kubernetes集群内调度与负载均衡
kubernetes负载均衡包括集群外负载均衡和集群内负载均衡,专业术语叫南北流量和东西流量,本文主要讲述集群内负载均衡(东西流量)。本文第一部分会讲述kubernetes组件总览,第二部分会讲述kuber-scheduler是什么,第三部分会讲述kuber-scheduler核心概念,第四部分会讲述kuber-scheduler是如何实现负载均衡调度的,最后一部分会讲述kuber-schedul
kubernetes负载均衡包括集群外负载均衡和集群内负载均衡,专业术语叫南北流量和东西流量,本文主要讲述集群内负载均衡(东西流量)。本文第一部分会讲述kubernetes组件总览,第二部分会讲述kuber-scheduler是什么,第三部分会讲述kuber-scheduler核心概念,第四部分会讲述kuber-scheduler是如何实现负载均衡调度的,最后一部分会讲述kuber-scheduler的高可用选举机制,在讲到高可用和分部署集群leader选举时,会对知识点做适当迁移应用,引申一下。
一、Kubernetes组件总览
1、kubectl:命令行方式操作Kubernetes API Server
2、client-go:编程式客户端
3、kube-apiserver:暴露资源组/资源版本/资源
4、kube-controller-manager(高可用):管理节点(Node)、Pod副本、服务、端点(Endpoint)、命名空间(Namespace)、服务账户(ServiceAccount)、资源定额(ResourceQuota)等
5、kube-scheduler(高可用):监控Pod资源对象和Node资源对象,为一个Pod资源对象找到合适的节点并在该节点上运行。
6、kubelet:接收、处理、上报kube-apiserver组件下发的任务
7、kube-proxy:监控kube-apiserver的服务和端点资源变化,并通过iptables/ipvs等配置负载均衡器,为一组Pod提供统一的TCP/UDP流量转发和负载均衡功能。
二、什么是kube-scheduler
kube-scheduler用来监控Pod资源对象和Node资源对象,为一个Pod资源对象找到合适的节点并在该节点上运行。在整个系统中承担了“承上启下”的重要功能,“承上”是指它负责接收Controller Manager创建的新Pod,为其安排一个落脚的“家”——目标Node;“启下”是指安置工作完成后,目标Node上的kubelet服务进程接管后继工作,负责Pod生命周期中的“下半生”。
