
目标跟踪DiMP: Learning Discriminative Model Prediction for Tracking
DiMP: Learning Discriminative Model Prediction for TrackingResultsVOT2018LaSOTTrackingNet(test)GOT10k(test)Nfs/OTB/UAV123ArchitectureOffiline trainingOnline tracking论文:DIMP: Learning Discriminative Mo
DiMP: Learning Discriminative Model Prediction for Tracking
论文:DIMP: Learning Discriminative Model Prediction for Tracking
代码:https://github.com/visionml/pytracking
Results
先来看一下马丁的ICCV2019 Oral DIMP的结果:
| DIMP-18 | 57 FPS | GTX-1080 |
|---|---|---|
| DIMP-50 | 43 FPS | GTX-1080 |
VOT2018

LaSOT

TrackingNet(test)

GOT10k(test)

Nfs/OTB/UAV123

相比ATOM多了一个在GOT10k test上的结果,看来马丁还是很中意这几个评测数据集的。
Architecture
dimp主要强调了自己是一个具有端到端学习,并且可以在线更新的架构,因此并不像siamese系列只是计算一下模板和搜索区域的相关性,那样只利用了目标的外观信息,并没有利用背景信息。由此作者设计了一个discriminative learning的架构,经过几次的迭代就能预测一个有效的target model(因为tracking就是需要一种target-specific的信息)。这部分就类似ATOM里面的classification的部分,都是为了更好的区分target和distractor,如下图所示,而回归部分还是利用ATOM里面的IoU predictor,关于ATOM可看我上篇博客。

那到底怎么快速预测一个包含有效前后背景信息的target model的呢?根据两个准则,作者设计了target classification branch:
- A discriminative learning loss promoting robustness in the learned target model
- a powerful optimization strategy ensuring rapid convergence

