PASCAL-VOC:指标问题 miou、pix-acc:以项目:pytorch-deeplab-xception为例和语义分割常用loss介绍:语义分割博客
博客:https://www.jianshu.com/u/ed6d4d31c5b0http://host.robots.ox.ac.uk/pascal/VOC/voc2012/http://host.robots.ox.ac.uk/pascal/VOC/深度学习图像分割(一)——PASCAL-VOC2012数据集(vocdevkit、Vocbenchmark_release)详...
更新
2021.1.5
https://github.com/wkentaro/labelme/tree/v3.16.7/labelme/utils
labelme在3.16.7后大更新,没有了labelme/utils/draw.py
还有在下面的文章中
import os.path as osp
import numpy as np
import PIL.Image
from labelme.utils.draw import label_colormap
def lblsave(filename, lbl):
if osp.splitext(filename)[1] != '.png':
filename += '.png'
# Assume label ranses [-1, 254] for int32,
# and [0, 255] for uint8 as VOC.
if lbl.min() >= -1 and lbl.max() < 255:
lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')
colormap = label_colormap(255)
lbl_pil.putpalette((colormap * 255).astype(np.uint8).flatten())
lbl_pil.save(filename)
else:
raise ValueError(
'[%s] Cannot save the pixel-wise class label as PNG. '
'Please consider using the .npy format.' % filename
)
lbl图像中的值是index索引值,VOC的PNG就是存储的索引值,是对于你保存时候设置的调色板的索引,怕其他读者不理解解释下
博客:
https://www.jianshu.com/u/ed6d4d31c5b0

http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
http://host.robots.ox.ac.uk/pascal/VOC/
深度学习图像分割(一)——PASCAL-VOC2012数据集(vocdevkit、Vocbenchmark_release)详细介绍
https://blog.csdn.net/iamoldpan/article/details/79196413
指标:

VOC2012:
20 classes. The train/val data has 11,530 images containing 27,450 ROI annotated objects and 6,929 segmentations
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCdevkit_18-May-2011.tar
参考:
评估DEEPLAB-V2的分割结果:PIXEL ACCURACY、IOU
http://www.freesion.com/article/927933579/
论文笔记 | 基于深度学习的图像语义分割技术概述之5.1度量标准
https://blog.csdn.net/u014593748/article/details/71698246
语义分割代码阅读---评价指标mIoU的计算
https://blog.csdn.net/u012370185/article/details/94409933
mIoU源码解析
https://tianws.github.io/skill/2018/10/30/miou/
VOCevalseg.m
%VOCEVALSEG Evaluates a set of segmentation results.
% VOCEVALSEG(VOCopts,ID); prints out the per class and overall
% segmentation accuracies. Accuracies are given using the intersection/union
% metric:
% true positives / (true positives + false positives + false negatives)
%
% [ACCURACIES,AVACC,CONF] = VOCEVALSEG(VOCopts,ID) returns the per class
% percentage ACCURACIES, the average accuracy AVACC and the confusion
% matrix CONF.
%
% [ACCURACIES,AVACC,CONF,RAWCOUNTS] = VOCEVALSEG(VOCopts,ID) also returns
% the unnormalised confusion matrix, which contains raw pixel counts.
function [accuracies,avacc,conf,rawcounts] = VOCevalseg(VOCopts,id)
% image test set
[gtids,t]=textread(sprintf(VOCopts.seg.imgsetpath,VOCopts.testset),'%s %d');
% number of labels = number of classes plus one for the background
num = VOCopts.nclasses+1;
confcounts = zeros(num);
count=0;
tic;
for i=1:length(gtids)
% display progress
if toc>1
fprintf('test confusion: %d/%d\n',i,length(gtids));
drawnow;
tic;
end
imname = gtids{i};
% ground truth label file
gtfile = sprintf(VOCopts.seg.clsimgpath,imname);
[gtim,map] = imread(gtfile);
gtim = double(gtim);
% results file
resfile = sprintf(VOCopts.seg.clsrespath,id,VOCopts.testset,imname);
[resim,map] = imread(resfile);
resim = double(resim);
% Check validity of results image
maxlabel = max(resim(:));
if (maxlabel>VOCopts.nclasses),
error('Results image ''%s'' has out of range value %d (the value should be <= %d)',imname,maxlabel,VOCopts.nclasses);
end
szgtim = size(gtim); szresim = size(resim);
if any(szgtim~=szresim)
error('Results image ''%s'' is the wrong size, was %d x %d, should be %d x %d.',imname,szresim(1),szresim(2),szgtim(1),szgtim(2));
end
%pixel locations to include in computation
locs = gtim<255;
% joint histogram
sumim = 1+gtim+resim*num;
hs = histc(sumim(locs),1:num*num);
count = count + numel(find(locs));
confcounts(:) = confcounts(:) + hs(:);
end
% confusion matrix - first index is true label, second is inferred label
%conf = zeros(num);
conf = 100*confcounts./repmat(1E-20+sum(confcounts,2),[1 size(confcounts,2)]);
rawcounts = confcounts;
% Percentage correct labels measure is no longer being used. Uncomment if
% you wish to see it anyway
%overall_acc = 100*sum(diag(confcounts)) / sum(confcounts(:));
%fprintf('Percentage of pixels correctly labelled overall: %6.3f%%\n',overall_acc);
accuracies = zeros(VOCopts.nclasses,1);
fprintf('Accuracy for each class (intersection/union measure)\n');
for j=1:num
gtj=sum(confcounts(j,:));
resj=sum(confcounts(:,j));
gtjresj=confcounts(j,j);
% The accuracy is: true positive / (true positive + false positive + false negative)
% which is equivalent to the following percentage:
accuracies(j)=100*gtjresj/(gtj+resj-gtjresj);
clname = 'background';
if (j>1), clname = VOCopts.classes{j-1};end;
fprintf(' %14s: %6.3f%%\n',clname,accuracies(j));
end
accuracies = accuracies(1:end);
avacc = mean(accuracies);
fprintf('-------------------------\n');
fprintf('Average accuracy: %6.3f%%\n',avacc);
python版本:
https://github.com/jfzhang95/pytorch-deeplab-xception/blob/master/utils/metrics.py
https://gitlab.cs.washington.edu/kyleyan/deeplab-v3-plus/blob/master/evaluator.py
https://luckmoonlight.github.io/2019/03/12/FCN/
https://hangzhang.org/PyTorch-Encoding/_modules/encoding/utils/metrics.html
https://github.com/zhanghang1989/PyTorch-Encoding/blob/master/encoding/utils/metrics.py
https://github.com/Tramac/mobilenetv3-segmentation/blob/master/core/utils/metric.py
https://github.com/Tramac/awesome-semantic-segmentation-pytorch/blob/master/core/utils/score.py
https://github.com/Tramac/mobilenetv3-segmentation/blob/master/core/utils/visualize.py
https://luckmoonlight.github.io/2019/03/12/Maskrcnn/
https://zhuanlan.zhihu.com/p/61880018
关于数据集的问题:


因为VOC2012中的图片并不是都用于分割,所以需要txt文件信息来标记处哪些图片可以用于分割,写程序的时候就可以利用信息 train.txt 对图片进行挑选。train和val中的图片加一起一共2913张图。
20类:
- 人:人
- 动物:鸟,猫,牛,狗,马,羊
- 机动车类:飞机,自行车,船,巴士,小轿车,摩托车,火车
- 室内物品:瓶子,椅子,餐桌,花瓶,沙发,电视/显示器
SegmentationClass中的png图用于图像分割分类,下图中有两类物体,人和飞机,其中飞机和人都对应着特定的颜色,注意该文件夹中的图片为三通道彩色图,与之前单通道的灰度图不同。png图中对物体的分类像素不是0-20,而是对应着不同的RGB分量:

而SegmentationObject中的png图则仅仅对图中不同的物体进行的分割,不对其物体所属的类别进行标注



http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/index.html


https://blog.csdn.net/qq_30638831/article/details/83148308



import numpy as np
def voc_colormap(N=256):
def bitget(val, idx): return ((val & (1 << idx)) != 0)
cmap = np.zeros((N, 3), dtype=np.uint8)
for i in range(N):
r = g = b = 0
c = i
for j in range(8):
r |= (bitget(c, 0) << 7 - j)
g |= (bitget(c, 1) << 7 - j)
b |= (bitget(c, 2) << 7 - j)
c >>= 3
print([r, g, b])
cmap[i, :] = [r, g, b]
return cmap
VOC_COLORMAP = voc_colormap()[0, 0, 0]
[128, 0, 0]
[0, 128, 0]
[128, 128, 0]
[0, 0, 128]
[128, 0, 128]
[0, 128, 128]
[128, 128, 128]
[64, 0, 0]
[192, 0, 0]
[64, 128, 0]
[192, 128, 0]
[64, 0, 128]
[192, 0, 128]
[64, 128, 128]
[192, 128, 128]
[0, 64, 0]
[128, 64, 0]
[0, 192, 0]
[128, 192, 0]
[0, 64, 128]
[128, 64, 128]
[0, 192, 128]
[128, 192, 128]
[64, 64, 0]
[192, 64, 0]
[64, 192, 0]
[192, 192, 0]
[64, 64, 128]
[192, 64, 128]
[64, 192, 128]
[192, 192, 128]
[0, 0, 64]
[128, 0, 64]
[0, 128, 64]
[128, 128, 64]
[0, 0, 192]
[128, 0, 192]
[0, 128, 192]
[128, 128, 192]
[64, 0, 64]
[192, 0, 64]
[64, 128, 64]
[192, 128, 64]
[64, 0, 192]
[192, 0, 192]
[64, 128, 192]
[192, 128, 192]
[0, 64, 64]
[128, 64, 64]
[0, 192, 64]
[128, 192, 64]
[0, 64, 192]
[128, 64, 192]
[0, 192, 192]
[128, 192, 192]
[64, 64, 64]
[192, 64, 64]
[64, 192, 64]
[192, 192, 64]
[64, 64, 192]
[192, 64, 192]
[64, 192, 192]
[192, 192, 192]
[32, 0, 0]
[160, 0, 0]
[32, 128, 0]
[160, 128, 0]
[32, 0, 128]
[160, 0, 128]
[32, 128, 128]
[160, 128, 128]
[96, 0, 0]
[224, 0, 0]
[96, 128, 0]
[224, 128, 0]
[96, 0, 128]
[224, 0, 128]
[96, 128, 128]
[224, 128, 128]
[32, 64, 0]
[160, 64, 0]
[32, 192, 0]
[160, 192, 0]
[32, 64, 128]
[160, 64, 128]
[32, 192, 128]
[160, 192, 128]
[96, 64, 0]
[224, 64, 0]
[96, 192, 0]
[224, 192, 0]
[96, 64, 128]
[224, 64, 128]
[96, 192, 128]
[224, 192, 128]
[32, 0, 64]
[160, 0, 64]
[32, 128, 64]
[160, 128, 64]
[32, 0, 192]
[160, 0, 192]
[32, 128, 192]
[160, 128, 192]
[96, 0, 64]
[224, 0, 64]
[96, 128, 64]
[224, 128, 64]
[96, 0, 192]
[224, 0, 192]
[96, 128, 192]
[224, 128, 192]
[32, 64, 64]
[160, 64, 64]
[32, 192, 64]
[160, 192, 64]
[32, 64, 192]
[160, 64, 192]
[32, 192, 192]
[160, 192, 192]
[96, 64, 64]
[224, 64, 64]
[96, 192, 64]
[224, 192, 64]
[96, 64, 192]
[224, 64, 192]
[96, 192, 192]
[224, 192, 192]
[0, 32, 0]
[128, 32, 0]
[0, 160, 0]
[128, 160, 0]
[0, 32, 128]
[128, 32, 128]
[0, 160, 128]
[128, 160, 128]
[64, 32, 0]
[192, 32, 0]
[64, 160, 0]
[192, 160, 0]
[64, 32, 128]
[192, 32, 128]
[64, 160, 128]
[192, 160, 128]
[0, 96, 0]
[128, 96, 0]
[0, 224, 0]
[128, 224, 0]
[0, 96, 128]
[128, 96, 128]
[0, 224, 128]
[128, 224, 128]
[64, 96, 0]
[192, 96, 0]
[64, 224, 0]
[192, 224, 0]
[64, 96, 128]
[192, 96, 128]
[64, 224, 128]
[192, 224, 128]
[0, 32, 64]
[128, 32, 64]
[0, 160, 64]
[128, 160, 64]
[0, 32, 192]
[128, 32, 192]
[0, 160, 192]
[128, 160, 192]
[64, 32, 64]
[192, 32, 64]
[64, 160, 64]
[192, 160, 64]
[64, 32, 192]
[192, 32, 192]
[64, 160, 192]
