
基于BERT的超长文本分类模型
基于BERT的超长文本分类模型0.Abstract1.任务介绍数据集评估方法测试集0.Abstract本文实现了一个基于BERT+LSTM实现超长文本分类的模型, 评估方法使用准确率和F1 Score.项目代码github地址:1.任务介绍用BERT做文本分类是一个比较常见的项目.但是众所周知BERT对于文本输入长度有限制. 对于超长文本的处理, 最简单暴力无脑高效的办法是直接截断, ...
基于BERT的超长文本分类模型
0.Abstract
本文实现了一个基于BERT+LSTM超长文本分类的模型, 评估方法使用准确率和F1 Score.
项目代码github地址: https://github.com/neesetifa/bert_classification
1.任务介绍
用BERT做文本分类是一个比较常见的项目.
但是众所周知BERT对于文本输入长度有限制. 对于超长文本的处理, 最简单暴力无脑高效的办法是直接截断, 就取开头这部分送入BERT. 但是也请别看不起这种做法, 往往最简单,最Naive的方法效果反而比一顿操作猛如虎 复杂模型来得好.
这里多提一句为什么. 通常长文本的文章结构都比较明确, 文章前面一两段基本都是对于后面的概述. 所以等于作者已经帮你提取了文章大意, 所以直接取前面一部分理论上来说是有意义的.
当然也有最新研究表明取文章中间部分效果也很不错. 在此不展开.
本文实现的是一种基于HIERARCHICAL(级联)思想的做法, 把文本切成多片处理. 该方法来自于这篇论文 <Hierarchical Transformers for Long Document Classification>.
文中提到这么做还能降低self-attention计算的时间复杂度.
假设原句子长为n, 每个分段的长度是k. 我们知道最原始的BERT计算时间复杂度是O(n2), 作者认为,这么做可以把时间复杂度降低到O(nk). 因为我们把n分数据分割成k小份, 那么我们一共要做n/k次, 每次我们的时间复杂度是k2, 即O(n/k * k2) = O(nk)
数据集
这次我们测试该模型在两种语言上的效果. 分别是中文数据集和英语数据集.
中文数据集依旧是我们的老朋友ChineseNLPCorps提供的不同类别商品的评论.
中文数据集传送门
英语数据集来源于Kaggle比赛, 用户对于不同金融产品的评论.
英语数据集传送门
由于两种数据集训练预测上没有什么本质区别, 下文会用英语数据集来演示.
评估方法
本项目使用的评估方法是准确率和F1 Score. 非常常见的分类问题评价标准.
测试集
此项目中直接取了数据集里一小部分作为测试集.
2.数据初步处理
数据集里有55W条数据,18个features.
我们需要的部分是product(即商品类别)以及consumer complaint narrative.
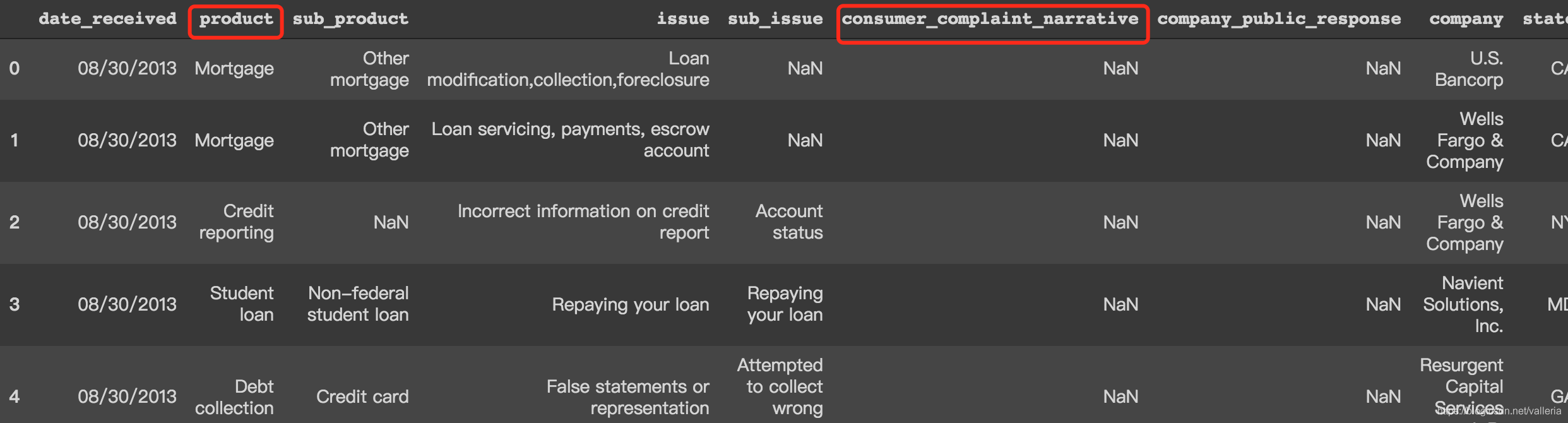
观察数据集,我们发现用户评论是有NaN值的. 而且本次实验目的是做超长文本分类. 我们选取非NaN值,并且是长度大于250的评论.

筛选完后我们保留大约17k条左右数据

3.Baseline模型
我们先来看一下什么都不做, 直接用BERT进行finetune能达到什么样的效果. 我们以此作为实验的baseline.
本次预训练模型使用google官方的BERT-base-cased英语预训练模型(当然用uncased应该也没关系, 我没有测试)
fine-tune部分很简单, 直接提取[CLS] token后过线性层, 是比较常规的套路. 损失函数使用cross entropy loss.
文本送入的最大长度定为250. 即前文里提到的"直接截取文本前面部分". 此次实验里我们尝试比较HIERARCHICAL方法能比直接截取提高多少.