- 这里与之前很多tracker训练的不同,这里送入训练的是图片集对 ( M t r a i n , M t e s t ) (M_{train},M_{test}) (Mtrain,Mtest),而 M = ( I j , b j ) j = 1 N f r a m e s M={(I_{j},b_{j})}_{j=1}^{N_{frames}} M=(Ij,bj)j=1Nframes又是 N f r a m e s N_{frames} Nframes张图片和bbox构成的,喂给由backbone和cls feat组成的Feature Extractor F F F提取特征,得到 ( S t r a i n , S t e s t ) (S_{train},S_{test}) (Strain,Stest),,包含有 S = ( x j , c j ) j = 1 n S={(x_{j},c_{j})}_{j=1}^{n} S=(xj,cj)j=1n深度特征 x j x_{j} xj和目标中心坐标 c j ∈ R 2 c_{j} \in \mathbb{R}^2 cj∈R2
- 我们可以看到下一步就是绿框Model Predictor D,其实就是学习一个比较有判别力的filter/weight,去和 S t e s t S_{test} Stest进行卷积相关,得到一个Score Prediction,因为 S t e s t S_{test} Stest模拟了未见过的帧,然后之后得到损失并更新也是用的Score Prediction。
Offiline training
先看一下总体的训练过程,重点关注一下需要优化的参数:
# Create network and actor
net = dimpnet.dimpnet50(filter_size=settings.target_filter_sz, backbone_pretrained=True, optim_iter=5,
clf_feat_norm=True, clf_feat_blocks=0, final_conv=True, out_feature_dim=512,
optim_init_step=0.9, optim_init_reg=0.1,
init_gauss_sigma=output_sigma * settings.feature_sz, num_dist_bins=100,
bin_displacement=0.1, mask_init_factor=3.0, target_mask_act='sigmoid', score_act='relu')
# Wrap the network for multi GPU training
if settings.multi_gpu:
net = MultiGPU(net, dim=1)
objective = {'iou': nn.MSELoss(), 'test_clf': ltr_losses.LBHinge(threshold=settings.hinge_threshold)}
loss_weight = {'iou': 1, 'test_clf': 100, 'test_init_clf': 100, 'test_iter_clf': 400}
actor = actors.DiMPActor(net=net, objective=objective, loss_weight=loss_weight)
# Optimizer
optimizer = optim.Adam([{'params': actor.net.classifier.filter_initializer.parameters(), 'lr': 5e-5},
{'params': actor.net.classifier.filter_optimizer.parameters(), 'lr': 5e-4},
{'params': actor.net.classifier.feature_extractor.parameters(), 'lr': 5e-5},
{'params': actor.net.bb_regressor.parameters()},
{'params': actor.net.feature_extractor.parameters(), 'lr': 2e-5}],
lr=2e-4)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=15, gamma=0.2)
trainer = LTRTrainer(actor, [loader_train, loader_val], optimizer, settings, lr_scheduler)
trainer.train(50, load_latest=True, fail_safe=True)
下面就在这部分讲一讲最关键的Model Predictor D中的步骤。
总体的流程就是用Model Initializer初始化一个Initial Model
f
(
0
)
f^{(0)}
f(0),然后送入Model Optimizer来Update Model
f
(
i
)
f^{(i)}
f(i),经过
N
i
t
e
r
N_{iter}
Niter次迭代过后得到Final Model
f
f
f,在这几次内部迭代过程中,以
L
(
f
)
=
1
∣
S
train
∣
∑
(
x
,
c
)
∈
S
train
∥
r
(
x
∗
f
,
c
)
∥
2
+
∥
λ
f
∥
2
(1)
L(f)=\frac{1}{\left|S_{\text {train }}\right|} \sum_{(x, c) \in S_{\text {train }}}\|r(x * f, c)\|^{2}+\|\lambda f\|^{2} \tag{1}
L(f)=∣Strain ∣1(x,c)∈Strain ∑∥r(x∗f,c)∥2+∥λf∥2(1)
r
(
s
,
c
)
=
v
c
⋅
(
m
c
s
+
(
1
−
m
c
)
max
(
0
,
s
)
−
y
c
)
(2)
r(s, c)=v_{c} \cdot\left(m_{c} s+\left(1-m_{c}\right) \max (0, s)-y_{c}\right) \tag{2}
r(s,c)=vc⋅(mcs+(1−mc)max(0,s)−yc)(2)
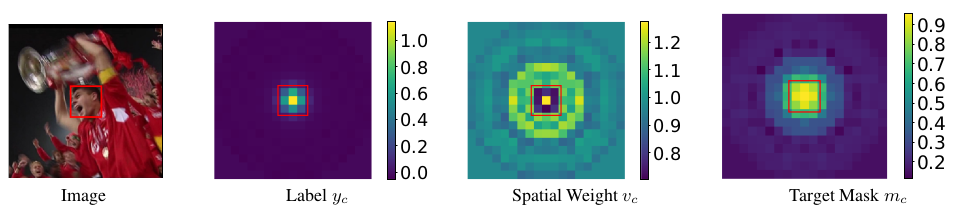
为损失函数来指导我们的优化过程,其中
m
c
m_{c}
mc是介于[0,1]之间的target_mask的一个map,
v
c
v_{c}
vc是起到空间不同位置赋予权重的spatial weight的一个map,
y
c
y_{c}
yc是目标的一个map,下面是他们的一个可视化图,最重要的一点就是他们都是可学习的【下面还要说,其实没什么,就是一层卷积层的输出;其实
m
c
s
+
(
1
−
m
c
)
max
(
0
,
s
)
m_{c} s+\left(1-m_{c}\right) \max (0, s)
mcs+(1−mc)max(0,s)用一个LeakyReLU函数就能实现】
因为普通的梯度下降法收敛慢,因为步长是固定的,所以选择每步都“走到底”的最速下降法(steepest descent),也就是变步长的:
f
(
i
+
1
)
=
f
(
i
)
−
α
∇
L
(
f
(
i
)
)
(3)
f^{(i+1)}=f^{(i)}-\alpha \nabla L\left(f^{(i)}\right) \tag{3}
f(i+1)=f(i)−α∇L(f(i))(3)损失函数可以用二次泰勒展开来拟合,但是这是高维函数,所以可以用下面的标准型来展开,其中
Q
(
i
)
Q^{(i)}
Q(i)是对称正定矩阵
L
(
f
)
≈
L
~
(
f
)
=
1
2
(
f
−
f
(
i
)
)
T
Q
(
i
)
(
f
−
f
(
i
)
)
+
(
f
−
f
(
i
)
)
T
∇
L
(
f
(
i
)
)
+
L
(
f
(
i
)
)
(4)
\begin{aligned} L(f) \approx \tilde{L}(f)=& \frac{1}{2}\left(f-f^{(i)}\right)^{\mathrm{T}} Q^{(i)}\left(f-f^{(i)}\right)+\\ &\left(f-f^{(i)}\right)^{\mathrm{T}} \nabla L\left(f^{(i)}\right)+L\left(f^{(i)}\right) \end{aligned} \tag{4}
L(f)≈L~(f)=21(f−f(i))TQ(i)(f−f(i))+(f−f(i))T∇L(f(i))+L(f(i))(4)在确定迭代方向为负梯度方向的前提上,需要确定在该方向上使得函数值最小的迭代步长
α
\alpha
α,这就是最速下降法和梯度下降法的区别所在,我们求导一下,可以得到:
α
=
∇
L
(
f
(
i
)
)
T
∇
L
(
f
(
i
)
)
∇
L
(
f
(
i
)
)
T
Q
(
i
)
∇
L
(
f
(
i
)
)
(5)
\alpha=\frac{\nabla L\left(f^{(i)}\right)^{\mathrm{T}} \nabla L\left(f^{(i)}\right)}{\nabla L\left(f^{(i)}\right)^{\mathrm{T}} Q^{(i)} \nabla L\left(f^{(i)}\right)} \tag{5}
α=∇L(f(i))TQ(i)∇L(f(i))∇L(f(i))T∇L(f(i))(5)因为最普通的
Q
(
i
)
Q^{(i)}
Q(i)就是二阶泰勒标准展开中的海森矩阵(Hessian matrix),但涉及二次导,所以实际编程时用一阶导代替:
Q
(
i
)
=
(
J
(
i
)
)
T
J
(
i
)
Q^{(i)}=\left(J^{(i)}\right)^{\mathrm{T}} J^{(i)}
Q(i)=(J(i))TJ(i)。
其实到这里也就可以进行Model Optimizer的优化过程了,但是如果要输出损失L的话还是得计算一下的,这里也涉及到具体
m
c
m_{c}
mc,
v
c
v_{c}
vc,
y
c
y_{c}
yc是怎么设计的:因为他们这些mask都是径向对称的,更重要的不是角度位置,而是与目标中心的distance大小,所以用下面这样的径向基函数去生成distance map
ρ
k
\rho_{k}
ρk,
N
=
100
N=100
N=100,
Δ
=
0.1
\Delta=0.1
Δ=0.1,你可以想象成一个100个channel的feature_sz×feature_sz大小的map
ρ
k
(
d
)
=
{
max
(
0
,
1
−
∣
d
−
k
Δ
∣
Δ
)
,
k
<
N
−
1
max
(
0
,
min
(
1
,
1
+
d
−
k
Δ
Δ
)
)
,
k
=
N
−
1
(6)
\rho_{k}(d)=\left\{\begin{array}{ll} \max \left(0,1-\frac{|d-k \Delta|}{\Delta}\right), & k<N-1 \\ \max \left(0, \min \left(1,1+\frac{d-k \Delta}{\Delta}\right)\right), & k=N-1 \end{array}\right. \tag{6}
ρk(d)={max(0,1−Δ∣d−kΔ∣),max(0,min(1,1+Δd−kΔ)),k<N−1k=N−1(6)然后用这些distance map去加权求和形成
m
c
m_{c}
mc,
v
c
v_{c}
vc,
y
c
y_{c}
yc。这里的
ϕ
k
\phi_{k}
ϕk其实就是nn.Conv2d(100, 1)的一层卷积层,可以学习就体现在这里。
y
c
(
t
)
=
∑
k
=
0
N
−
1
ϕ
k
y
ρ
k
(
∥
t
−
c
∥
)
(7)
y_{c}(t)=\sum_{k=0}^{N-1} \phi_{k}^{y} \rho_{k}(\|t-c\|) \tag{7}
yc(t)=k=0∑N−1ϕkyρk(∥t−c∥)(7)其实到这里才是Model Predictor D的结束,下面就是用最后一次优化生成的Final Model
f
f
f和
S
t
e
s
t
S_{test}
Stest卷积得到Score Prediction,也就是下面的
s
或
者
x
∗
f
(
i
)
s或者x * f^{(i)}
s或者x∗f(i)
ℓ
(
s
,
z
)
=
{
s
−
z
,
z
>
T
max
(
0
,
s
)
,
z
≤
T
(8)
\ell(s, z)=\left\{\begin{array}{ll} s-z, & z>T \\ \max (0, s), & z \leq T \end{array}\right. \tag{8}
ℓ(s,z)={s−z,max(0,s),z>Tz≤T(8)
z
c
z_{c}
zc是以目标中心撒的高斯标签,这里用label confidence value设定一个阈值
T
T
T,大于的认为是目标区域,小于的认为是背景区域,实现不同的损失,下面的分类损失
L
c
l
s
L_{\mathrm{cls}}
Lcls是在
S
t
e
s
t
S_{test}
Stest上的
L
c
l
s
=
1
N
iter
∑
i
=
0
N
iter
∑
(
x
,
c
)
∈
S
test
∥
ℓ
(
x
∗
f
(
i
)
,
z
c
)
∥
2
(9)
L_{\mathrm{cls}}=\frac{1}{N_{\text {iter }}} \sum_{i=0}^{N_{\text {iter }}} \sum_{(x, c) \in S_{\text {test }}}\left\|\ell\left(x * f^{(i)}, z_{c}\right)\right\|^{2} \tag{9}
Lcls=Niter 1i=0∑Niter (x,c)∈Stest ∑∥∥∥ℓ(x∗f(i),zc)∥∥∥2(9)然后加上target estimate,也就是IoU predictor分支的回归损失
L
b
b
L_{\mathrm{bb}}
Lbb 就是总损失了
L
t
o
t
=
β
L
c
l
s
+
L
b
b
L_{\mathrm{tot}}=\beta L_{\mathrm{cls}}+L_{\mathrm{bb}}
Ltot=βLcls+Lbb
归纳一下Target model predictor D部分的优化迭代过程就是这样的:

所以在整个的离线训练阶段,就相当于有两个loop,一个小loop就是用train set来优化Model Predictor D,大loop就是用test set来优化整个网络中需要优化的参数。
算法1在代码里面主要对应的就是pytracking/ltr/models/target_classifier/optimizer.py:
for i in range(num_iter):
if not backprop_through_learning or (i > 0 and i % self.detach_length == 0):
weights = weights.detach()
# Compute residuals
scores = filter_layer.apply_filter(feat, weights) # torch.Size([3, batch, 19, 19])
scores_act = self.score_activation(scores, target_mask) # latter is slope
score_mask = self.score_activation_deriv(scores, target_mask)
residuals = sample_weight * (scores_act - label_map) # Formula(2) in paper torch.Size([3, batch, 19, 19])
if compute_losses:
losses.append(((residuals**2).sum() + reg_weight * (weights**2).sum())/num_sequences)
# Compute gradient
residuals_mapped = score_mask * (sample_weight * residuals) # 这其实就是Loss传回到score的梯度 torch.Size([3, batch, 19, 19])
weights_grad = filter_layer.apply_feat_transpose(feat, residuals_mapped, filter_sz, training=self.training) + \
reg_weight * weights # [batch, 512, 4, 4]
# Map the gradient with the Jacobian
scores_grad = filter_layer.apply_filter(feat, weights_grad)
scores_grad = sample_weight * (score_mask * scores_grad)
# Compute optimal step length
alpha_num = (weights_grad * weights_grad).sum(dim=(1,2,3)) # [batch, 512, 4, 4] -> [batch,]
alpha_den = ((scores_grad * scores_grad).reshape(num_images, num_sequences, -1).sum(dim=(0,2)) + (reg_weight + self.alpha_eps) * alpha_num).clamp(1e-8)
alpha = alpha_num / alpha_den # numerator / denominator
# Update filter
weights = weights - (step_length_factor * alpha.reshape(-1, 1, 1, 1)) * weights_grad
# Add the weight iterate
weight_iterates.append(weights)
if compute_losses:
scores = filter_layer.apply_filter(feat, weights)
scores = self.score_activation(scores, target_mask)
losses.append((((sample_weight * (scores - label_map))**2).sum() + reg_weight * (weights**2).sum())/num_sequences)
return weights, weight_iterates, losses
Online tracking