[192, 160, 192]
[0, 96, 64]
[128, 96, 64]
[0, 224, 64]
[128, 224, 64]
[0, 96, 192]
[128, 96, 192]
[0, 224, 192]
[128, 224, 192]
[64, 96, 64]
[192, 96, 64]
[64, 224, 64]
[192, 224, 64]
[64, 96, 192]
[192, 96, 192]
[64, 224, 192]
[192, 224, 192]
[32, 32, 0]
[160, 32, 0]
[32, 160, 0]
[160, 160, 0]
[32, 32, 128]
[160, 32, 128]
[32, 160, 128]
[160, 160, 128]
[96, 32, 0]
[224, 32, 0]
[96, 160, 0]
[224, 160, 0]
[96, 32, 128]
[224, 32, 128]
[96, 160, 128]
[224, 160, 128]
[32, 96, 0]
[160, 96, 0]
[32, 224, 0]
[160, 224, 0]
[32, 96, 128]
[160, 96, 128]
[32, 224, 128]
[160, 224, 128]
[96, 96, 0]
[224, 96, 0]
[96, 224, 0]
[224, 224, 0]
[96, 96, 128]
[224, 96, 128]
[96, 224, 128]
[224, 224, 128]
[32, 32, 64]
[160, 32, 64]
[32, 160, 64]
[160, 160, 64]
[32, 32, 192]
[160, 32, 192]
[32, 160, 192]
[160, 160, 192]
[96, 32, 64]
[224, 32, 64]
[96, 160, 64]
[224, 160, 64]
[96, 32, 192]
[224, 32, 192]
[96, 160, 192]
[224, 160, 192]
[32, 96, 64]
[160, 96, 64]
[32, 224, 64]
[160, 224, 64]
[32, 96, 192]
[160, 96, 192]
[32, 224, 192]
[160, 224, 192]
[96, 96, 64]
[224, 96, 64]
[96, 224, 64]
[224, 224, 64]
[96, 96, 192]
[224, 96, 192]
[96, 224, 192]
[224, 224, 192]前21个颜色为VOC的颜色
在项目:pytorch-deeplab-xception
直接读取SegmentationClass为target
def _make_img_gt_point_pair(self, index):
_img = Image.open(self.images[index]).convert('RGB')
_target = Image.open(self.categories[index])
return _img, _targetNumber of images in train: 1464
Number of images in val: 1449
num_class:21# Define Evaluator
self.evaluator = Evaluator(self.nclass)import numpy as np
class Evaluator(object):
def __init__(self, num_class):
self.num_class = num_class
self.confusion_matrix = np.zeros((self.num_class,)*2)
def Pixel_Accuracy(self):
Acc = np.diag(self.confusion_matrix).sum() / self.confusion_matrix.sum()
return Acc
def Pixel_Accuracy_Class(self):
Acc = np.diag(self.confusion_matrix) / self.confusion_matrix.sum(axis=1)
Acc = np.nanmean(Acc)
return Acc
def Mean_Intersection_over_Union(self):
MIoU = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
MIoU = np.nanmean(MIoU)
return MIoU
def Frequency_Weighted_Intersection_over_Union(self):
freq = np.sum(self.confusion_matrix, axis=1) / np.sum(self.confusion_matrix)
iu = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
FWIoU = (freq[freq > 0] * iu[freq > 0]).sum()
return FWIoU
def _generate_matrix(self, gt_image, pre_image):
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def add_batch(self, gt_image, pre_image):
assert gt_image.shape == pre_image.shape
self.confusion_matrix += self._generate_matrix(gt_image, pre_image)
def reset(self):
self.confusion_matrix = np.zeros((self.num_class,) * 2)
# /train/results/ynh_copy/Dataset/pytorch-deeplab-xception/utils/metrics.py:14: RuntimeWarning: invalid value encountered in true_divide
# Acc = np.diag(self.confusion_matrix) / self.confusion_matrix.sum(axis=1)
# /train/results/ynh_copy/Dataset/pytorch-deeplab-xception/utils/metrics.py:21: RuntimeWarning: invalid value encountered in true_divide
# np.diag(self.confusion_matrix))
# /train/results/ynh_copy/Dataset/pytorch-deeplab-xception/utils/metrics.py:29: RuntimeWarning: invalid value encountered in true_divide
# np.diag(self.confusion_matrix))训练时:
for i, sample in enumerate(tbar):
image, target = sample['image'], sample['label']images=2*3*513*513
target=513*513
这里有一个细节:
PIL的模式


