnts=cv2.findContours(thresh,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)cnts=imutils.grab_contours(cnts)3、切割字符:
接着循环遍历轮廓,同时根据每个的宽高比进行过滤,允许我们从信用卡的其他不相关区域修剪数字组位置,然后从左到右对分组进行排序,并初始化信用卡数字列表。
部分代码如下:
locs = []#循环遍历轮廓,同时根据每个的宽高比进行过滤,允许我们从信用卡的其他不相关区域修剪数字组位置for (i, c) in enumerate(cnts): # compute the bounding box of the contour, then use the # bounding box coordinates to derive the aspect ratio (x, y, w, h) = cv2.boundingRect(c) ar = w / float(h) # since credit cards used a fixed size fonts with 4 groups # of 4 digits, we can prune potential contours based on the # aspect ratio if ar > 2.5 and ar < 4.0: # contours can further be pruned on minimum/maximum width # and height if (w > 40 and w < 55) and (h > 10 and h < 20): # append the bounding box region of the digits group # to our locations list locs.append((x, y, w, h))#从左到右对分组进行排序,并初始化信用卡数字列表locs = sorted(locs, key=lambda x:x[0])output = []#遍历四个排序的分组并确定其中的数字,循环的第一个块中,我们在每一侧提取并填充组5个像素(第125行)# ,应用阈值处理(第126和127行),并查找和排序轮廓(第129-135行)。for (i, (gX, gY, gW, gH)) in enumerate(locs): # initialize the list of group digits groupOutput = [] # extract the group ROI of 4 digits from the grayscale image, # then apply thresholding to segment the digits from the # background of the credit card group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5] group = cv2.threshold(group, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] # detect the contours of each individual digit in the group, # then sort the digit contours from left to right digitCnts = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) digitCnts = imutils.grab_contours(digitCnts) digitCnts = contours.sort_contours(digitCnts, method="left-to-right")[0] # loop over the digit contours for c in digitCnts: # compute the bounding box of the individual digit, extract # the digit, and resize it to have the same fixed size as # the reference OCR-A images (x, y, w, h) = cv2.boundingRect(c) roi = group[y:y + h, x:x + w] roi = cv2.resize(roi, (57, 88)) # initialize a list of template matching scores scores = [] # loop over the reference digit name and digit ROI for (digit, digitROI) in digits.items(): # apply correlation-based template matching, take the # score, and update the scores list result = cv2.matchTemplate(roi, digitROI, cv2.TM_CCOEFF) (_, score, _, _) = cv2.minMaxLoc(result) scores.append(score) # the classification for the digit ROI will be the reference # digit name with the *largest* template matching score groupOutput.append(str(np.argmax(scores))) # draw the digit classifications around the group cv2.rectangle(image, (gX - 5, gY - 5), (gX + gW + 5, gY + gH + 5), (0, 0, 255), 2) cv2.putText(image, "".join(groupOutput), (gX, gY - 15), cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2) # update the output digits list output.extend(groupOutput)# display the output credit card information to the screenprint("Credit Card Type: {}".format(FIRST_NUMBER[output[0]]))print("Credit Card #: {}".format("".join(output)))cv2.imshow("Image", image)cv2.waitKey(0)到这里,我们整体的程序就搭建完成,下面为我们程序的运行结果:
源码地址:
https://pan.baidu.com/s/16t7ZK4j1F6yzp2ynVQol0w
提取码:k5ra

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)