三、kube-scheduler核心概念
1、优先级与抢占机制
Pod资源对象实现了两种机制,包括优先级(Priority)与抢占(Preempt)机制。通过Pod资源对象的优先级可控制kube-scheduler的调度决策,被驱逐走的低优先级的Pod资源对象会重新进入调度队列并等待再次选择合适的节点Node。在生产环境中,可以对不同业务进行分级,重要业务可拥有高优先级策略,以提升重要业务的可用性。
抢占机制的抢占算法函数的运行流程如下:
(1)、判断当前Pod资源对象是否有资格抢占其他Pod资源对象所在的节点。
(2)、从预选调度失败的节点中尝试找到能够调度成功的节点列表(潜在的节点列表)。
(3)、从潜在的节点列表中尝试找到能够抢占成功的节点列表(驱逐的节点列表)。
(4)、从驱逐的节点列表中选择一个节点用于最终被抢占的节点(被抢占节点)。
(5)、获取被抢占节点上的所有NominatedPods列表。
需要注意的是,当集群面对资源短缺的压力时,高优先级的Pod将依赖于调度程序抢占低优先级的Pod的方式进行调度,这样可以优先保证高优先级的业务运行,因此建议不要禁用抢占机制。
kube-scheduler优先级与抢占机制的场景示例如下图所示,在SchedulingQueue调度队列中拥有高优先级(HighPriority)、中优先级(MidPriority)、低优先级(LowPriority)3个Pod资源对象。
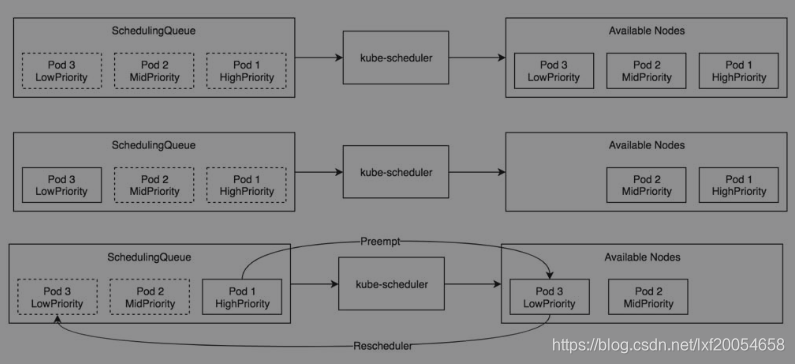
场景1:kube-scheduler调度器将待调度Pod资源对象按照优先级顺序调度到可用节点上。
场景2:当调度Pod 3资源对象时,可用节点没有可用资源运行Pod 3。此时,Pod 3在调度队列中处于待调度状态。
场景3:可用节点上已经调度了Pod 2与Pod 3资源对象,当调度Pod 1时,可用节点上已经没有资源运行Pod 1了,此时高优先级的Pod 1将抢占低优先级的Pod 3,而被抢占后的Pod 3重新进入调度队列等待再次选择合适的节点。
2、亲和性与反亲和性
(1)、NodeAffinity节点亲和性支持两种调度策略:
(a)没有满足条件的节点时,资源对象创建失败并不断重试。该策略也被称为硬(Hard)策略。
