
Kettle与Hadoop(三)连接Hadoop
目录一、环境说明二、连接Hadoop集群三、连接Hive四、连接Impala五、后续(建立MySQL数据库连接)Kettle可以与Hadoop协同工作。让我们从简单的开始,本文介绍如何配置Kettle访问Hadoop集群(HDFS、MapReduce、Zookeeper、Oozie等),以及Hive、Impala等数据库组件。所有操作都以操作系统的root用户执行。一、环境说明1. Hadoop已
目录
Kettle可以与Hadoop协同工作。让我们从简单的开始,本文介绍如何配置Kettle访问Hadoop集群(HDFS、MapReduce、Zookeeper、Oozie等),以及Hive、Impala等数据库组件。所有操作都以操作系统的root用户执行。
一、环境说明
1. Hadoop
已经安装好4个节点的CDH 6.3.1,IP地址及主机名如下:
172.16.1.124 manager
172.16.1.125 node1
172.16.1.126 node2
172.16.1.127 node3
启动的Hadoop服务如图1所示,所有服务都使用缺省端口。
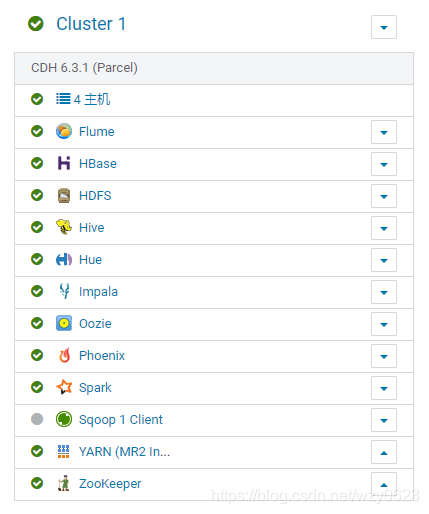
2. Kettle
