
凸优化基础(Convex Optimization basics)
总目录
一、 凸优化基础(Convex Optimization basics)
二、 一阶梯度方法(First-order methods)
- 梯度下降(Gradient Descent)
- 次梯度(Subgradients)
- 近端梯度法(Proximal Gradient Descent)
- 随机梯度下降(Stochastic gradient descent)
三、对偶
- 线性规划中的对偶(Duality in linear programs)
- 凸优化中的对偶(Duality in General Programs)
- KKT条件(Karush-Kuhn-Tucker Conditions)
- 对偶的应用及拓展(Duality Uses and Correspondences)
- 对偶方法(Dual Methods)
- 交替方向乘子法(Alternating Direction Method of Multipliers)
Introduction
一个凸优化问题具有以下基本形式:
min x ∈ D f ( x ) s u b j e c t t o g i ( x ) ≤ 0 , i = 1 , . . . , m h j ( x ) = 0 , j = 1 , . . . , r \begin{aligned} \min_{x\in D} f(x)\qquad\qquad\qquad\\ subject\ to\qquad g_i(x)\leq 0,\ i=1,...,m \\ h_j(x)=0,\ j=1,...,r\\ \end{aligned} x∈Dminf(x)subject togi(x)≤0, i=1,...,mhj(x)=0, j=1,...,r
其中, f f f和 g i g_i gi都是凸函数的,且 h j h_j hj是仿射变换。凸优化问题有一个良好的性质,即对于一个凸优化问题来说,任何局部最小值都是全局最小值。凸优化问题是优化问题中被研究得比较成熟的,也是非凸优化的基础,许多非凸优化问题也被局部近似为凸优化问题求解。
凸集和凸函数
凸集
凸集的定义
一个集合 c ⊆ R n c \subseteq R^n c⊆Rn是凸集,如果对任意 x , y ∈ C x,y\in C x,y∈C都有
t x + ( 1 − t ) y ∈ C , f o r a l l 0 ≤ t ≤ 1 tx+(1-t)y\in C,\ for\ all\ 0\leq t\leq 1 tx+(1−t)y∈C, for all 0≤t≤1
许多常见的集合,如空集,点、线集合,仿射空间 { x : A x = b , f o r g i v e n A , b } \{x:Ax=b,\ for\ given\ A,b\} {x:Ax=b, for given A,b}都属于凸集。正因如此,对于凸集中的变量做仿射变换得到的仍然是凸集。
凸函数
凸函数的定义
如果函数 f : R n → R f:\ R^n\rightarrow R f: Rn→R是凸函数,那么函数的定义域 d o m ( f ) ⊆ R n dom(f)\subseteq R^n dom(f)⊆Rn是凸的,且对于所有 x , y ∈ d o m ( f ) x,y\in dom(f) x,y∈dom(f),都有
f ( t x + ( 1 − t ) y ) ≤ t f ( x ) + ( 1 − t ) f ( y ) , f o r 0 ≤ t ≤ 1 f(tx+(1-t)y)\leq tf(x)+(1-t)f(y),\ for\ 0\leq t\leq 1 f(tx+(1−t)y)≤tf(x)+(1−t)f(y), for 0≤t≤1
换句话说,函数永远不会高于 f ( x ) f(x) f(x)和 f ( y ) f(y) f(y)两点连线。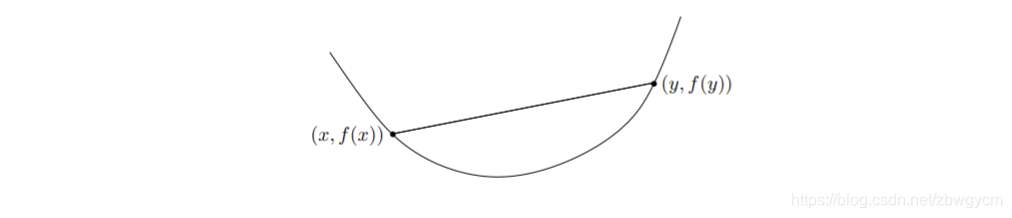
在凸函数中有两种比较重要的特例:
- 严格凸函数(strictly convex):把上述公式的 ≤ \leq ≤变为 < < <,即函数永远低于 f ( x ) f(x) f(x)和 f ( y ) f(y) f(y)两点连线,把线性情况给排除了。
- 强凸函数(strongly convex):即 f f f至少与二次函数一样凸,其最高阶数不小于2.