(b)没有满足条件的节点时,从其他节点中选择较优的节点。该策略也被称为软(Soft)模式。
(2)、PodAffinity资源对象亲和性支持两种调度策略:
(a)没有满足条件的节点时,资源对象创建失败并不断重试。该策略也被称为硬(Hard)策略。
(b)没有满足条件的节点时,从其他节点中选择较优的节点。该策略也被称为软(Soft)模式。
(3)、PodAntiAffinity(Pod资源对象反亲和性)支持两种调度策略:
(a)没有满足条件的节点时,资源对象创建失败并不断重试。该策略也被称为硬(Hard)策略。
(b)没有满足条件的节点时,从其他节点中选择较优的节点。该策略也被称为软(Soft)模式。
下面讲述亲和性和反亲和性的使用场景。
1、节点亲和性适用场景:
(1)调度到指定机房。
(2)调度到具有GPU硬件资源的节点上。
(3)调度到I/O密集型的节点上。
2、Pod对象资源亲和性适用场景:
(1)调度到同一主机。
(2)调度到同一硬件集群。
(3)调度到同一机房。
其目的就是缩短网络传输延时,增加性能。
3、Pod资源对象反亲和性适用场景:
避免有同一标签的Pod资源调度到同一个节点。一般用于容灾,实现高可用。
这种负载均衡方式本质是7层负载均衡。
需要注意的是,因为亲和性和反亲和性需要大量逻辑处理,在超过百个节点的集群,不要使用亲和性和反亲和性调度。
3、bind绑定机制
bind(绑定)操作是将通过调度算法计算出来的最佳节点与Pod资源对象进行绑定,该过程是异步操作,无须等待bind操作完成即可进入下一轮的调度周期。
此操作之后,运行Pod资源对象的工作交给绑定节点上的kubelet组件,实现启下的承接。
四、kube-scheduler是怎样实现抢占式调度的
1、默认所有Pod的优先级都为0,设置优先级的方式是在yaml文件里,kind设置为 PriorityClass,value的值越高,优先级越高。
yaml示例如下:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 100000
globalDefault: false
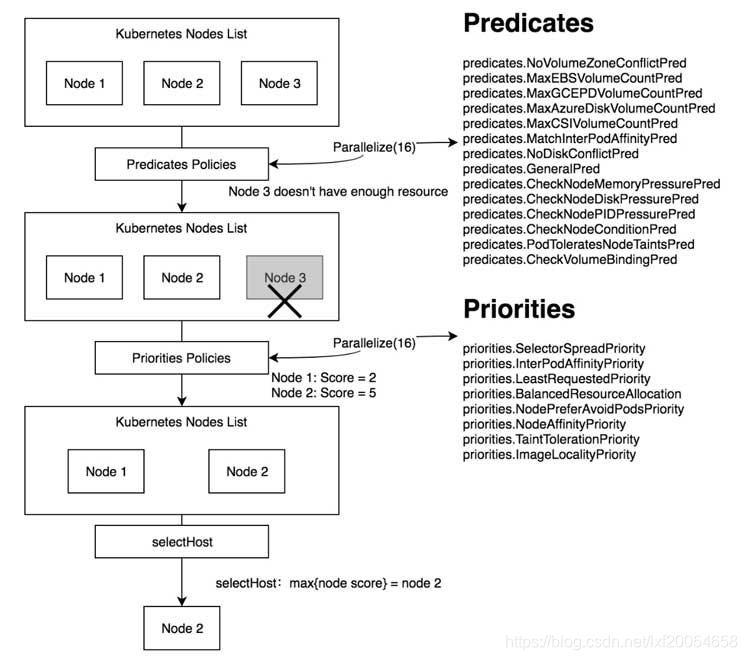
description: "This priority class should be used for hello service pods only."2、组件架构设计
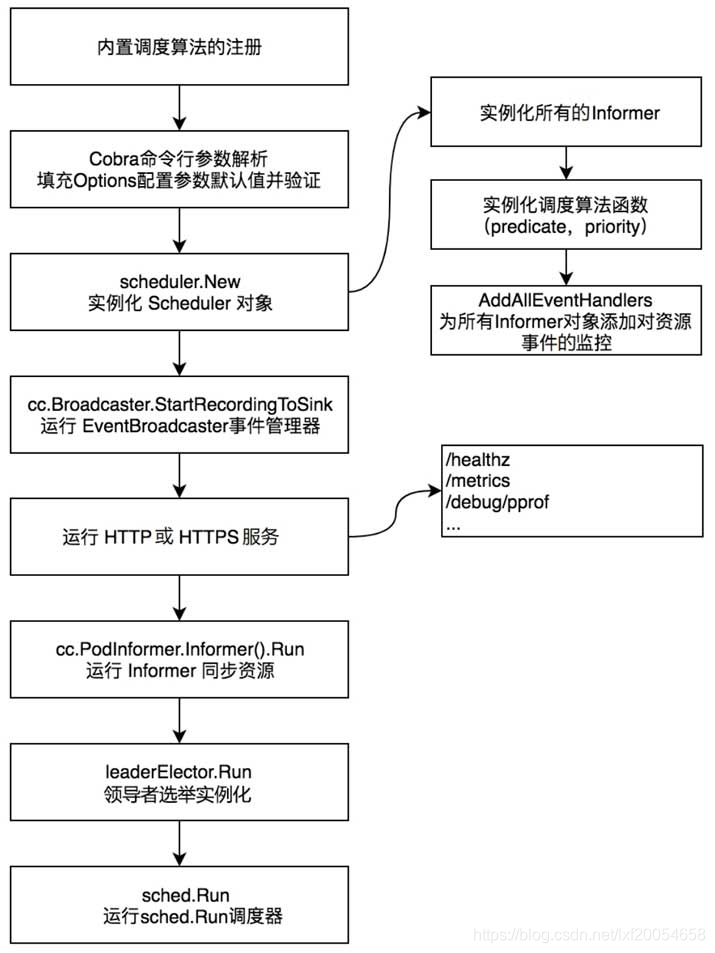
