ACL2020论文阅读笔记:BART
背景题目:BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension机构:Facebook AI作者:Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelr
背景
题目:
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
机构:Facebook AI
作者:Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer
论文地址:https://arxiv.org/abs/1910.13461
收录会议:ACL 2020
代码:https://github.com/pytorch/fairseq/tree/master/examples/bart
摘要
文章提出一个预训练sequence-to-sequence的去噪自编码器:BART。BART的训练主要由2个步骤组成:(1)使用任意噪声函数破坏文本(2)模型学习重建原始文本。BART 使用基于 Transformer 的标准神经机器翻译架构,可视为BERT(双向编码器)、GPT(从左至右的解码器)等近期出现的预训练模型的的泛化。文中评估了多种噪声方法,最终发现通过随机打乱原始句子的顺序,再使用首创的新型文本填充方法(即用单个 mask token 替换文本片段,换句话说不管是被mask掉多少个token,都只用一个特定的mask token表示该位置有token被遮蔽了)能够获取最优性能。BART 尤其擅长处理文本生成任务,不过在自然语言理解任务中也颇有可圈可点之处。在同等训练资源下,BART 在 GLUE 和 SQuAD 数据集上的效果与 RoBERTa 不相伯仲,并在对话摘要、问答和文本摘要等任务中斩获得新的记录,在 XSum 数据集上的性能比之前的最佳结果高出了6个ROUGE。在机器翻译任务中,BART 在仅使用目标语言预训练的情况下,获得了比回译系统高出 1.1 个 BLEU 值的结果。此外,文章还使用控制变量在BART 框架内使用其他预训练机制,从而更好地评估影响下游任务性能的因素。
模型
BART结合双向(比如BERT)和自回归(比如GPT) Transformer对模型进行预训练。此外,BART参考了GPT中的激活函数,将ReLU也改为GeLU。BART、BERT和GPT之间的对比如 Figure 1所示。

(a)BERT:用掩码替换随机 token,双向编码文档。由于缺失 token 被单独预测,因此 BERT 较难用于生成任务。(b)GPT:使用自回归方式预测 token,这意味着GPT可用于生成任务。 但是,该模型仅基于左侧上下文预测单词,无法学习双向交互。
©BART:编码器输入与解码器输出无需对齐,即允许任意噪声变换。使用掩码符号替换文本段,从而破坏文本。使用双向模型编码被破坏的文本(左),然后使用自回归解码器计算原始文档的似然(右)。至于微调,未被破坏的文档是编码器和解码器的输入,研究者使用来自解码器最终隐藏状态的表征。
BART的base版中的encoder和decoder都是6层网络,large则分别12层。BART与BERT还有2点不同(1)decoder中的每一层都与encoder最后隐藏层执行交叉关注(cross-attention,就像在transformer序列到序列模型中一样)。(2)BERT在预测token之前接一个前馈网络,而BART没有。总的来说,BART比同等大小的BERT模型多了大约10%的参数。
BART的一个关键优势是噪声的随意性,可以动用任何方式(包括改变长度)对原始文本进行破坏。这种方式让模型学习更多地考虑句子的整体长度,并对输入进行更大范围的转换,从而将BERT中MLM和NSP目标统一起来。此外,BART也为微调开创了一个新思路。BART做机器翻译的时候,将BART堆叠在一些额外的Transformer层之上,这些附加的Transformer层实质上是把其他语种翻译成带噪的英语,再通过BART模型,从而将BART作为一个预训练好的目标端语言模型。这种方法在WMT Romanian-English数据集上高出回译系统1.1个BLEU。
预训练
BART的损失函数是decoder的输出与原始文本之间的交叉熵。与其他去噪自编码器(一般需要定制特定的噪声方案)不同的是BART可以使用任何的加噪方式。在极端情况下,源信息都可以全部缺失,此时的BART就蜕化成了一个语言模型。文章中用到的加噪方案(即原始文本如何被破坏)如Figure 2所示。

