强化学习论文笔记:Real-Time Reinforcement Learning
Real-time Reinforcement Learning简介NeurIPS 2019上蒙特利尔大学的工作在连续时间的决策任务中,环境在动作选择时是实时变化的。作者定义了实时马尔可夫决策过程(RTMDP)并提出强化学习算法Real-Time Actor-Critic(RTAC),相比于传统方法能够更好地学习实时环境下的最优策略问题存在动作选择延迟的连续时间马尔可夫环境下的实时决策问题方法智能
Real-time Reinforcement Learning
简介
NeurIPS 2019上蒙特利尔大学的工作
在连续时间的决策任务中,环境在动作选择时是实时变化的。作者定义了实时马尔可夫决策过程(RTMDP)并提出强化学习算法Real-Time Actor-Critic(RTAC),相比于传统方法能够更好地学习实时环境下的最优策略
问题
存在动作选择延迟的连续时间马尔可夫环境下的实时决策问题
方法
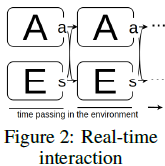
智能体与环境的两种交互方式
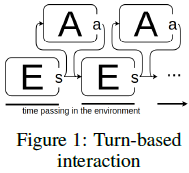
回合交互:串行,决策时环境静止,如:围棋
实时交互:并行,决策时环境实时变化,如:自动驾驶、无人机
通常把实时交互任务近似为回合交互,再应用强化学习。很多对安全性要求苛刻的场景无法容忍近似带来的误差,也有些场景近似的误差过大。需要针对实时交互的学习算法。
RTMDP
强化学习的基本假设是环境是MDP的:
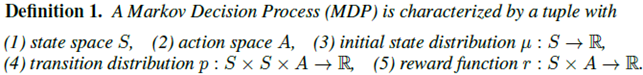
智能体与环境交互的过程是MRP的(环境的状态转移*智能体的策略=交互过程的状态转移)
根据交互方式的不同,定义回合MRP和实时MRP:
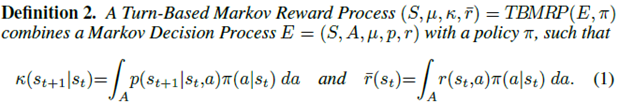
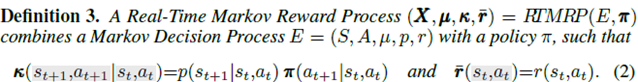
强化学习算法都是基于回合交互的,并不能用于实时交互。
定义Real-time MDP来表示实时环境:

RTMDP本质上就是1步延迟的MDP。根据定义1-4,可证在RTMDP环境下使用回合交互等价于在MDP环境下进行实时交互:

于是我们能够通过将环境表示为RTMDP后直接使用现有的强化学习方法进行学习。
根据MDP的价值函数的定义

![]()
可以得到RTMDP的价值函数
![]()
RTAC
实时环境多为控制任务。随机策略往往在控制任务中表现出较好的性能和鲁棒性。文中提出的RTAC算法以Soft-Actor-Critic(SAC)为基础。SAC的主要特点包括:1.最大熵策略,保证策略的随机性 2.AC框架,同时学习价值函数和策略 3.off-policy,提高样本利用率。SAC的目标函数如下
![]()
(关于SAC算法可以查看我的另一篇文章:强化学习论文笔记:Soft Actor Crtitic算法
由于RTMDP的价值函数V的参数包括动作a,故采用(8)作为学习的目标,因此可以得到RTAC的目标函数
![]()
(9)和(10)具有相同的梯度
![]()
价值函数的目标函数用MSE表示
![]()
其中
![]()
由于策略和价值函数的输入都是t时刻的状态和动作,可以将使用一个NN近似策略和价值函数,目标函数为
![]()
实验
实验环境(benchmark)为Mujoco和Avenue,后者是一个开源自动驾驶模拟环境


SAC作为Baseline,Metrics是平均累计回报。
实验结果如下



总结
通过将智能体与MDP环境的实时交互转化为与RTMDP环境的回合交互,巧妙地解决了实时环境的决策问题。应该是最早把动作选择时间带来的延迟考虑到的工作。实验比较充分,用了低维的环境Mujoco和高维的Avenue。Avenue是基于Unity的无人驾驶模拟环境,可以借鉴作为我们的验证平台。作者是蒙特利尔大学的博士生,截止到2020年7月还没有发表进一步的工作。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)