原来在制作的时候就可以通过PIL载入调色板,保存图像,PIL打开的时候,该图像也会通过调色板打开,model为P
labelme等工具制作时候:
lbl_pil.putpalette((colormap * 255).astype(np.uint8).flatten())
/usr/local/lib/python2.7/dist-packages/labelme/utils/_io.py
import os.path as osp
import numpy as np
import PIL.Image
from labelme.utils.draw import label_colormap
def lblsave(filename, lbl):
if osp.splitext(filename)[1] != '.png':
filename += '.png'
# Assume label ranses [-1, 254] for int32,
# and [0, 255] for uint8 as VOC.
if lbl.min() >= -1 and lbl.max() < 255:
lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')
colormap = label_colormap(255)
lbl_pil.putpalette((colormap * 255).astype(np.uint8).flatten())
lbl_pil.save(filename)
else:
raise ValueError(
'[%s] Cannot save the pixel-wise class label as PNG. '
'Please consider using the .npy format.' % filename
)
/usr/local/lib/python2.7/dist-packages/labelme/utils/draw.py
def label_colormap(N=256):
def bitget(byteval, idx):
return ((byteval & (1 << idx)) != 0)
cmap = np.zeros((N, 3))
for i in range(0, N):
id = i
r, g, b = 0, 0, 0
for j in range(0, 8):
r = np.bitwise_or(r, (bitget(id, 0) << 7 - j))
g = np.bitwise_or(g, (bitget(id, 1) << 7 - j))
b = np.bitwise_or(b, (bitget(id, 2) << 7 - j))
id = (id >> 3)
cmap[i, 0] = r
cmap[i, 1] = g
cmap[i, 2] = b
cmap = cmap.astype(np.float32) / 255
return cmap通过调色板那么其实该图像对应坐标的值为类别index:0,1,...........20

