关于SVM初步的理解
最近模式识别课开始学SVM了,这次趁着这个机会把SVM弄明白。这边文章先把老吴机器学习课上的SVM部分总结一下,作为一个初级的入门总结。文章目录1. 优化目标2.大边界的直观理解3.大边界分类背后的数学4.核函数5.使用支持向量机1. 优化目标SVM之所以使用如此广泛,其在学习复杂的非线性方程方面更加强大。这里我们不用像教课一样上来就介绍什么函数间隔,几何间隔。直接上目标函数吧。从逻辑回...
最近模式识别课开始学SVM了,这次趁着这个机会把SVM弄明白。这边文章先把老吴机器学习课上的SVM部分总结一下,作为一个初级的入门总结。
1. 优化目标
SVM之所以使用如此广泛,其在学习复杂的非线性方程方面更加强大。
这里我们不用像教课一样上来就介绍什么函数间隔,几何间隔。直接上目标函数吧。
从逻辑回归到支持向量机

逻辑回归的假设函数就是我们所熟悉的sigmoid函数,将假设值与输出值构建为一个损失函数。

将逻辑回归优化函数改造成支持向量机:

还是一个二分类问题,只不过把损失函数改成了cost1和cost0函数,去掉了1/m也能获得最优θ。比如图中红色字体的例子。
最后说一下关于正则化项,通常在逻辑回归的目标函数中我们想最小化A,然后用一个正则化参数×其他项,使训练样本拟合的更好,一般正则化参数λ比较小,但是在支持向量机中,我们通常使用一个较大的C值×我们的代价A。

当我们通过最小化代价函数学校到参数θ时,支持向量机直接用其来预测y的值。
2.大边界的直观理解

从图中也可以看出来,支持向量机的假设函数额外嵌入一个安全因子。

求解这个优化问题,会得出一个大间距分类器。

简化后的最小化问题:
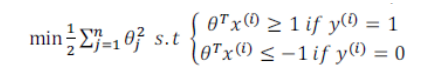
当出现异常点的影响时,正则化参数C如果非常大,就会得到分线,如果设置的不太大,还是会得到黑线。(C不是很大的时候,可以忽略掉一些异常点的影响,得到更好的决策界)

总结:C=1/λ:
C较大时,相当于λ较小,可能会导致过拟合,高方差。
C较小时,相当于λ较大,可能会导致欠拟合,高偏差。
3.大边界分类背后的数学
关于向量内积:

从图中可以看到,向量u的范数就是u的长度,也是向量u的欧几里得长度,是一个实数。
计算向量uv之间的内积有两种方法。一种是,将向量v投影到向量u上,我们将其投影长度记为p,p·||u||就是一种计算内积的方法。另一种是,计算公式法。
note:p是有符号的,可能是正值或者负值。取决于两个向量之间的夹角,大于90°为负。
下面我们就利用向量内积的性质来理解支持向量机中的目标函数。
支持向量机的目标函数:

为了简化,我们忽略掉θ0,当我们仅有两个特征时,式子可以写作: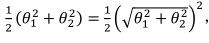
我们有两个参数,注意到括号里面是向量θ的范数,即其长度。
支持向量机做的事情就是极小化参数向量θ范数的平方,或者说长度的平方。
考虑一个训练样本x,投影到参数向量的长度记为p,可以改下SVM的决策边界函数。