已经在172.16.1.105安装好PDI 8.3,安装目录为/root/data-integration。为了用主机名访问Hadoop相关服务,在Kettle主机的/etc/hosts文件中添加了如下内容:
172.16.1.124 manager
172.16.1.125 node1
172.16.1.126 node2
172.16.1.127 node3二、连接Hadoop集群
1. 在Kettle中配置Hadoop客户端文件
(1)在浏览器中登录Cloudera Manager,选择hive服务,点击“操作”->“下载客户端配置”。得到如图2的文件。
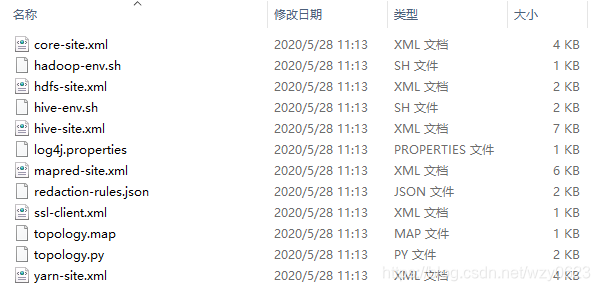
(2)将上一步得到的Hadoop客户端配置文件复制到Kettle的~/data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations/cdh61/目录下,覆盖原来自带的core-site.xml、hdfs-site.xml、hive-site.xml、yarn-site.xml、mapred-site.xml 5个文件。
2. 启动spoon
/root/data-integration/spoon.sh3. 在spoon中选择Hadoop种类
