
Python-GeoPandas地图、专题地图绘制
Python-GeoPandas地图绘制、专题地图绘制GeoPandas是一个开源项目,Pandas是Python的一个结构化数据分析的利器,GeoPandas扩展了pandas使用的数据类型,允许对几何类型进行空间操作,其DataFrame结构相当于GIS数据中的一张属性表,使得可以直接操作矢量数据属性表,其目标是使得在python中操作地理数据更方便。矢量数据来源可以参照我的另一篇...
一键AI生成摘要,助你高效阅读
问答
·
Python-GeoPandas地图绘制、专题地图绘制
GeoPandas是一个开源项目,Pandas是Python的一个结构化数据分析的利器,GeoPandas扩展了pandas使用的数据类型,允许对几何类型进行空间操作,其DataFrame结构相当于GIS数据中的一张属性表,使得可以直接操作矢量数据属性表,其目标是使得在python中操作地理数据更方便。
- 矢量数据来源
可以参照我的另一篇文章,将阿里云上GeoJSON的数据利用Python保存到本地磁盘上。
- 数据地址:
http://datav.aliyun.com/tools/atlas/#&lat=31.80289258670676&lng=104.2822265625&zoom=4
- 专题地图资料搜集
可以利用统计年鉴上的数据或是其他数据制成CSV或是Excel文件,通过矢量数据的一个公共字段来连接。例如我的数据(公共字段为 name):
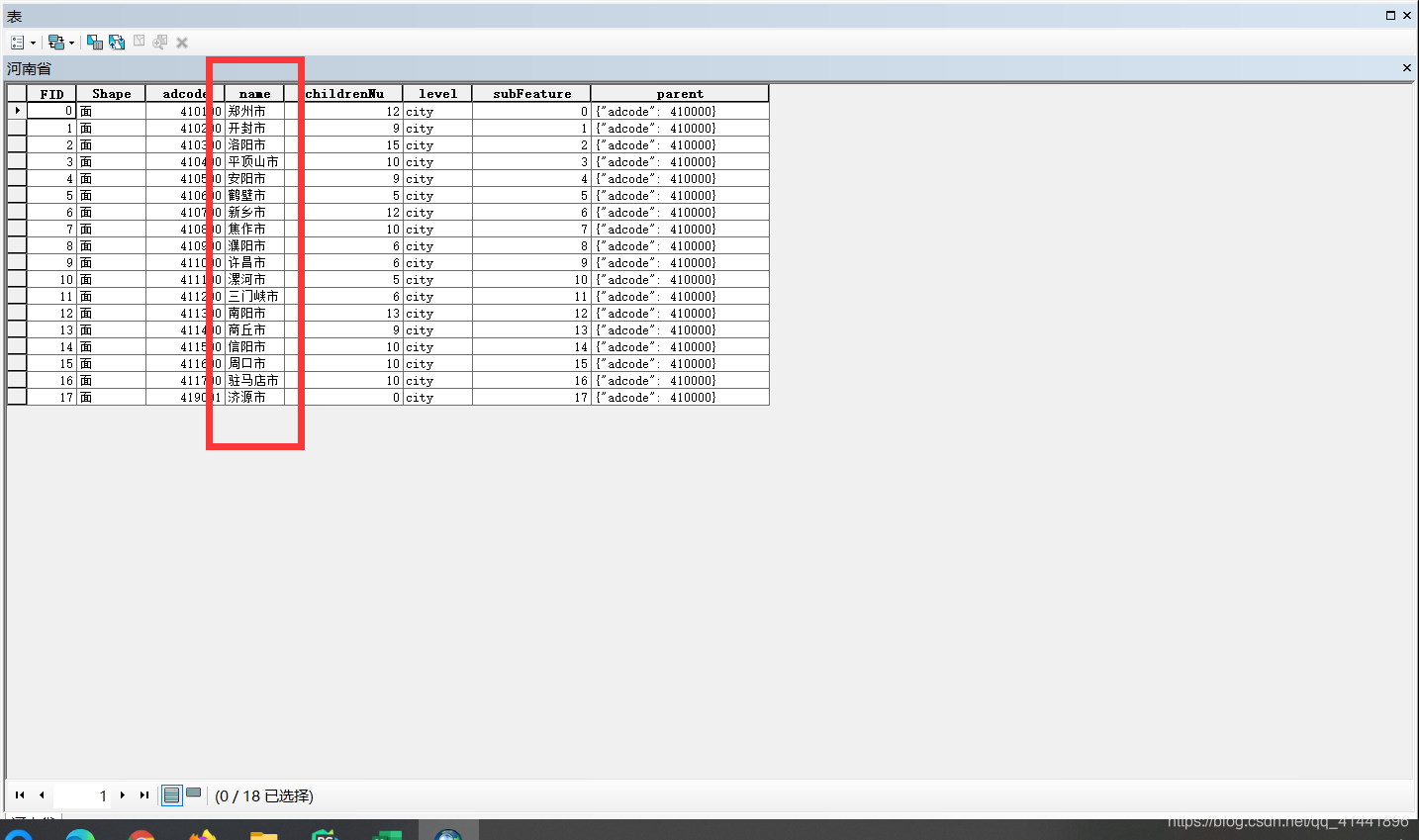
矢量数据属性表
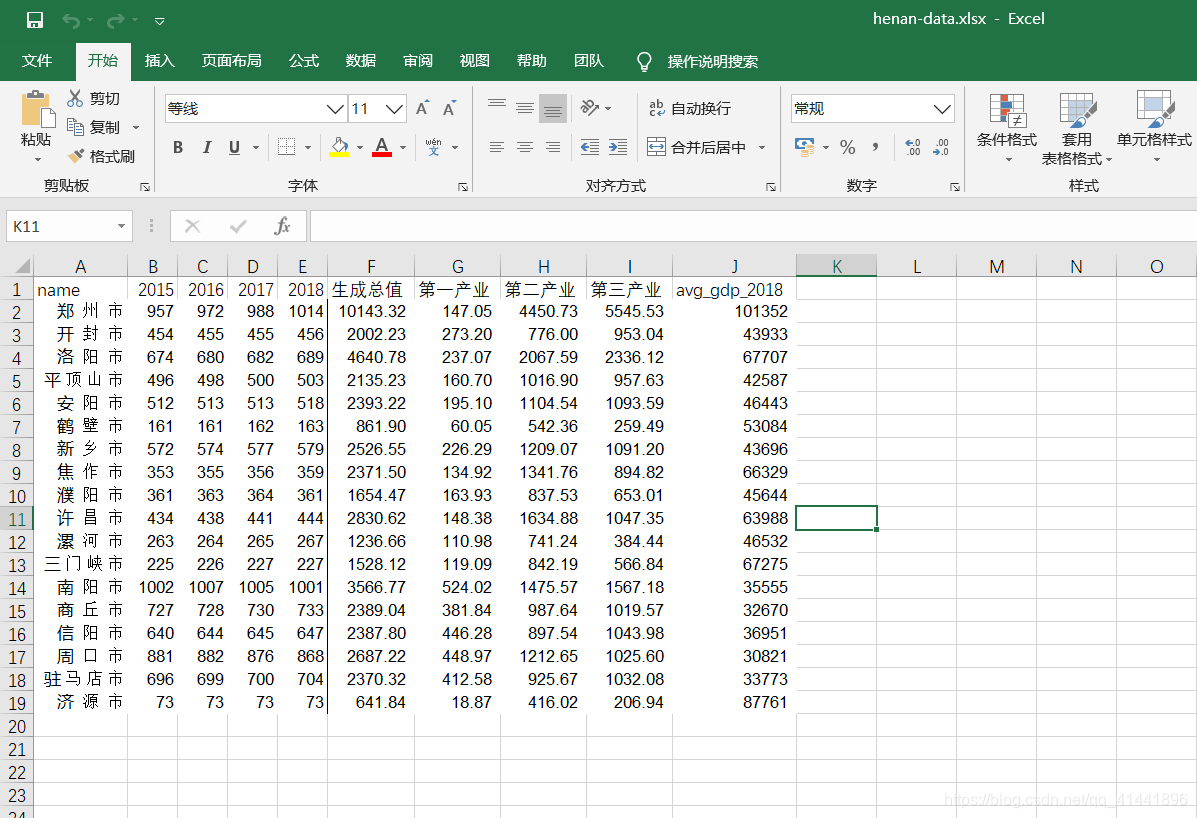
专题地图数据 来源:2019年河南省统计年鉴
3.1 地图绘制
- 效果预览


- 实现代码
# -*- coding: utf-8 -*-
"""
@File : provinceMapMake.py
@Author : fungis@163.com
@Time : 2020/04/20 16:49
@notice : 地图颜色(https://matplotlib.org/tutorials/colors/colormaps.html)
"""
import geopandas as gpd
import matplotlib.pyplot as plt
# 输入图名
Map_name = '河南省行政区划'
# 加载数据-矢量数据的位置
regions = gpd.GeoDataFrame.from_file('./shp/henanProvince/河南省.shp', encoding='utf-8')
# 加载数据-读取矢量数据的属性表
data = gpd.read_file('./shp/henanProvince/河南省.dbf', encoding='utf-8')
# 复制一份该表的数据
reg02 = data.copy()
# # 专题地图制图
reg02['coords'] = reg02['geometry'].apply(lambda x: x.representative_point().coords[0])
reg02.plot(figsize=(8, 6), # 图像大小
column='name', # 分级设色字段
# scheme='quantiles', # MapClassify-分级类型
legend=False, # 图例
cmap='Pastel1_r', # 渐变色带的名称#Set2
edgecolor='k') # 边框颜色
# 地图标注
for n, i in enumerate(reg02['coords']):
plt.text(i[0] - 0.2, i[1], reg02['name'][n], fontsize=8, horizontalalignment="left") # 标注位置X,Y,标注内容