强凸意味着严格凸,他们都是凸函数的子集,他们的关系为:
s t r o n g l y c o n v e x ⊂ s t r i c t l y c o n v e x ⊂ c o n v e x strongly\ convex \subset strictly\ convex \subset convex strongly convex⊂strictly convex⊂convex
一些常见的函数如,指数函数,仿射函数,以及常用的范数和最大值函数等,都是凸函数。
凸函数的性质
从凸函数的定义我们可以得到两个性质:
-
一阶特性:如果 f f f是可微的,那么 f f f是凸函数,当且仅当 d o m ( f ) dom(f) dom(f)是凸的,且对于所有 x , y ∈ d o m ( f ) x,y\in dom(f) x,y∈dom(f),都有
f ( y ) ≥ f ( x ) + ∇ f ( x ) T ( y − x ) f(y)\geq f(x)+\nabla f(x)^T (y-x) f(y)≥f(x)+∇f(x)T(y−x) 因此对于一个可微的凸函数来说, ∇ f ( x ) = 0 ⇔ x m i n i m i z e s f \nabla f(x)=0 \Leftrightarrow x\ minimizes f ∇f(x)=0⇔x minimizesf。 -
二阶特性:如果 f f f是二次可微的,那么 f f f是凸函数,当且仅当 d o m ( f ) dom(f) dom(f)是凸的,且对于所有 x ∈ d o m ( f ) x\in dom(f) x∈dom(f)都有 ∇ 2 f ( x ) ≥ 0 \nabla ^2 f(x)\geq 0 ∇2f(x)≥0。
其次我们还能得到詹森不等式(Jensen’s inequality):如果 f f f是凸的,且 X X X是定义在 d o m ( f ) dom(f) dom(f)上的一个随机变量,那么有 f ( E [ X ] ) ≤ E [ f ( x ) ] f(E[X])\leq E[f(x)] f(E[X])≤E[f(x)]。
凸优化问题
前面我们给出了凸优化问题的定义,这里我们讨论凸优化问题的一些性质。
解集
令 X o p t X_{opt} Xopt为一个给定凸优化问题的所有解的集合,其可以写为:
X o p t = arg min x ∈ D f ( x ) X_{opt}=\arg\min_{x\in D} f(x) Xopt=argx∈Dminf(x)
s u b j e c t t o g i ( x ) ≤ 0 , i = 1 , . . . , m subject\ to\qquad g_i(x)\leq 0,\ i=1,...,m subject togi(x)≤0, i=1,...,m
A x = b Ax=b Ax=b
则 X o p t X_{opt} Xopt为凸集。
若 f f f为严格凸函数,那么解是唯一的,即 X o p t X_{opt} Xopt只包含一个元素。
一阶最优化条件
对于一个凸优化问题
min x f ( x ) s u b j e c t t o x ∈ C \min_{x}f(x)\ subject\ to\ x\in C xminf(x) subject to x∈C
且 f f f可微,一个可行点是最优的,当
∇ f ( x ) T ( y − x ) ≥ 0 \nabla f(x)^T(y-x)\geq 0 ∇f(x)T(y−x)≥0
换句话说,从当前点 x x x起的所有可行方向都与梯度方向对齐。当最优化问题是无约束时,该条件简化为 ∇ f ( x ) = 0 \nabla f(x)=0 ∇f(x)=0。
凸优化问题的层次
凸优化问题有许多分支,常见的有线性规划(linear programs, LPs),二次规划(qudaratic programs, QPs),半定规划(semidefinite programs, SDPs),锥规划(cone programs, CPs)。他们的关系为:
L P s ⊂ Q P s ⊂ S D P s ⊂ C P s ⊂ C o n v e x P r o g r a m s LPs \subset QPs \subset SDPs \subset CPs \subset Convex\ Programs LPs⊂QPs⊂SDPs⊂CPs⊂Convex Programs
典型的凸优化问题
线性规划
线性规划是最典型的一类凸优化问题,其基本形式为:
min x c T x s u b j e c t t o D x ≤ d A x = b \begin{aligned} \min_{x} c^Tx\\ subject\ to\qquad Dx\leq d\\ Ax=b \end{aligned} xmincTxsubject toDx≤dAx=b
许多解决线性规划的方法是单纯形法和内点法。压缩感知中的基追踪算法就是线性规划问题。
例子:基追踪
