
CiteSpace关键词聚类图谱含义详细解析
CiteSpace关键词聚类图谱含义详细解析回顾上一次推文:CiteSpace关键词共现图谱含义详细解析其中有一句:当你人工已经可以很容易的进行归纳后,就不需要再利用CiteSpace聚类功能啦。我们来看一下上次推文做出来的关键词共现图谱:人工不好归纳!那怎么聚类呢?此时便可使用CiteSpace的聚类功能啦!如下所示:我们可以清晰地看到上边的关键词共现网络聚成了一个个不规则区域...
CiteSpace关键词聚类图谱含义详细解析
回顾上一次推文:CiteSpace关键词共现图谱含义详细解析
其中有一句:
当你人工已经可以很容易的进行归纳后,就不需要再利用CiteSpace聚类功能啦。
我们来看一下上次推文做出来的关键词共现图谱:
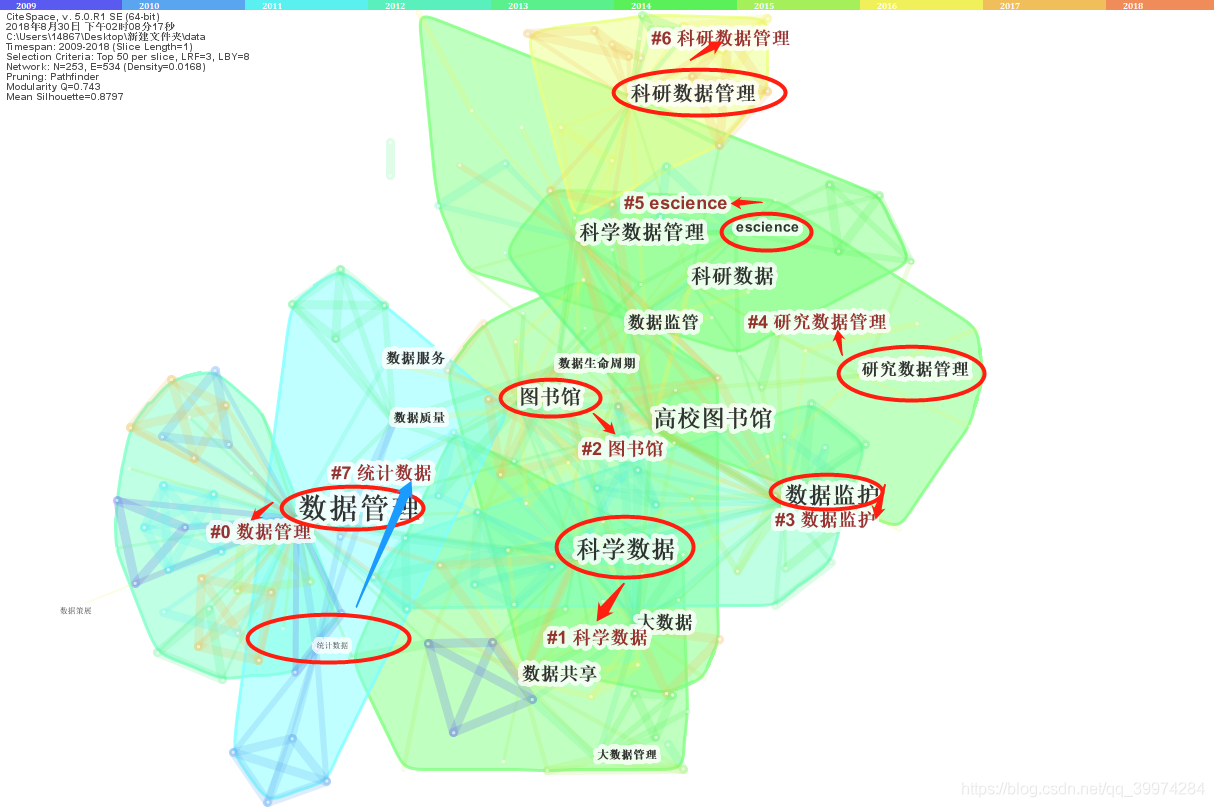
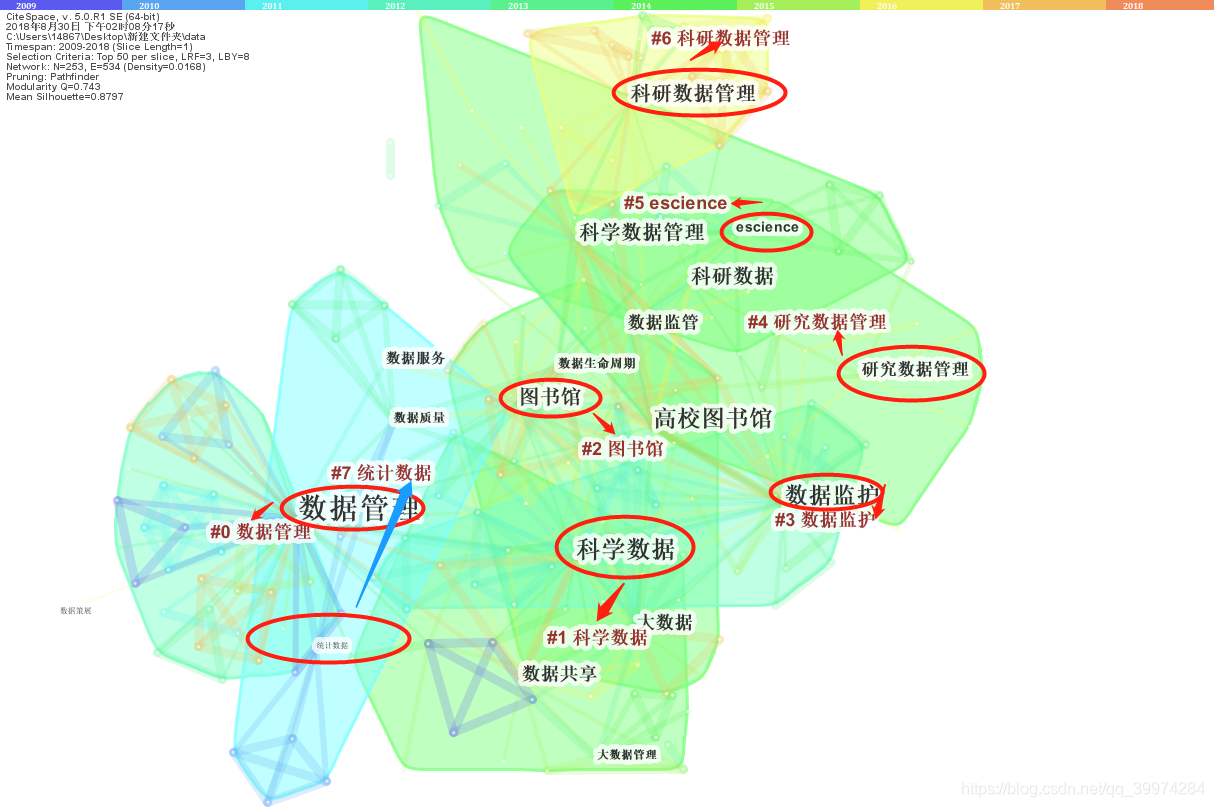
人工不好归纳!那怎么聚类呢?
此时便可使用CiteSpace的聚类功能啦!
如下所示:我们可以清晰地看到上边的关键词共现网络聚成了一个个不规则区域,每一个区域都对应着一个标签。
顺序是从0到7,数字越小,聚类中包含的关键词越多,每个聚类是多个紧密相关的词组成的,具体是那些关键词我们可以通过导出得报告得到详细信息。
在这个网络中我们需要注意两个数值,一个是Q值一个是S值,这两个数值表征着聚类想过的好坏,一般认为:
Modularity::聚类模块值(Q值),一般认为Q>0.3意味着聚类结构显著
Silhouette:S值:聚类平均轮廓值 ,一般认为S>0.5聚类类就是合理的,S>0.7意味着聚类是令人信服的。
如果这两个值不在此范围内,我们可以调节每年出现的次数或者网络的剪切算法。
但是,我们不能为了调值而调值,有时两个值是调好了,但是呢?图谱已经不能看了,结果根本就不符合实际啦。
所以呢,关于这两个值到底如何,我们还是需要根据图谱来判断。如果图谱合理了,即使值不在范围内也是可以。
另外,每个聚类都有一个标签,这个便签是怎么生成的呢?