这里面有 背景 人 未知(255) 飞机
对应 0 15 255 1

保存成excel:




from PIL import Image
import matplotlib.pyplot as plt
import openpyxl
img1 = Image.open("/home/spple/data/VOCdevkit/VOC2012/SegmentationClass/2007_000032.png")
pix = img1.load()
width = img1.size[0]
height = img1.size[1]
wb = openpyxl.Workbook()
ws = wb.active
#https://www.mobibrw.com/2017/7313
for i in range(height):
row = []
for j in range(width):
row.append(pix[j, i])
ws.append(row)
wb.save('./example.xls')
# plt.figure("2007_000032_1")
# plt.imshow(img1)
# plt.show()
#
# import cv2
# img2 = cv2.imread("/home/spple/data/VOCdevkit/VOC2012/SegmentationClass/2007_000032.png")
# cv2.imshow("2007_000032_2",img2)
# cv2.waitKey()https://blog.csdn.net/u013249853/article/details/94715443
VOC的标注22个,从0-21,其中21 是未标注类,不过实际上读取出来是255,所以你的标签[0,...20,255]
out数据的要求是int,数值在[0,...20,255]
接着前向传播:
if self.args.cuda:
image, target = image.cuda(), target.cuda()
self.scheduler(self.optimizer, i, epoch, self.best_pred)
self.optimizer.zero_grad()
output = self.model(image)
loss = self.criterion(output, target)
loss.backward()
self.optimizer.step()
train_loss += loss.item()这里有两个问题,输出是什么,loss是什么
输出为2*21*513*513,第一个2为batch_size,第二个类别数目,在pytorch-deeplab-xception/dataloaders/__init__.py
中指定:
if args.dataset == 'pascal':
train_set = pascal.VOCSegmentation(args, split='train')
val_set = pascal.VOCSegmentation(args, split='val')
if args.use_sbd:
sbd_train = sbd.SBDSegmentation(args, split=['train', 'val'])
train_set = combine_dbs.CombineDBs([train_set, sbd_train], excluded=[val_set])
num_class = train_set.NUM_CLASSES
#num_class = 2
train_loader = DataLoader(train_set, batch_size=args.batch_size, shuffle=True, **kwargs)
val_loader = DataLoader(val_set, batch_size=args.batch_size, shuffle=False, **kwargs)
test_loader = None
return train_loader, val_loader, test_loader, num_class
接着把output和target一起送入loss:
args.cuda = not args.no_cuda and torch.cuda.is_available()
# Define Criterion
# whether to use class balanced weights
if args.use_balanced_weights:
classes_weights_path = os.path.join(Path.db_root_dir(args.dataset), args.dataset+'_classes_weights.npy')
if os.path.isfile(classes_weights_path):
weight = np.load(classes_weights_path)
else:
weight = calculate_weigths_labels(args.dataset, self.train_loader, self.nclass)
weight = torch.from_numpy(weight.astype(np.float32))
else:
weight = None
self.criterion = SegmentationLosses(weight=weight, cuda=args.cuda).build_loss(mode=args.loss_type)
self.model, self.optimizer = model, optimizerimport torch
import torch.nn as nn
class SegmentationLosses(object):
def __init__(self, weight=None, size_average=True, batch_average=True, ignore_index=255, cuda=False):
self.ignore_index = ignore_index
self.weight = weight
self.size_average = size_average
self.batch_average = batch_average
self.cuda = cuda
def build_loss(self, mode='ce'):
"""Choices: ['ce' or 'focal']"""
if mode == 'ce':
return self.CrossEntropyLoss
elif mode == 'focal':
return self.FocalLoss
else:
raise NotImplementedError
def CrossEntropyLoss(self, logit, target):
n, c, h, w = logit.size()
criterion = nn.CrossEntropyLoss(weight=self.weight, ignore_index=self.ignore_index,
size_average=self.size_average)
if self.cuda:
criterion = criterion.cuda()
loss = criterion(logit, target.long())
if self.batch_average:
loss /= n
return loss
def FocalLoss(self, logit, target, gamma=2, alpha=0.5):
n, c, h, w = logit.size()
criterion = nn.CrossEntropyLoss(weight=self.weight, ignore_index=self.ignore_index,
size_average=self.size_average)
if self.cuda:
criterion = criterion.cuda()
logpt = -criterion(logit, target.long())
pt = torch.exp(logpt)
if alpha is not None:
logpt *= alpha
loss = -((1 - pt) ** gamma) * logpt
if self.batch_average:
loss /= n
return loss
if __name__ == "__main__":
loss = SegmentationLosses(cuda=True)
a = torch.rand(1, 3, 7, 7).cuda()
b = torch.rand(1, 7, 7).cuda()
print(loss.CrossEntropyLoss(a, b).item())
print(loss.FocalLoss(a, b, gamma=0, alpha=None).item())
print(loss.FocalLoss(a, b, gamma=2, alpha=0.5).item())loss类型这里默认ce:
parser.add_argument('--loss-type', type=str, default='ce',
choices=['ce', 'focal'],
help='loss func type (default: ce)') def build_loss(self, mode='ce'):
"""Choices: ['ce' or 'focal']"""
if mode == 'ce':
return self.CrossEntropyLoss
elif mode == 'focal':
return self.FocalLoss
else:
raise NotImplementedError def CrossEntropyLoss(self, logit, target):
n, c, h, w = logit.size()
criterion = nn.CrossEntropyLoss(weight=self.weight, ignore_index=self.ignore_index,
size_average=self.size_average)
if self.cuda:
criterion = criterion.cuda()
loss = criterion(logit, target.long())
if self.batch_average:
loss /= n
return loss这里:
logit为torch.Size([2, 21, 513, 513])
target为torch.Size([2, 513, 513])https://www.cnblogs.com/JeasonIsCoding/p/10171201.html
这里函数内部,会把target变成ont-hot形式,比如原本是飞机在target上为:1,变成了
[0
1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]