选择主菜单“Tools” -> “Hadoop Distribution...”,在对话框中选择“Cloudera CDH 6.1.0”,如图3所示。
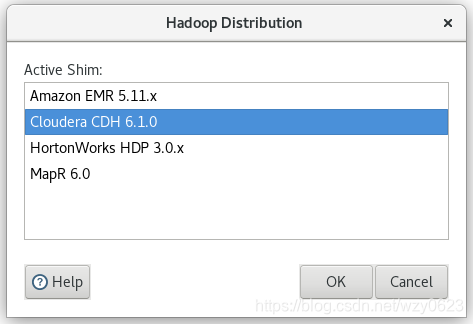
4. 重启spoon
5. 在Spoon创建Hadoop clusters对象
(1)新建转换
主菜单 File -> New -> Transformation
(2)新建Hadoop集群对象
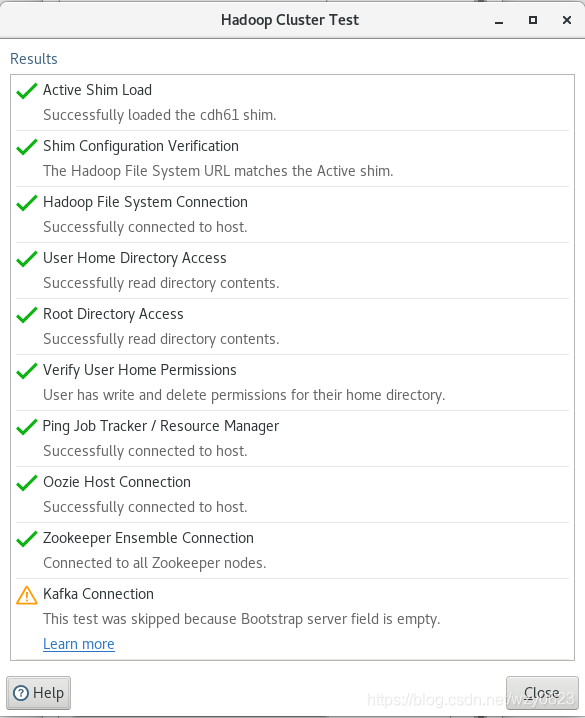
在工作区左侧的树的View标签中,选择 Hadoop clusters -> 右键New Cluster,对话框中输入如图4所示的属性值。然后点击“Test”按钮,结果如图5所示。除了Kafka因没有在CDH中启动服务导致连接失败以外,其它均通过测试。最后点击“OK”保存Hadoop集群对象。
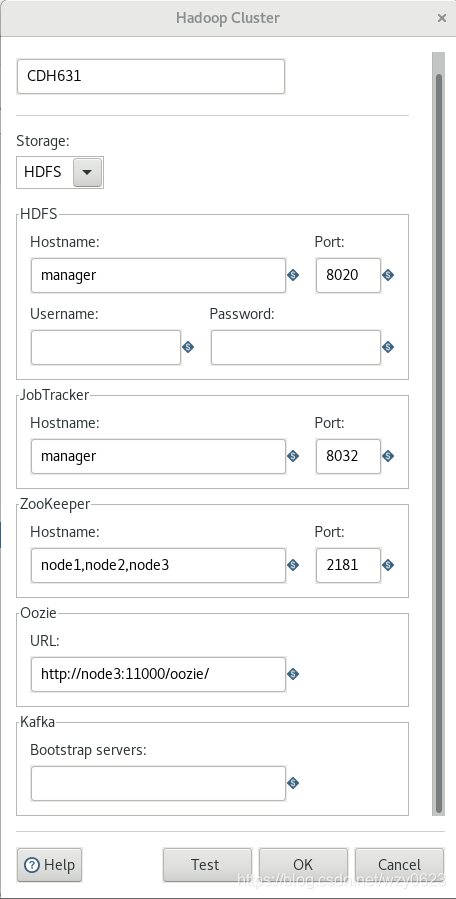
三、连接Hive
1. 新建数据库连接对象
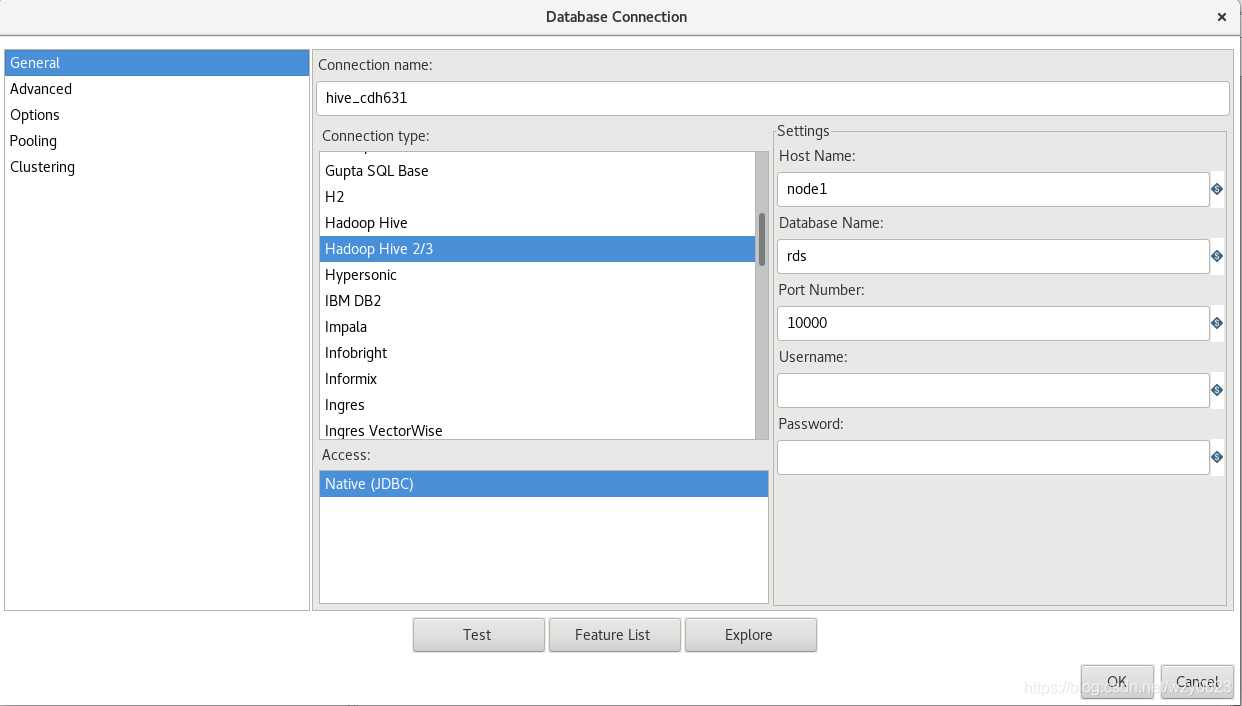
在工作区左侧的树的View标签中,选择 Database Connections -> 右键New,对话框中输入如图6所示的属性值。
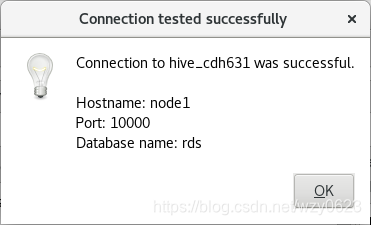