Figure 2:对输入进行噪声化的变换方法。这些变换方法可以组合使用。
主要有:
(1)Token Masking:与 BERT 一样,BART 随机采样 token,并用 [MASK] 这一预定义的特殊token进行替换。
(2)Token Deletion:从输入中随机删除 token。与 Token Masking不同,模型必须同时确定输入中缺失的位置。
(3)Text Infilling:采样多个文本片段,每个文本片段长度服从λ = 3的泊松分布。每个文本片段用单个[MASK] token替换。从泊松分布中采样出长度为 0 的文本片段对应 插入 [MASK] token。这种文本填充方法的思想源于SpanBERT,但SpanBERT采样的文本片段长度服从的是几何分布,且用等长的[MASK] token 序列替换掉文本片段。因此,BART能够迫使模型学习到一个片段中所缺失的token数量。
(4)Sentence Permutation:这里的句子排列变换是指按句号将文档分割成多个句子,然后随机打乱这些句子。
(5)Document Rotation:随机均匀地选择 一个token,再旋转文档使文档以该 token 作为起始。该任务的目的是训练模型识别文档开头。
Fine-tuning
BART在文本分类和翻译任务中的微调如Figure 3所示。以下具体介绍 BART 在各个下游任务的微调。

Figure 3:a:当使用 BART 解决分类问题,用相同的输入文本输入到encoder和decoder,使用最终输出的表征。b:对于机器翻译任务,训练一个额外的小型encoder来替换 BART 中的词嵌入。新encoder可使用不同的词汇。
序列分类任务:
同一个输入同时输入到encoder 和decoder,将最后decoder的token的最终隐层状态被输入到一个新的多类别线性分类器中。该方法与 BERT 中的 CLS token 类似,不过 BART 在decoder最后额外添加了一个 token,如此该 token 在decoder中的表征可以关注到完整输入的decoder状态(见Figure 3a)。
token 分类任务:
token的分类任务,比如SQuAD中答案端点的分类。将完整文档输入到encoder和decoder中,使用decoder最上方的隐状态作为每个token的表征以判断该 token 的类别,比如是否为答案端部。
序列生成任务:
由于 BART 具备自回归解码器,因此可以直接应用到序列生成任务(如生成式问答和文本摘要)进行微调。在这两项任务中,从输入复制经过处理的信息,这与去噪预训练目标紧密相关。encoder的输入是输入序列,decoder以自回归的方式生成输出。
机器翻译:
BART用以机器翻译的时候,将整个BART(包括encoder和decoder)作为一个单独的预训练decoder,并增加一系列的从双语语料学习而得的encoder,如 Figure 3b所示。具体是用一个新的随机初始化encoder替换 BART encoder的嵌入层。该模型以端到端的方式训练,即训练一个新的encoder将外来词映射到输入(BART可将其去噪为英文)。这个新的encoder可以使用不同于原始 BART 模型的词汇。
源encoder的训练分两步,均需要将BART模型输出的交叉熵损失进行反向传播。
(1)冻结 BART 的大部分参数,仅更新随机初始化的源encoder、BART 位置嵌入和 BART encoder第一层的自注意力输入投影矩阵。
(2)将所有模型参数进行少量迭代训练。
实验
预训练目标对比
文章中还充分对比了不同预训练目标的影响,包括:
(1)语言模型:与GPT类似,训练一个从左到右的Transformer语言模型。该模型相当于BART的decoder,只是没有交叉注意(cross-attention)。
(2)排列语言模型:该模型基于XLNet,采样1/6的token,并以自回归的随机顺序生成。为了与其他模型保持一致,这里没有引入相对位置编码和XLNet中的片段级的循环注意力机制。
(3)带遮蔽的语言模型:与BERT相同,15%的token用 [MASK] token替换,训练模型重建出这些被遮蔽掉的token。
(4)多任务遮蔽的语言模型:与 UniLM 一样,使用额外self-attention mask训练带遮蔽的语言模型。自注意力遮蔽按如下比例随机选择:1/6从左到右;1/6从右到左;1/3未遮蔽;剩余的1/3中前50%的未遮蔽,其余的从左到右遮蔽。
(5)带遮蔽的seq-to-seq:与MASS模型类似,遮蔽一个片段中50%的token,并训练一个序列到序列模型预测被遮蔽的tokens。
实验过程对比了两种方案:
(1)将所有任务视为sequence-to-sequence问题,source端输入到encoder,decoder端的输出即为target结果。
(2)在decoder端将source作为target的一个前缀,且只在序列的target部分有损失函数。
实验发现前者对BART模型更有效,后者对其他模型更有效。更加详细的实验结果如 Table 1所示。

