
Flink从入门到项目实践
Flink从入门到项目实践路过的朋友点个赞????呗,好人一身平安!!!https://github.com/perkinls/flink-local-trainApache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能。文章会对Flink中基本API如:DataSet、DataStream、Table、Sql和常用特性如:Time&a
Flink从入门到项目实践
路过的朋友点个赞👍呗,好人一身平安!!!项目地址 https://github.com/perkinls/flink-local-train
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能。文章会对Flink中基本API如:DataSet、DataStream、Table、Sql和常用特性如:Time&Window、窗口函数、Watermark、触发器、分布式缓存、异步IO、侧输出、广播和高级应用如:ProcessFunction、状态管理等知识点进行整理。
代码涵盖Java和Scala版本(因笔者时间和能力有限,代码仅供参考,如有错误的地方请多多指证)。好手不敌双拳,双拳不如四手!希望和大家一起成长、共同进步!
DataStream测试kafka的生产者为统一的Mock类,KafkaProducer可以指定不同的方法分别发送string、json、k/v格式数据。
Quick Start
在数据处理领域,WordCount就是HelloWorld。Flink自带WordCount例子,它通过socket读取text数据,并且统计每个单词出现的次数。
1、基本API

以上为Flink的运行模型(和Spark基本一致),Flink的程序主要由三部分构成,分别为Source、Transformation、Sink。DataSource主要负责数据的读取,Transformation主要负责对属于的转换操作,Sink负责最终数据的输出。
DataSet API
DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理。Flink先将接入数据(如可以通过读取文件或从本地集合)来创建转换成DataSet数据集,并行分布在集群的每个节点上;然后将DataSet数据集进行各种转换操作(map,filter,union,group等),最后通过DataSink操作将结果数据集输出到外部系统。
Flink中每一个的DataSet程序大致包含以下流程:
- step 1 : 获得一个执行环境(ExecutionEnvironment)
- step 2 : 加载/创建初始数据 (Source)
- step 3 : 指定转换算子操作数据(Transformation)
- step 4 : 指定存放结果位置(Sink)
DataStream API
DataStream API,是Flink API中最核心的数据结构,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作。Flink先将流式数据(如可以通过消息队列,套接字流,文件等)来创建DataStream,并行分布在集群的每个节点上;然后对DataStream数据流进行转换(filter,join, update state, windows, aggregat等),最后通过DataSink操作将DataStream输出到外部文件或存储系统中。
Flink中每一个DataStream程序大致包含以下流程:
- step 1 : 获得一个执行环境(StreamExecutionEnvironment)
- step 2 : 加载/创建初始数据 (Source)
- step 3 : 指定转换算子操作数据(Transformation)
- step 4 : 指定存放结果位置(Sink)
- step 5 : 手动触发执行
注意:
因为flink是lazy加载的,所以必须调用execute方法,上面的代码才会执行。
在DataSet和DataStrean中transformation 都是懒执行,需要最后使用env.execute()触发执行或者使用 print(),count(),collect() 触发执行。