这里的θ向量为决策函数的法向量,通过上图的优化目标,我们来看一下支持向量机选择的是什么样的决策界。

从上图中可以看出,左边的决策界会导致正样本点(x向量)投影较小,即如果想满足约束条件>=1那么θ向量的长度必须很大,不满足最小化目标函数(θ向量)的目标。
右边的决策界就不同了,投影p比较大,因此θ范数可以变小很多,因此通过目标函数优化选择一个较小的θ范数,支持向量机会选择右边的决策界。
note:间距就是每个样本的投影p值。
4.核函数
上面说的都是线性分类器,下面要讲的就是如何使用支持向量机建立一个非线性的分类器,这里需要用的就是核技巧。
之前讲过,对于非线性可分的样本点来说,我们可以模拟一个高阶的多项式模型构造一个分类器。
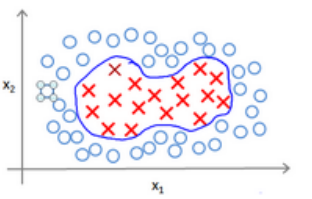
我们模型可能是:
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
θ
3
x
1
x
2
+
θ
4
x
1
2
+
θ
5
x
2
2
+
⋯
\theta_{0}+\theta_{1} x_{1}+\theta_{2} x_{2}+\theta_{3} x_{1} x_{2}+\theta_{4} x_{1}^{2}+\theta_{5} x_{2}^{2}+\cdots
θ0+θ1x1+θ2x2+θ3x1x2+θ4x12+θ5x22+⋯
核函数就是利用新的特征f来替换模型中的每一项:
f
1
=
x
1
,
f
2
=
x
2
,
f
3
=
x
1
x
2
,
f
4
=
x
1
2
,
f
5
=
x
2
2
f_{1}=x_{1}, f_{2}=x_{2}, f_{3}=x_{1} x_{2}, f_{4}=x_{1}^{2}, f_{5}=x_{2}^{2}
f1=x1,f2=x2,f3=x1x2,f4=x12,f5=x22
然后得到预测函数:
h
θ
(
x
)
=
θ
1
f
1
+
θ
2
f
2
+
…
+
θ
n
f
n
h_{\theta}(x)=\theta_{1} f_{1}+\theta_{2} f_{2}+\ldots+\theta_{n} f_{n}
hθ(x)=θ1f1+θ2f2+…+θnfn
这里引入一个地标的概念来。使用训练样本x的各个特征与各个地标的近似程度来选取我们的特征f1,f2,f3

其中:
∥
x
−
l
(
1
)
∥
2
=
∑
j
=
1
n
(
x
j
−
l
j
(
1
)
)
2
\left\|x-l^{(1)}\right\|^{2}=\sum_{j=1}^{n}\left(x_{j}-l_{j}^{(1)}\right)^{2}
∥∥∥x−l(1)∥∥∥2=j=1∑n(xj−lj(1))2为实例x的所有特征与地标l1之间距离之和。
similarity就是核函数,这里我们用的是一个高斯核函数。
我们引入地标有啥用?
可以看出,如果我们样本x与地标距离很近,特征f就近似于
e
−
0
=
1
e^{-0}=1
e−0=1
如果距离较远,则近似于
e
−
l
a
r
g
e
=
0
e^{-large}=0
e−large=0
给出一个具体的实例。

上图代表的意思就是,如果x与l重合时,f取最大值,σ2控制f改变的速率。
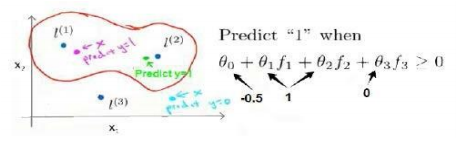
上图中,受到参数θ的控制,与地标l1和l2相近的点假设函数>0,预测y=1,反之预测为0。这就是我们的预测机制,不在是采用训练样本的特征,而是核函数计算出来的新特征,来预测类别。
那么问题来了,如何选择地标呢?
通常使用的是训练集的数量m。

所以对于每个样本来说,我们计算的是原有特征和训练集其他样本的距离。
下面将核函数运用到支持向量机中,修改假设函数。
- 给定x,计算新特征f,当
θ
T
f
>
=
0
\theta^{T} f>=0
θTf>=0预测y=1,反之亦然。
修改代价函数为:
Σ j = 1 n = m θ j 2 = θ T θ \Sigma_{j=1}^{n=m} \theta_{j}^{2}=\theta^{T} \theta Σj=1n=mθj2=θTθ
计算代价函数时,我们通常用θTMθ代替θTθ,便于简化计算。
最后总结下参数C和σ取值的影响:

note:有关偏差、方差的理解
5.使用支持向量机
调库+实践
其他核函数:(基本不会用)
多项式核函数(Polynomial Kernel)
字符串核函数(String kernel)
卡方核函数( chi-square kernel)
直方图交集核函数(histogram intersection kernel)
……
多分类问题
调库
关于LR vs. SVM?


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)