这里的N是21,也就是类别数,总loss=求和符号(2*513*513) * y^(N=21) / 513*513*2
如果不累加 loss为矩阵 2*513*513 *y^(N=21)
import torch
from torch import nn
from torch.autograd import Variable
input = Variable(torch.ones(4,3,2,2), requires_grad=True)
target = Variable(torch.LongTensor([
[[0,1],[1,0]],
[[0,1],[1,0]],
[[0,1],[1,0]],
[[0,1],[1,0]]
]))
print('input:', input)
print('target:', target)
loss = nn.CrossEntropyLoss()
print('loss: ', loss(input, target))loss: tensor(1.0986, grad_fn=<NllLoss2DBackward>)
loss = nn.CrossEntropyLoss(size_average=False)loss: tensor(17.5778, grad_fn=<NllLoss2DBackward>)
17.5778 = 1.0986*4*2*2
loss: tensor([[[1.0986, 1.0986], [1.0986, 1.0986]], [[1.0986, 1.0986], [1.0986, 1.0986]], [[1.0986, 1.0986], [1.0986, 1.0986]], [[1.0986, 1.0986], [1.0986, 1.0986]]], grad_fn=<NllLoss2DBackward>)y^(N=21):
这里以class=3为例子展示:
numpy实现CrossEntropyLoss
https://blog.csdn.net/qq_41805511/article/details/99438838
x 的维度是 (batch_size, C)
class 的维度是 (batch_size)
(这里的 C 是分类的个数)input 对应的是上面公式的 x,target 对应的是 class
#x 的维度是 (batch_size, C) #class 的维度是 (batch_size) import numpy as np input = np.ones([4*2*2,3]) target = [0,1,1,0, 0,1,1,0, 0,1,1,0, 0,1,1,0] batch_loss = 0. for i in range(input.shape[0]): # 分子 numerator = np.exp(input[i, target[i]]) # 分母 denominator = np.sum(np.exp(input[i, :])) loss = -np.log(numerator / denominator) batch_loss += loss print('batch_loss',batch_loss)batch_loss 17.577796618689753
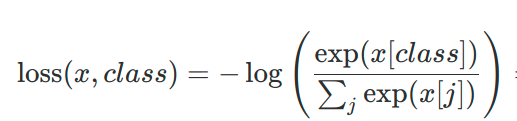
https://www.jianshu.com/p/a6131515ee1d
pytorch : CrossEntropyLoss 应用于语义分割
https://blog.csdn.net/zhaowangbo/article/details/100039837
F.cross_entroy和nn.CrossEntropyLoss
https://blog.csdn.net/wangdongwei0/article/details/84576044
【LOSS】语义分割的各种loss详解与实现
https://blog.csdn.net/CaiDaoqing/article/details/90457197
语义分割常用loss介绍及pytorch实现
https://blog.csdn.net/ShuqiaoS/article/details/87360693#_139
【语义分割】综述——一文搞定语义分割:定义损失函数
https://blog.csdn.net/ShuqiaoS/article/details/87690424
【阅读笔记】(语义分割最全总结,综述)《A Review on Deep Learning Techniques Applied to Semantic Segmentation》
对于图像分割任务,最常用的损失就是像素级交叉熵损失(pixel-wise cross entropy loss)。这个损失通过比较类别估计class predictions(深度上的像素向量 depth-wise pixel vector)与真值(one-hot encoded target vector),从而检测每个像素。
由于交叉熵损失单独评估每个像素再对所有像素的损失求平均值,我们本质上实现的是每个像素都有等同的待遇。然而,当训练过程中有一部分类别占据主导作用的时候,这种图像中表述的不平和可能由于上述原因出现问题。Long等人在FCN中讨论了对每个输出通道赋予权重以应对数据集中的类别不均衡问题。