Table & SQL API
Apache Flink 具有两个关系型API:Table API 和SQL。
Table & SQL API 还有另一个职责,就是流处理和批处理统一的 API 层。Flink 在 runtime 层是统一的,因为 Flink 将批任务看做流的一种特例来执行,这也是 Flink 向外鼓吹的一点。然而在编程模型上,Flink 却为批和流提供了两套 API (DataSet 和 DataStream)。为什么 runtime 统一,而编程模型不统一呢? 在我看来,这是本末倒置的事情。用户才不管你 runtime 层是否统一,用户更关心的是写一套代码。所以 Table & SQL API 就扛起了统一API的大旗,批上的查询会随着输入数据的结束而结束并生成有限结果集,流上的查询会一直运行并生成结果流。Table & SQL API做到了批与流上的查询具有同样的语法,因此不用改代码就能同时在批和流上跑。
Flink中每一个Table & Sql程序大致包含以下流程:
- step 1 : 获得一个执行环境(ExecutionEnvironment/StreamExecutionEnvironment)
- step 2 : 根据执行环境获取Table & Sql运行环境(TableEnvironment)
- step 3 : 注册输入表(Input table)
- step 4 : 执行Table & Sql查询
- step 5 : 输出表(Output table)结果发送到外部系统
代码案例:// TODO 等待更新中……
2、常用特性
累加器
Flink中累加器(Accumulators)是非常的简单,通过一个add操作累加最终的结果,在job执行后可以获取最终结果。
最直接的累加器是一个计数器(counter):你可以使用Accumulator.add()方法对其进行累加。在作业结束时,Flink将合并所有部分结果并将最终结果发送给客户端。在调试过程中,或者你快速想要了解有关数据的更多信息,累加器很有用。
目前Flink拥有以下内置累加器。它们中的每一个都实现了累加器接口:
(1) IntCounter, LongCounter 以及 DoubleCounter: 可参考案例中的计数器。
(2) Histogram:为离散数据的直方图(A histogram implementation for a discrete number of bins.)。内部它只是一个整数到整数的映射。你可以用它来计算值的分布,例如 单词计数程序的每行单词分配。
Flink中累加器的开发步骤大致如下:
- step 1 : 在你要使用的用户自定义转换函数中创建一个累加器(accumulator)对象
- step 2 : 注册累加器(accumulator)对象,通常在rich函数的open()方法中注册。在这里你也可以自定义累加器的名字。
- step 3 : 算子函数中的任何位置使用累加器
- step 4 : 最后结果将存储在JobExecutionResult对象中,该对象从执行环境的execute()方法返回(当前仅当执行等待作业完成时才起作用)
注意:
每个作业的所有累加器共享一个命名空间。因此,你可以在作业的不同算子函数中使用同一个累加器。Flink在内部合并所有具有相同名称的累加器。
目前累加器的结果只有在整个工作结束之后才可以使用。我们还计划在下一次迭代中可以使用前一次迭代的结果。你可以使用聚合器来计算每次迭代的统计信息,并基于此类统计信息来终止迭代。
分布式缓存
Flink提供了一个分布式缓存,类似于hadoop,可以使用户在并行函数中很方便的读取本地文件,并把它放在taskmanager节点中,防止task重复拉取。此缓存的工作机制如下:程序注册一个文件或者目录(本地或者远程文件系统,例如hdfs或者s3),通过ExecutionEnvironment注册缓存文件并为它起一个名称。
当程序执行,Flink自动将文件或者目录复制到所有taskmanager节点的本地文件系统,仅会执行一次。用户可以通过这个指定的名称查找文件或者目录,然后从taskmanager节点的本地文件系统访问它。其实分布式缓存就相当于spark的广播,把一个变量广播到所有的executor上,也可以看做是Flink的广播流,只不过这里广播的是一个文件.