点击“Test”按钮,连接Hive成功如图7所示。
然后点击“OK”保存数据库连接对象。
2. 共享数据库连接对象
为其它转换或作业能够使用数据库连接对象,需要将它设置为共享。选择 Database Connections -> hive_cdh631 -> 右键Share,然后保存转换。
四、连接Impala
1. 新建数据库连接对象
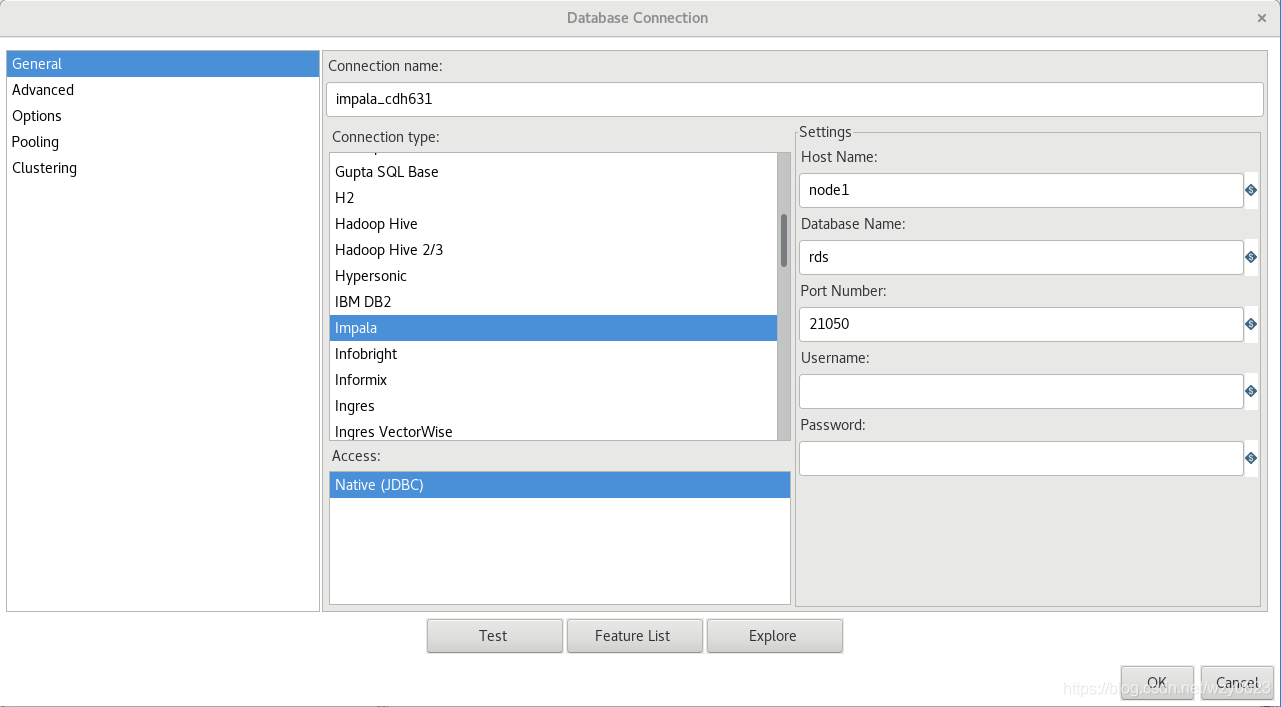
在工作区左侧的树的View标签中,选择 Database Connections -> 右键New,对话框中输入如图8所示的属性值。
点击“Test”按钮,连接Impala成功如图9所示。
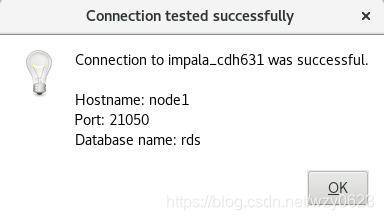
然后点击“OK”保存数据库连接对象。
2. 共享数据库连接对象
为其它转换或作业能够使用数据库连接对象,需要将它设置为共享。选择 Database Connections -> impala_cdh631 -> 右键Share,然后保存转换。
五、后续(建立MySQL数据库连接)
为了给后面创建的转换或作业使用,我们再定义一个普通的mysql数据库连接对象。
1. 拷贝MySQL驱动jar文件
这里使用的是MySQL 5.6.14版本,需要将相应的驱动程序文件拷贝到Kettle安装目录的lib目录下。