Table 1:预训练目标对比。各个预训练目标源于BERT, MASS, GPT, XLNet和UniLM。对比的模型都是尺寸近似,训练步数都是1M,预训练使用的数据也相同。
从中可以看出使用文本填充方案(Text Infilling)的BART战绩斐然。从中可以得出以下结论:
(1)在不同的任务中,预训练方法的表现有显著差异。换句话说,预训练方法的有效性高度依赖于任务本身。比如,一个简单的语言模型在ELI5数据集上可以夺冠,但是在SQUAD上的结果却是最差的。
(2)遮蔽Token至关重要。只使用旋转文档或句子组合的预训练目标则效果较差,效果较好的都是使用了token的删除或遮蔽作为预训练目标。此外,在生成任务上,删除token似乎比遮蔽token更胜一筹。
(3)从左到右的预训练目标有助于文本生成任务。遮蔽语言模型和排列语言模型在文本生成任务上不如其他模型。而这两种模型在预训练阶段都没有用到从左到右的自回归语言模型。
(4)对于SQuAD而言双向的encoder至关重要。因为上下文在分类决策中至关重要,BART仅用双向层数的一半就能达到BERT类似的性能。
(5)预训练目标并不是唯一重要的因素。这里的排列语言模型略逊于XLNet,其中一些差异可能是由于没有使用XLNet架构中的其他的改进,如相对位置编码和片段级的循环机制。
(6)纯语言模型在ELI5数据集上技压群雄,其困惑度远优于其他模型。这表明当输出仅受到输入的松散约束时,BART较为低效。
总而言之,使用文本填充预训练目标的BAR在多项任务上(除了ELI5之外)效果都很好。
Large版模型对比
自然语言理解任务
由于更大模型和更大batch size有助于下游任务性能的提升,所以文章还进一步对比各模型的large版。Large版的BART,encoder和decoder分别有12层,隐层大小为1024,batch size与RoBERTa一样都是8000,模型预训练了500000个step。tokenized方法借用 GPT-2 中的字节对编码(BPE)。各个模型在GLUE上的实验对比结果如 Table 2所示。

Table 2:Large版模型在 SQuAD 和 GLUE 上的实验结果。BART 的效果可比肩 RoBERTa 和 XLNet,这表明 BART 的单向decoder层并不会降低模型在判别任务上的性能。
各个模型在SQuAD上的对比结果如Table 3所示。

Table 3:BART的结果与XLNet和RoBERTa不相伯仲。
总体而言,BART在自然语言理解任务上与其他先进模型不相上下。这表明BART在生成任务上的进一步突破并不是以牺牲自然语言理解性能为代价。
自然语言生成任务
在文本生成任务中选用了摘要生成(CNN/DailyMail 和XSum)、对话(CONVAI2)和生成式问答(ELI5,是一个长篇问答数据集)中对应的数据集进行评测,结果如 Table 4所示。

Table 4:在两个标准摘要数据集上的结果。
从结果可以看出,在这两个摘要任务上,BART 在所有度量指标上均优于之前的模型。BART在更抽象的 XSum 数据集上的比之前最优的RoBERTa高出3.5个点(所有的ROUGE指标)。此外,从人工评测的角度来看,BART也大幅优于之前的模型。但是,与人类的摘要结果仍然有差距。
各模型在CONVAI2上的实验结果如Table 5所示。

Table 5:BART 在对话生成任务上的性能优于之前的研究。其中困惑度基于 ConvAI2 官方 tokenizer 进行了重新归一化。
在ELI5数据集上的评测结果如Table 6所示。

Table 6:BART在具有挑战性的ELI5生产式问答数据集上达到了最先进的结果。
发现BART的性能比之前最好的工作(指Seq2Seq Multi-task)高出1.2个 ROUGE-L。因为该数据集中的问题只对答案进行了微弱的指定,从而提升了该数据集的难度。
leader board结果如下:

机器翻译任务
BART在WMT16 Romanian-English上与其他模型的对比结果如Table 7所示。
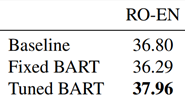
Table 7:BART 和基线模型(Transformer)在机器翻译任务上的性能对比情况。
参与对比的模型使用数据集包括 WMT16 RO-EN 和用回译系统做的扩增数据。可以看出BART使用单语英文预训练,性能结果优于基线模型。
总结
文本介绍了一种预训练模型:BART。该模型是一个预训练sequence-to-sequence的去噪自编码器。BART不同于一些只能针对特定的噪声的去噪自编码器,可以使用任意方式破坏原始文本,最极端的情况下,源文本信息全部丧失,此时BART蜕变为一个语言模型。BART模型中的文本填充方法让模型学习更多地考虑句子的整体长度,并对输入进行更大范围的转换,从而将BERT中MLM和NSP目标统一起来,加大了模型学习难度。BART在自然语言理解任务上与先进模型不相伯仲,但是在文本生成任务上可以碾压其他模型,一枝独秀。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)