Flink中分布式缓存开发步骤大致如下:
- step 1 : 注册一个文件,可以使用hdfs上的文件 也可以是本地文件进行测试
- step 2 : 通过RichFunction函数使用文件
注意:
在用户函数中访问缓存文件或者目录。这个函数必须继承RichFunction,因为它需要使用RuntimeContext读取数据。
累加器和分布式缓存或者更多相关文章可参考笔者博客:http://www.lllpan.top/article/40
DataStream Kafka Source
Flink提供了特殊的Kafka connector,用于从Kafka主题读写数据。 Flink Kafka Consumer与Flink的检查点(checkpoint)机制集成在一起,以提供有且仅有一次的语义。为此,Flink不仅仅依赖于Kafka的消费者群体偏移量跟踪,还内部跟踪和检查这些偏移量。
在真实的生产环境上,我们都需要保证系统的高可用。即需要保证系统的各个组件不能出现问题,或者提供一系列的容错机制。启用Flink的检查点后,Flink Kafka Consumer将在一个topic消费记录的时候,并以一致的方式定期记录Kafka偏移量和其它操作者的操作到检查点。万一作业失败,Flink将把流式程序恢复到最新检查点的状态,并从检查点中存储的偏移量开始重新使用Kafka的记录。
| Kafka版本 | 执行语义 |
|---|---|
| Kafka 0.8 | 在0.9之前Kafka没有提供任何机制去保证至少一次和仅仅一次的语义 |
| Kafka 0.9 and Kafka 0.10 | 0.9和0.10至少具有一次语义的保证,其中setLogFailureOnly设置为false,setFlushOnCheckpoint设置为true。 |
| Kafka 0.11 and newer | 启用Flink的检查点后,FlinkKafkaProducer011(适用于Kafka> = 1.0.0版本的FlinkKafkaProducer)可以提供有且仅有一次语义的保证。 |
可参考文章:https://blog.csdn.net/u013076044/article/details/102651473
Event Time与WaterMark
// TODO 等待更新中……
触发器Trigger
// TODO 等待更新中……
侧输出
- 乱序
- 分流
异步IO
Flink的Async I/O API允许用户将异步请求客户端与数据流一起使用。API处理与数据流的集成,以及处理顺序,事件时间,容错等。正确的实现flink的异步IO功能,需要所连接的数据库支持异步客户端。幸运的是很多流行的数据库支持这样的客户端。
Flink中异步I/O的开发步骤大致如下:
- step 1 : 实现AsyncFunction,该函数实现了请求分发的功能。
- step 2 : Callback回调,该函数取回操作的结果,然后传递给ResultFuture。
- step 3 : 对DataStream使用异步IO操作。
异步I/O详细介绍或者更多相关文章可参考笔者博客:http://www.lllpan.top/article/45
不同数据流join
// TODO 等待更新中……
DataStream Sink
// TODO 等待更新中……
3、高级应用
ProcessFunction
// TODO 等待更新中……
状态管理
// TODO 等待更新中……
4、项目案例
项目描述
通过Mock程序模拟产生用户日志数据实时推送到Kafka消息队列,使用Flink对原始日志数据进行清洗、加工、计算后分别统计:
- 最近一分钟每个域名产生的流量
- 一分钟内每个用户产生的流量(其中域名和用户有对应关系,数据存放于关系型数据库中)
架构
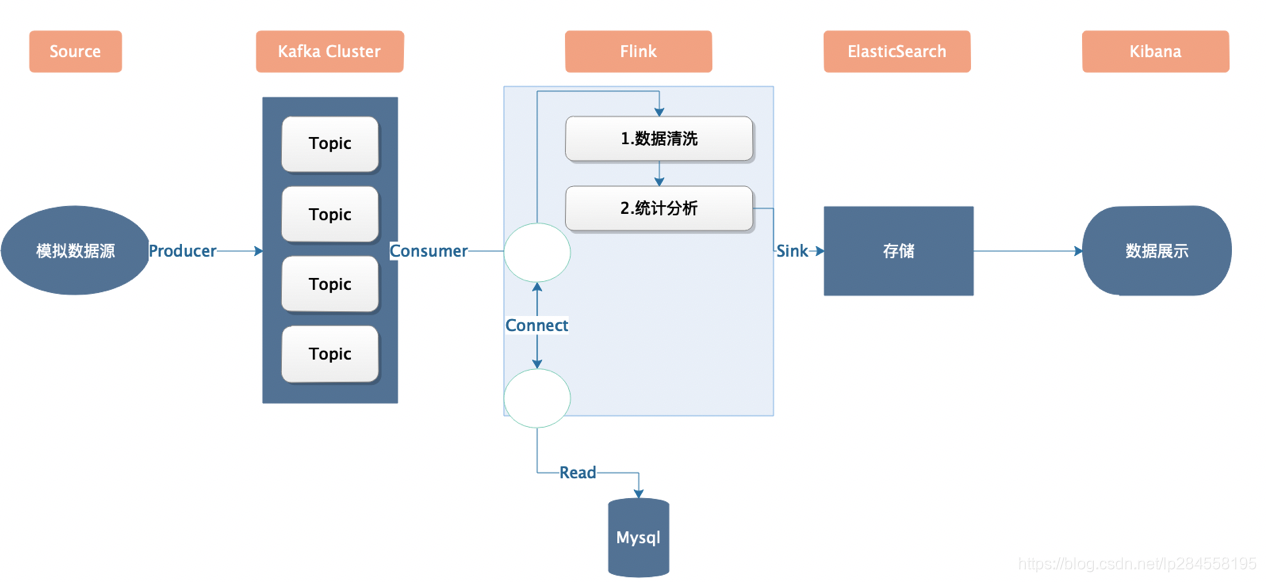
代码实现
// TODO 等待更新中……

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)