cp mysql-connector-java-5.1.38-bin.jar /root/data-integration/lib之后重启Spoon加载新增的驱动程序。
2. 新建数据库连接对象
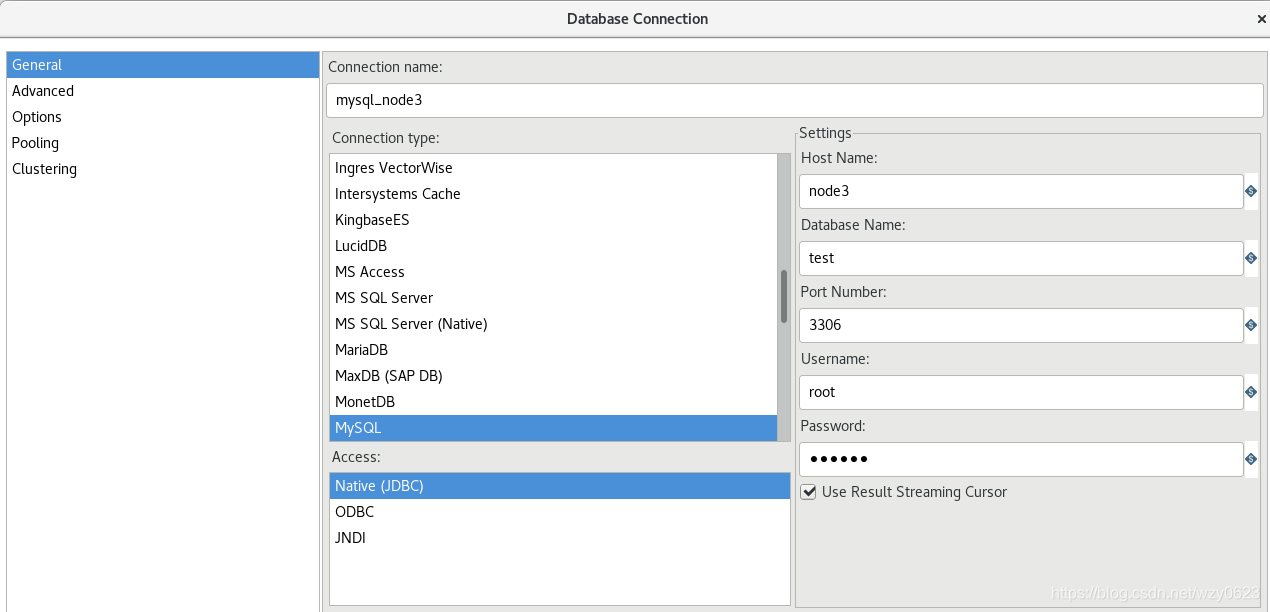
在工作区左侧的树的View标签中,选择 Database Connections -> 右键New,对话框中输入如图10所示的属性值。
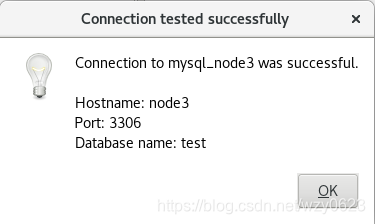
点击“Test”按钮,连接MySQL成功如图11所示。
然后点击“OK”保存数据库连接对象。
3. 共享数据库连接对象
为其它转换或作业能够使用数据库连接对象,需要将它设置为共享。选择 Database Connections -> mysql_node3 -> 右键Share,然后保存转换。
至此已经创建了一个Hadoop集群对象和三个数据库连接对象,如图12所示。
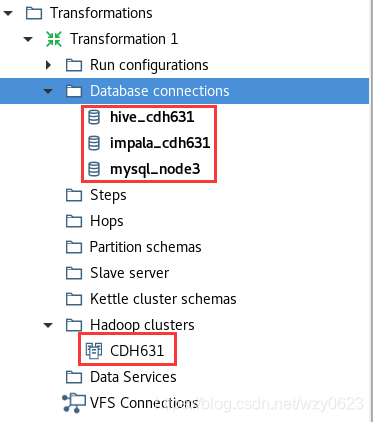
后面将在这些对象上进行一系列Kettle读写Hadoop组件的实验。
参考:Use Hadoop with Pentaho

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)