loss:
tensor(2.9356, device='cuda:0', grad_fn=<NllLoss2DBackward>)
如果设置
reduce=Falseloss:
tensor([[[2.7611, 2.7011, 2.6515, ..., 3.2548, 3.3593, 3.4847],
[2.7527, 2.7211, 2.6953, ..., 3.1949, 3.3163, 3.4529],
[2.7592, 2.7513, 2.7480, ..., 3.1467, 3.2846, 3.4355],
...,
[2.8579, 2.7040, 2.5672, ..., 2.5546, 2.3595, 2.1800],
[2.9280, 2.8205, 2.7319, ..., 2.6712, 2.5137, 2.3674],
[3.0218, 2.9588, 2.9299, ..., 2.8076, 2.6921, 2.5896]],[[3.3353, 3.1151, 2.9082, ..., 2.8563, 2.8269, 2.8102],
[3.3309, 3.1318, 2.9437, ..., 2.9114, 2.8987, 2.8937],
[3.3429, 3.1652, 2.9987, ..., 2.9717, 2.9772, 2.9889],
...,
[2.5517, 2.5882, 2.6362, ..., 2.2755, 2.4456, 2.6401],
[2.4921, 2.5368, 2.5955, ..., 2.1179, 2.3247, 2.5585],
[2.4547, 2.4990, 2.5648, ..., 1.9749, 2.2207, 2.5182]]],
device='cuda:0', grad_fn=<NllLoss2DBackward>)torch.Size([2, 513, 513])
def CrossEntropyLoss(self, logit, target): n, c, h, w = logit.size() criterion = nn.CrossEntropyLoss(weight=self.weight, ignore_index=self.ignore_index, size_average=self.size_average, reduce=True) #reduce=False if self.cuda: criterion = criterion.cuda() loss = criterion(logit, target.long()) if self.batch_average: loss /= n return loss所以最后会进行一次 loss /= n 对batch进行平均
size_average = True reduce=None下:
loss 会在每个 mini-batch(小批量) 上取平均值. 如果字段 size_average 被设置为 False, loss 将会在每个 mini-batch(小批量) 上累加, 而不会取平均值.
那么这个 mini_batch_size 等于几呢? 在程序中,网络输出形状为 4-d Tensor: ( batch_size, channel, width, height)。 注意: mini_batch_size != batch_size, 而是:
mini_batch_size = batch_size * width * height.
这非常好理解,因为语义分割本质上是 pixel-level classification, 所以 mini_batch_size 就等于一个 batch 图像中的 像素总数。
CrossEntropyLoss
class torch.nn.CrossEntropyLoss(weight=None, size_average=True, ignore_index=-100, reduce=True)作用:

参数:

接着 评估指标:
for epoch in range(trainer.args.start_epoch, trainer.args.epochs):
trainer.training(epoch)
if not trainer.args.no_val and epoch % args.eval_interval == (args.eval_interval - 1):
trainer.validation(epoch)我改变了VOC的txt,训练集为20张,测试集为50张
混淆矩阵:21*2
def reset(self):
self.confusion_matrix = np.zeros((self.num_class,) * 2)21*21=441