3、组件启动流程
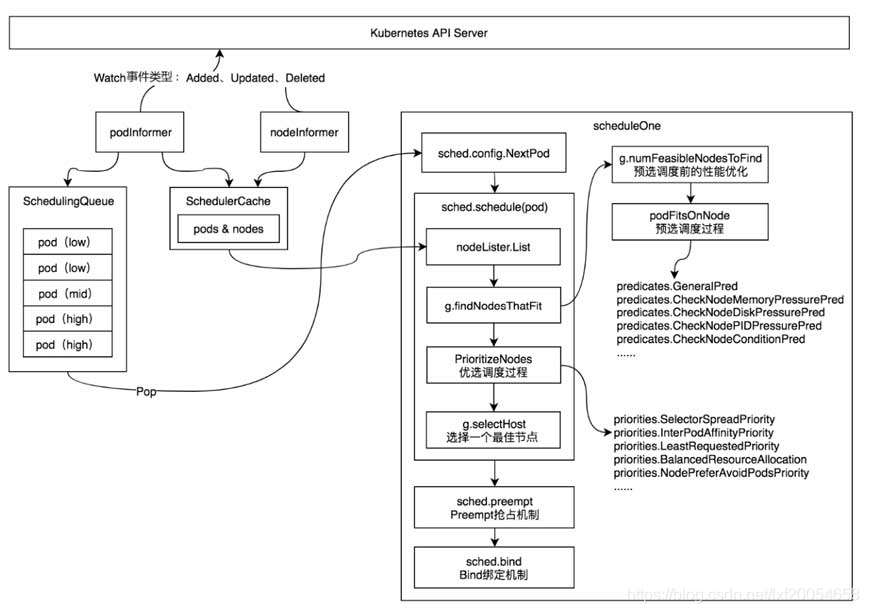
4、组件调度流程
五、kuber-scheduler的高可用选举机制
分布式集群的高可用,都离不开选举。
常见分布式选举场景包括:
(1)主从,如MySQL,Redis,kafka,Zookeeper。
(2)对等,如Eureka。
常见选举算法原理包括:
(1)欺负算法(最大的进程id算法总是获胜)。
(2)环算法。
常见的选举算法包括:
(1)最简单的选举算法:选举因子包括IP地址、CPU核数、内存大小、自定义序列号等等。不考虑选举过程中的异常。
(2)拜占庭将军问题:实则是一个协议问题。
(3)Paxos算法.
(4)Raft分布式选举算法。
(5)Zookeeper,ZooKeeper Atomic Broadcast(ZAB,ZooKeeper原子消息广播协议)。
在Kubernetes集群中,允许同时运行多个kube-scheduler节点,其中正常工作的只有一个kube-scheduler节点(即领导者节点),其他kube-scheduler节点为候选(Candidate)节点并处于阻塞状态。使用的选举算法为:创建锁标识-简单选举算法。
kube-scheduler组件在Etcd上实现分布式锁的原理如下。
(1)分布式锁依赖于Etcd上的一个key,key的操作都是原子操作。将key作为分布式锁,它有两种状态——存在和不存在。
(2)key(分布式锁)不存在时:多节点中的一个节点成功创建该key(获得锁)并写入自身节点的信息,获得锁的节点被称为领导者节点。领导者节点会定时更新(续约)该key的信息。
(3)key(分布式锁)存在时:其他节点处于阻塞状态并定时获取锁,这些节点被称为候选节点。候选节点定时获取锁的过程如下:定时获取key的数据,验证数据中领导者租约是否到期,如果未到期则不能抢占它,如果已到期则更新key并写入自身节点的信息,更新成功则成为领导者节点。
附录参考:
1、《Kubernetes源码剖析》,郑东旭
2、《Kubernetes进阶实战》,马永亮
3、《Kubernetes权威指南:从Docker到Kubernetes实践全接触(第4版)》,龚正等
4、分布式选举算法

开源、云原生的融合云平台
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)