这个答案,可以通过下图来回答。
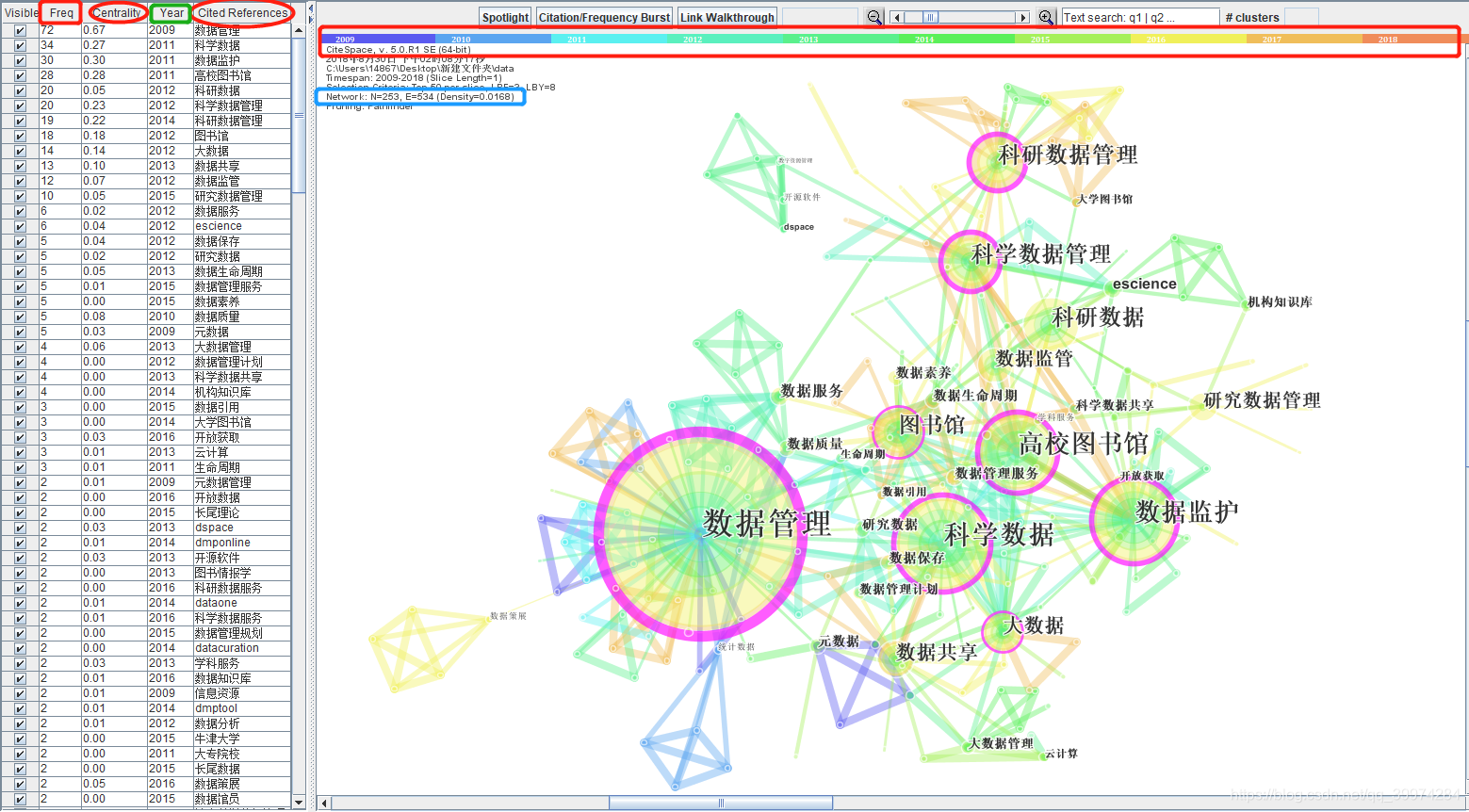
每个聚类竟然都是共现网络中的关键词。
也就是说我们得到的聚类标签其实早已经存在了网络中,只不过CiteSpace是通过算法将关系紧密的关键词进行聚类,然后会给每个关键词一个值,同一聚类中值最大的当选为该类别的代表,给它打上标签。
哦,原来是排序呀!简单。
这也是为什么开头告诉大家:当你人工已经可以很容易的进行归纳后,就不需要再利用CiteSpace聚类功能啦。
因为人工可以总结出共现图谱中没有的词,可以将多个词归纳成一个短语。
所以。。。你懂了吧。。。
既然已经聚类完成了,接下来就是根据聚类结果进行论述你的主题啦,这部分要靠你自己啦!
上图为老版本做的图,下图为新版本做的图,喜欢哪个自己抉择。
定量分析的大部分最终结果就是排序,只不过过程有所差异罢了。大到国家综合国力的比拼,小到自己考试考了多少分。所谓定量分析无非就是从数字的角度找到最优的结果。
比如文献定量中关键词频次排序获取研究热点,社会网络分析中点度中心性、接近中心性、中间中心性排序,获取网络中有影响力的行动者,上文CiteSpace聚类中的关键词排序得到该聚类的标签等等。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)