如图, 准确率达到了88%. 训练数据不过10k的数量级, 对于深度学习来说是非常少的. 这里不得不感叹下BERT作为预训练模型在小样本数据上的实力非常强劲.
4. 数据进一步处理
接下来我们进入提高部分. 首先对数据进一步处理.
分割文本
HIERARCHICAL思想本质是对数据进行有重叠(overlap)的分割. 这样分割后的每句句子之间仍然保留了一定的关联信息.
众所周知,BERT输入的最大长度限制为512, 其中还需要包括[CLS]和[SEP]. 那么实际可用的长度仅为510. 但是别忘了, 每个单词tokenizer之后也有可能被分成好几部分. 所以实际可输入的句子长度远不足510.
本次实验里我们设置分割的长度为200, overlap长度为50. 如果实际上线生产确有大量超过500长度的文本, 只需将分割和overlap长度设置更长即可.
def get_split_text(text, split_len=250, overlap_len=50):
split_text=[]
for w in range(len(text)//split_len):
if w == 0: #第一次,直接分割长度放进去
text_piece = text[:split_len]
else: # 否则, 按照(分割长度-overlap)往后走
window = split_len - overlap_len
text_piece = [w * window: w * window + split_len]
split_text.append(text_piece)
return split_text
分割完后长这样

随后我们将这些分割的句子分离成单独的一条数据. 并为他们加上label.

对比原文本可以发现, index 1~ index4来源于同一句句子. 它被分割成了4份并且每份都拥有原文本的label.
4.最终模型
最终模型由两个部分构成, 第一部分是和baseline里一模一样的, fine-tune后的BERT. 第二部分是由LSTM+FC层组成的混合模型.
即实际上, BERT只是用来提取出句子的表示, 而真正在做分类的是LSTM + FC部分(更准确来说是FC部分, 因为LSTM模型部分仍然在做进一步的特征提取工作)
这里稍微提一句,这样做法我个人认为类似于广告推荐系统里GBDT+LR的组合. 采用一个稍微复杂的模型去做特征提取, 然后用一个相对简单的模型去预测.
第一部分: BERT
首先,我们把分割好后的文本送入BERT进行训练. 这边我跑了5个epoch, 显卡仍然是Tesla K80, 每个epoch大约需要23分钟左右.

接着, 我们提取出这些文本的句子表示.
方便起见, 我们这里仍然用[CLS] token作为句子表示. 当然也可以用sequence_output(在我上一个项目FAQ问答的最后结论中, 使用sequence_output的确能比pooled_output效果更好一点)
我们获得的是这样一组数据:
句子1_a的embedding, label
句子1_b的embedding, label
句子1_c的embedding, label
句子2_a的embedding, label
句子2_b的embedding, label
句子3_a的embedding, label
…
随后我们把这些embedding拼回起来, 变成了
[句子1_a的embedding,句子1_b的embedding, 句子1_c的embedding], label
[句子2_a的embedding, 句子2_b的embedding], label
[句子3_a的embedding, 句子3_b的embedding], label
这部分数据将作为LSTM部分的输入.
第二部分: LSTM + FC
这一步,我们将上一步得到的embedding直接送入LSTM网络训练.
回想一下, 我们平时用LSTM做, 是不是把句子过了embedding层之后再送入LSTM的? 这里我们直接跳过embedding层, 因为我们的数据本身就是embedding
由于分割后的embedding都不会太长, 我们直接使用LSTM最后一个time step的输出(当然这里也有个尝试点, 如果提取出LSTM每个time step的输出效果是不是会更好?)
LSTM之后会过一个激活函数, 接一个FC层, FC层和label用cross entropy loss进行优化.
由于合并后的数据量比较小, 我跑了10个epoch, 每次都很快.

最终效果和一些小节
(左边loss, 右边accuracy)

最终效果居然提高到了94%!! 说实话这个提升量远高于论文. 可能和数据本身好也有关系. 但是我们可以认为, 比起直接截取文本开头一段, 采用HIERARCHICAL方式不仅克服了BERT长度限制的缺点, 也极大提升了对于超长文本的分类效果.
下面是在中文数据集上模型的baseline效果和提升后的效果.
(待跑)
所以我认为, 采用HIERARCHICAL方法, 提升/解决了BERT两方面的缺点:
1.降低了BERT里self-attention部分计算的时间复杂度. 就如开头所说, 时间复杂度从O(n2)降低到O(nk). 这个情况尤其适用于长度在500以内长度的文本.
2.克服了BERT对于输入文本长度有限的缺点. 对于tokenize之后长度超过510的文本, 也可以用此方式对准确率进行再提升, 其实际效果优于直接截断文本.
5. 进一步拓展: BERT + Transformer
原论文里还提到了使用Transformer代替LSTM作为预测部分.
这一节我们用Transformer来试一下.
我们先来分析一下使用Transformer结构后的时间复杂度. 显然它的时间复杂度和LSTM不一样(LSTM复杂度我们可以认为是线性的, 即O(n/k)~O(n).)
首先在BERT部分, 时间复杂度不变, 依旧为为O(n/k * k2) = O(nk). 进入到Transformer后,每个sequence长度为n/k, 所以时间复杂度为O(n/k * n/k)=O(n2/k2).
那么总体时间复杂度为 O(nk) + O(n2/k2) ~ O(n2/k2).
相比于LSTM的O(nk), 这个O(n2/k2)复杂度是有相当的上升的. 但是我们考虑到 n/k << n, 即n/k的量级远小于n, 所以还是在可接受的范围.
(本小节未完…)

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)