给定 y ∈ R n y\in R^n y∈Rn和 X ∈ R n × p X\in R^{n\times p} X∈Rn×p,其中 p > n p>n p>n。对于一个欠定线性系统 X β = y X\beta =y Xβ=y,我们想要找到其最稀疏的解,其可以表达为非凸优化形式:
min β ∥ β ∥ 0 s u b j e c t t o X β = y \begin{aligned} \min_{\beta}\|\beta\|_0\\ subject\ to\qquad X\beta =y \end{aligned} βmin∥β∥0subject toXβ=y
其中, ∥ β ∥ 0 = ∑ j = 1 p 1 { β j ≠ 0 } \|\beta\|_0=\sum^p_{j=1}1\{\beta_j \neq0\} ∥β∥0=∑j=1p1{βj=0},为 β \beta β的零阶范数( l 0 l_0 l0 norm)。
由于该问题是非凸的,我们可以对其做凸松弛,即进行 l 1 l_1 l1 norm近似,常常称为基追踪:
min β ∥ β ∥ 1 s u b j e c t t o X β = y \begin{aligned} \min_{\beta}\|\beta\|_1\\ subject\ to\qquad X\beta =y \end{aligned} βmin∥β∥1subject toXβ=y
基追踪是一个线性规划问题,可以将其变为基本形式:
min β , z 1 T z s u b j e c t t o z ≥ β z ≥ − β X β = y \begin{aligned} \min_{\beta,z}1^Tz\\ subject\ to\qquad z\geq \beta\\ z\geq -\beta\\ X\beta =y \end{aligned} β,zmin1Tzsubject toz≥βz≥−βXβ=y
二次规划
二次规划的基本形式为:
min x c T x + 1 2 x T Q x s u b j e c t t o D x ≤ d A x = b \begin{aligned} \min_{x}\ c^Tx+\frac{1}{2}x^TQx\\ subject\ to\qquad Dx\leq d\\ Ax=b \end{aligned} xmin cTx+21xTQxsubject toDx≤dAx=b
其中, Q ⪰ 0 Q\succeq 0 Q⪰0,即为正定的。
例子:支持向量机(SVM)
给定 y ∈ { − 1 , 1 } n y\in \{-1,1\}^n y∈{−1,1}n, X ∈ R n × p X\in R^{n\times p} X∈Rn×p有行向量 x 1 , . . . , x n x_1,...,x_n x1,...,xn,则支持向量机问题(support vector machine)定义为:
min β , β 0 , ξ 1 2 ∥ β ∥ 2 2 + C ∑ i = 1 n ξ i s u b j e c t t o ξ i ≥ 0 , i = 1 , . . . , n y i ( x i T β + β 0 ) ≥ 1 − ξ i , i = 1 , . . . , n \begin{aligned} \min_{\beta,\beta_0,\xi} &\frac{1}{2}\|\beta\|^2_2+C\sum^n_{i=1}\xi_i\\ subject\ to\qquad & \xi_i\geq 0,\ i=1,...,n\\ &y_i(x_i^T\beta + \beta_0) \geq1-\xi_i,\ i=1,...,n \end{aligned} β,β0,ξminsubject to21∥β∥22+Ci=1∑nξiξi≥0, i=1,...,nyi(xiTβ+β0)≥1−ξi, i=1,...,n
例子:lasso
给定 y ∈ R n y\in R^n y∈Rn, X ∈ R n × p X\in R^{n\times p} X∈Rn×p,则lasso问题定义为:
min β ∥ y − X β ∥ 2 2 s u b j e c t t o ∥ β ∥ 1 ≤ s \begin{aligned} \min_{\beta} \|y-X\beta\|^2_2\\ subject\ to\qquad \|\beta\|_1\leq s \end{aligned} βmin∥y−Xβ∥22subject to∥β∥1≤s
其中, s ≥ 0 s\geq 0 s≥0是一个可调参数。
将约束条件作为惩罚项加入到目标函数中可变形为:
min β ∥ y − X β ∥ 2 2 + λ ∥ β ∥ 1 \min_{\beta} \|y-X\beta\|^2_2+\lambda \|\beta\|_1 βmin∥y−Xβ∥22+λ∥β∥1
这两种形式是等价的。
参考资料

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)