plt.title('Python-{}图'.format(Map_name), fontsize=18, fontweight='bold')
plt.grid(True, alpha=0.5) # 显示网格,透明度为50%
# plt.show()
plt.savefig('./images/{}.png'.format(Map_name), dpi=300)
3.2专题分级设色图
- 效果预览

数据来源:2019年河南省统计年鉴
- 实现代码
# -*- coding: utf-8 -*-
"""
@File : 河南省2018年经济发展图.py
@Author : fungis@163.com
@Time : 2020/04/20 11:29
@notice : 参照https://www.cnblogs.com/feffery/p/12381322.html
"""
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
# 加载数据-矢量数据的位置
regions = gpd.GeoDataFrame.from_file('./shp/henanProvince/河南省.shp', encoding='utf-8')
# 加载已搜集的excel数据,如果是csv文件用pd.read_csv()方法
data = pd.read_excel('./data-use/henan-data.xlsx')
# 处理数据格式(Excel中的name字段中有空格,消除空格)
data['area_name'] = data['name'].str.replace(' ', '')
# 连接矢量数据属性表与Excel表格
reg = pd.merge(regions, data, left_on='name', right_on='area_name')
# 复制整张表
reg02 = reg.copy()
# # 专题地图制图
reg02['coords'] = reg02['geometry'].apply(lambda x: x.representative_point().coords[0])
reg02.plot(figsize=(8, 6), # 图像大小
column='avg_gdp_2018', # 分级设色字段
scheme='quantiles', # MapClassify-分级类型
legend=True, # 图例
legend_kwds={"loc": "lower left"},
cmap='Reds', # 渐变色带的名称
edgecolor='k') # 边框颜色
# 地图标注
for n, i in enumerate(reg02['coords']):
plt.text(i[0] - 0.13, i[1], reg02['area_name'][n]) # 标注位置X,Y,标注内容
plt.title('2018年河南省各地级市人均GDP(单位:元)')
plt.grid(True, alpha=0.5) # 显示网格,透明度为50%
# plt.show()
plt.savefig('./images/河南省2018年各地级市GDP.png', dpi=300)
- 效果预览

数据来源:2019年河南省统计年鉴
- 实现代码
# -*- coding: utf-8 -*-
"""
@File : 经济发展组合图.py
@Author : fungis@163.com
@Time : 2020/04/20 11:29
@notice :
"""
'''
地图颜色(https://matplotlib.org/tutorials/colors/colormaps.html)
cmaps['Sequential'] = [
