NLP之统计语言模型—N元模型(N-Gram)
总的来说,语言模型可以分为两种,分别是规则模型和统计模型两种。统计语言模型是用概率统计的方法来揭示语言单位的内在统计规律,广泛应用于机器翻译、语音识别、印刷体和手写体识别、拼写纠错、汉字输入和文献查询。N-Gram假设:第n个词的出现只与前面的n-1个词相关,而与其他任何词都不相关,整句的概率是各个词出现概率的乘积。这种可以结合上下文方法其实就是马尔可夫假设,结合上下文信息,预测将要出现的那...
·
总的来说,语言模型可以分为两种,分别是规则模型和统计模型两种。统计语言模型是用概率统计的方法来揭示语言单位的内在统计规律,广泛应用于机器翻译、语音识别、印刷体和手写体识别、拼写纠错、汉字输入和文献查询。
N-Gram假设:第n个词的出现只与前面的n-1个词相关,而与其他任何词都不相关,整句的概率是各个词出现概率的乘积。这种可以结合上下文方法其实就是马尔可夫假设,结合上下文信息,预测将要出现的那个词,在某种程度上给出一个合理的预测。所以N-gram也可称为(N-1)阶马尔可夫模型。
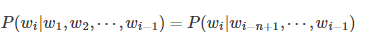
每个·w对应于语料中不重复的词,i为需要预测的句子长度,n就是选择的N元模型的N的大小。理论上来说,N的数量越大,得到的估计概率越准确,模型的效果就会越好。但N增加,对应的参数也会增加。
- 一元模型
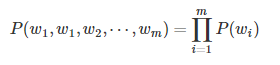
- 二元模型
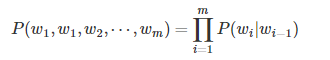
- 三元模型
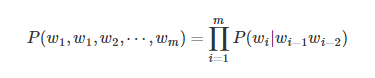
假如语料中包含20000个词,那么选择不同的N对应的参数数量如下表:
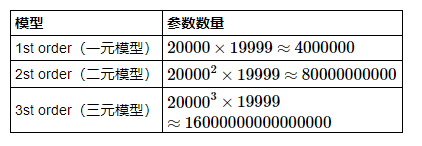
从上表可以看出,使用的N元数量和需要估计的参数数量是成指数关系增加的。
所以,经常使用的N元模型是二元、三元的。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)