
回归评价指标(MSE、RMSE、MAE、R-Squared、拟合优度)
文章目录拟合优度拟合优度拟合优度(Goodness of Fit)是指回归直线对观测值的拟合程度。度量拟合优度的统计量是可决系数(Coefficient of Determination)R²。可决系数,亦称测定系数、确定系数、决定系数、可决指数。对于m个样本(x1→,y1),(x2→,y2),⋯ ,(xm→,ym)(\overrightarrow{x_{1}},y_{1}),(\overr...
文章目录
对于回归模型效果的判断指标经过了几个过程,从SSE到R-square再到Ajusted R-square, 是一个完善的过程。
拟合优度/R-Squared
拟合优度(Goodness of Fit)是指回归直线对观测值的拟合程度。度量拟合优度的统计量是可决系数(Coefficient of Determination)R²。可决系数,亦称测定系数、确定系数、决定系数、可决指数。
对于m个样本
(
x
1
→
,
y
1
)
,
(
x
2
→
,
y
2
)
,
⋯
,
(
x
m
→
,
y
m
)
(\overrightarrow{x_{1}},y_{1}),(\overrightarrow{x_{2}},y_{2}),\cdots ,(\overrightarrow{x_{m}},y_{m})
(x1,y1),(x2,y2),⋯,(xm,ym) ,
某模型的估计值为
(
x
1
→
,
y
^
1
)
,
(
x
2
→
,
y
^
2
)
,
⋯
,
(
x
m
→
,
y
^
m
)
(\overrightarrow{x_{1}},\widehat{y}_{1}),(\overrightarrow{x_{2}},\widehat{y}_{2}),\cdots ,(\overrightarrow{x_{m}},\widehat{y}_{m})
(x1,y
1),(x2,y
2),⋯,(xm,y
m)
计算样本的总平方和TSS(Total Sum of Squares):
T
S
S
=
∑
i
=
1
m
(
y
i
−
y
‾
)
2
TSS=\sum_{i=1}^{m}(y_{i}-\overline{y})^{2}
TSS=i=1∑m(yi−y)2
即样本伪方差的m倍
V
a
r
(
Y
)
=
T
S
S
/
m
Var(Y)=TSS/m
Var(Y)=TSS/m
计算残差平方和RSS(Residual Sum of Squares):
R
S
S
=
∑
i
=
1
m
(
y
i
^
−
y
i
)
2
RSS=\sum_{i=1}^{m}(\widehat{y_{i}}-y_{i})^{2}
RSS=i=1∑m(yi
−yi)2
注:RSS即误差平方和SSE(Sum of Squares Error)。
定义
R
2
=
1
−
R
S
S
/
T
S
S
R^{2}=1-RSS/TSS
R2=1−RSS/TSS
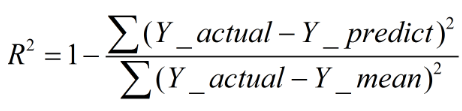
注: R 2 R^{2} R2越大,拟合效果越好。 R 2 R^{2} R2的最优值为1,若模型预测为随机值, R 2 R^{2} R2有可能为负值。若预测值恒为样本期望, R 2 R^{2} R2为0。理论上取值范围(-∞,1],正常取值范围为[0 1]。实际操作中通常会选择拟合较好的曲线计算R²,因此很少出现-∞。越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好。越接近0,表明模型拟合的越差。经验值:>0.4, 拟合效果好。
数学理解:如果只用分子当做评价指标,存在两个缺点:1、样本数据在100左右的数据集和样本在1000左右的数据集的评价指标没有可比性。2、对离散值的影响比较大。但是除上分母之后可以有效解决这两个缺点。分母理解为原始数据的离散程度,分子为预测数据和原始数据的误差,二者相除可以消除原始数据离散程度的影响。
缺点:数据集的样本越大,R²越大,因此,不同数据集的模型结果比较会有一定的误差。
校正决定系数(Adjusted R-square)
Adjusted R-square:Degree-of-freedom adjusted coefficient of determination。
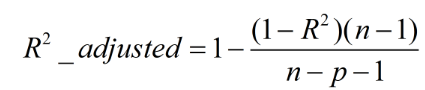
n为样本数量,p为特征数量
消除了样本数量和特征数量的影响。
均方误差(MSE)
MSE (Mean Squared Error)叫做均方误差,真实值-预测值 然后平方之后求和平均,衡量观测值与真实值之间的偏差。

均方根误差(RMSE)
RMSE(Root Mean Squard Error)均方根误差,RMSE其实是MSE开根号,两者实质一样,但RMSE能更好的描述数据。因为MSE单位量级和误差的量级不一样,而RMSE跟数据是一个级别的,级别一样更容易去感知数据。
缺点:易受异常值的影响。

误差平方和(SSE):The sum of squares due to error
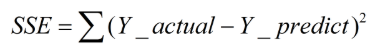
特点:同样的数据集的情况下,SSE越小,误差越小,模型效果越好。
缺点:SSE数值大小本身没有意义,随着样本增加,SSE必然增加,也就是说,不同的数据集的情况下,SSE比较没有意义。
平均绝对误差(MAE)
MAE(Mean Absolute Error)平均绝对误差

平均绝对百分比误差(MAPE)
平均绝对百分比误差(Mean Absolute Percentage Error),与RMSE相比,更加鲁棒,因为MAPE对每个点的误差进行了归一化。
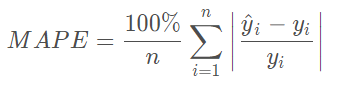
代码
scikit-learn中的各种衡量指标
from sklearn.metrics import mean_squared_error #均方误差
from sklearn.metrics import mean_absolute_error #平方绝对误差
from sklearn.metrics import r2_score#R square
#调用
mean_squared_error(y_test,y_predict)
mean_absolute_error(y_test,y_predict)
r2_score(y_test,y_predict)
手写各种衡量指标
# MSE
y_preditc=reg.predict(x_test) #reg是训练好的模型
mse_test=np.sum((y_preditc-y_test)**2)/len(y_test) #跟数学公式一样的
# RMSE
rmse_test=mse_test ** 0.5
# MAE
mae_test=np.sum(np.absolute(y_preditc-y_test))/len(y_test)
# R Squared
1- mean_squared_error(y_test,y_preditc)/ np.var(y_test)
参考:https://blog.csdn.net/guolindonggld/article/details/87856780

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 39
39 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)