代码里面关键的部分pytracking/pytracking/tracker/dimp/dimp.py:
- initialize:
# Extract and transform sample 15 samples
init_backbone_feat = self.generate_init_samples(im)
# Initialize classifier
self.init_classifier(init_backbone_feat)
在init_classifier函数中会进行10 steepest descent recursions
# Get target filter by running the discriminative model prediction module
# params.net_opt_iter = 10
with torch.no_grad():
self.target_filter, _, losses = self.net.classifier.get_filter(x, target_boxes, num_iter=num_iter,
compute_losses=plot_loss)
并且会初始化一个memory,如论文中所说:We ensure a maximum memory size of 50 by discarding the oldest sample
# Initialize memory params.sample_memory_size = 50
self.training_samples = TensorList(
[x.new_zeros(self.params.sample_memory_size, x.shape[1], x.shape[2], x.shape[3]) for x in train_x])
- track:
# Extract backbone features
backbone_feat, sample_coords, im_patches = self.extract_backbone_features(im, self.get_centered_sample_pos(),
self.target_scale * self.params.scale_factors,
self.img_sample_sz)
# Extract classification features
test_x = self.get_classification_features(backbone_feat)
# Location of sample
sample_pos, sample_scales = self.get_sample_location(sample_coords)
# Compute classification scores
scores_raw = self.classify_target(test_x)
# Localize the target
translation_vec, scale_ind, s, flag = self.localize_target(scores_raw, sample_pos, sample_scales)
new_pos = sample_pos[scale_ind,:] + translation_vec
# Update position and scale
if flag != 'not_found':
if self.params.get('use_iou_net', True):
update_scale_flag = self.params.get('update_scale_when_uncertain', True) or flag != 'uncertain'
if self.params.get('use_classifier', True):
self.update_state(new_pos)
# as ATOM, use IoU predictor
self.refine_target_box(backbone_feat, sample_pos[scale_ind,:], sample_scales[scale_ind], scale_ind, update_scale_flag)
elif self.params.get('use_classifier', True):
self.update_state(new_pos, sample_scales[scale_ind])
# ------- UPDATE ------- #
if update_flag and self.params.get('update_classifier', False):
# Get train sample
train_x = test_x[scale_ind:scale_ind+1, ...]
# Create target_box and label for spatial sample
target_box = self.get_iounet_box(self.pos, self.target_sz, sample_pos[scale_ind,:], sample_scales[scale_ind])
# Update the classifier model
self.update_classifier(train_x, target_box, learning_rate, s[scale_ind,...])
Bonus

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)