'Greys', 'Purples', 'Blues', 'Greens', 'Oranges', 'Reds',
'YlOrBr', 'YlOrRd', 'OrRd', 'PuRd', 'RdPu', 'BuPu',
'GnBu', 'PuBu', 'YlGnBu', 'PuBuGn', 'BuGn', 'YlGn']
'''
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
# 加载数据-矢量数据的位置
regions = gpd.GeoDataFrame.from_file('./shp/henanProvince/河南省.shp', encoding='utf-8')
# 加载已搜集的excel数据,如果是csv文件用pd.read_csv()方法
data = pd.read_excel('./data-use/henan-data.xlsx')
# 处理数据格式
data['area_name'] = data['name'].str.replace(' ', '')
# 计算整合数据:人均产值= 产业产值/区域人均
data['data_one'] = data['第一产业'] / data[2018] * 10000
data['data_two'] = data['第二产业'] / data[2018] * 10000
data['data_three'] = data['第三产业'] / data[2018] * 10000
#表格链接-连接矢量数据属性表与Excel表格
reg = pd.merge(regions, data, left_on='name', right_on='area_name')
reg03 = reg.copy()
# 列表 第一个是分级设色的字段,第二个是图名
data_plot = [('avg_gdp_2018', '2018年河南省各市人均GDP(单位:元)'),
('data_one', '2018年河南省各市第一产业人均产值(单位:元)'),
('data_two', '2018年河南省各市第二产业人均产值(单位:元)'),
('data_three', '2018年河南省各市第三产业人均产值(单位:元)')]
#图纸大小设置
plt.figure(figsize=(16, 14))
for m, cal in enumerate(data_plot):
reg03['coords'] = reg03['geometry'].apply(lambda x: x.representative_point().coords[0])
reg03.plot(ax=plt.subplot(2, 2, m + 1),
column=cal[0], # 分级设色字段
scheme='Quantiles', # ['Equal_interval'|'Quantiles'|'Fisher_Jenks']
legend=True,#是否显示图例
legend_kwds={"loc": "lower left"},#图例的位置
cmap='Pastel1', # 色带的选择
edgecolor='k'
)
for n, i in enumerate(reg03['coords']):
plt.text(i[0] - 0.13, i[1], reg03['area_name'][n])
plt.title(cal[1])
plt.grid(True, alpha=0.5)
plt.savefig('./images/河南省2018年经济组合拼接图__Pastel1_Quantiles.png', dpi=300)
- 结尾
喜欢的朋友们可以点个关注,后续将持续更新,精彩无限^ - ^

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)