def validation(self, epoch):
self.model.eval()
self.evaluator.reset()
tbar = tqdm(self.val_loader, desc='\r')
test_loss = 0.0
for i, sample in enumerate(tbar):
image, target = sample['image'], sample['label']
if self.args.cuda:
image, target = image.cuda(), target.cuda()
with torch.no_grad():
output = self.model(image)
loss = self.criterion(output, target)
test_loss += loss.item()
tbar.set_description('Test loss: %.3f' % (test_loss / (i + 1)))
pred = output.data.cpu().numpy()
target = target.cpu().numpy()
pred = np.argmax(pred, axis=1)
# Add batch sample into evaluator
self.evaluator.add_batch(target, pred)
# Fast test during the training
Acc = self.evaluator.Pixel_Accuracy()
Acc_class = self.evaluator.Pixel_Accuracy_Class()
mIoU = self.evaluator.Mean_Intersection_over_Union()
FWIoU = self.evaluator.Frequency_Weighted_Intersection_over_Union()
self.writer.add_scalar('val/total_loss_epoch', test_loss, epoch)
self.writer.add_scalar('val/mIoU', mIoU, epoch)
self.writer.add_scalar('val/Acc', Acc, epoch)
self.writer.add_scalar('val/Acc_class', Acc_class, epoch)
self.writer.add_scalar('val/fwIoU', FWIoU, epoch)
print('Validation:')
print('[Epoch: %d, numImages: %5d]' % (epoch, i * self.args.batch_size + image.data.shape[0]))
print("Acc:{}, Acc_class:{}, mIoU:{}, fwIoU: {}".format(Acc, Acc_class, mIoU, FWIoU))
print('Loss: %.3f' % test_loss)
new_pred = mIoU
if new_pred > self.best_pred:
is_best = True
self.best_pred = new_pred
self.saver.save_checkpoint({
'epoch': epoch + 1,
'state_dict': self.model.module.state_dict(),
'optimizer': self.optimizer.state_dict(),
'best_pred': self.best_pred,
}, is_best)val的batchsize=2, 50张为25次
把tensor转换为numpy:
image, target = sample['image'], sample['label']
if self.args.cuda:
image, target = image.cuda(), target.cuda()
with torch.no_grad():
output = self.model(image)
loss = self.criterion(output, target)
test_loss += loss.item()
tbar.set_description('Test loss: %.3f' % (test_loss / (i + 1)))
pred = output.data.cpu().numpy()
target = target.cpu().numpy()
pred = np.argmax(pred, axis=1)
# Add batch sample into evaluator
self.evaluator.add_batch(target, pred)output=torch.Size([2, 21, 513, 513])
target=<class 'tuple'>: (2, 513, 513)
pred=<class 'tuple'>: (2, 513, 513)---------由max^21 [2, 21, 513, 513] 得到
def add_batch(self, gt_image, pre_image):
assert gt_image.shape == pre_image.shape
self.confusion_matrix += self._generate_matrix(gt_image, pre_image) def _generate_matrix(self, gt_image, pre_image):
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrixgt_image留下区间在[0-21]的值作为mask,即位置索引的bool值,确定位置是否取=<class 'tuple'>: (2, 513, 513)
其中 (513*513*2=526338)
xxx = np.sum(mask == True)
yyy = np.sum(mask == False)
xxx = 498383
yyy = 27955
label=<class 'tuple'>: (498383,)
count=<class 'tuple'>: (441,)
confusion_matrix=<class 'tuple'>: (21, 21)
Python—numpy.bincount()
https://www.cnblogs.com/eilearn/p/9015375.html
# 我们可以看到x中最大的数为7,因此bin的数量为8,那么它的索引值为0->7 x = np.array([0, 1, 1, 3, 2, 1, 7]) # 索引0出现了1次,索引1出现了3次......索引5出现了0次...... np.bincount(x) #因此,输出结果为:array([1, 3, 1, 1, 0, 0, 0, 1]) # 我们可以看到x中最大的数为7,因此bin的数量为8,那么它的索引值为0->7 x = np.array([7, 6, 2, 1, 4]) # 索引0出现了0次,索引1出现了1次......索引5出现了0次...... np.bincount(x) #输出结果为:array([0, 1, 1, 0, 1, 0, 1, 1])# 我们可以看到x中最大的数为3,因此bin的数量为4,那么它的索引值为0->3 x = np.array([3, 2, 1, 3, 1]) # 本来bin的数量为4,现在我们指定了参数为7,因此现在bin的数量为7,所以现在它的索引值为0->6 np.bincount(x, minlength=7) # 因此,输出结果为:array([0, 2, 1, 2, 0, 0, 0])minlength=21*21=441
这里看矩阵
gt_image

mask:

gt_image[mask].astype('int')会转换成对应类别比如类别1:
self.num_class * gt_image[mask].astype('int')通过变成21,
如果是类别19,
变成399
gt要有,pred也要有的即为,预测正确的
第一个图的混淆矩阵
confusion_matrix


参考:
https://oldpan.me/archives/understand-coco-metric
https://tianws.github.io/skill/2018/10/30/miou/
https://www.jeremyjordan.me/evaluating-image-segmentation-models/
关于混淆矩阵:



红色圆代表真实值,黄色圆代表预测值。橙色部分为两圆交集部分。
把50张测试图像的混淆矩阵加和:25*batch_size(2)


Acc = self.evaluator.Pixel_Accuracy()
Acc_class = self.evaluator.Pixel_Accuracy_Class()
mIoU = self.evaluator.Mean_Intersection_over_Union()
FWIoU = self.evaluator.Frequency_Weighted_Intersection_over_Union()MIOU:
def Mean_Intersection_over_Union(self):
MIoU = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
MIoU = np.nanmean(MIoU)
return MIoU



关于Miou,这篇博客:
https://blog.csdn.net/u012370185/article/details/94409933
语义分割代码阅读---评价指标mIoU的计算


def Mean_Intersection_over_Union(self):
MIoU = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
MIoU = np.nanmean(MIoU)
return MIoU
confusion_matrix=21*21
这里:
b = self.confusion_matrix.sum(axis=0)表示矩阵行求和
b = self.confusion_matrix.sum(axis=1)表示矩阵列求和

numpy.diag(v,k=0)
以一维数组的形式返回方阵的对角线(或非对角线)元素,或将一维数组转换成方阵(非对角线元素为0).两种功能角色转变取决于输入的v
np.nanmean
忽略nan 不计入分子,分母
返回数组元素的平均值。默认情况下,平均值取自展平的数组,否则取自指定的轴。
numpy.sum
执行求和的一个或多个轴。默认值axis = None将对输入数组的所有元素求和。如果轴为负,则从最后一个到第一个轴计数。
1.7.0版中的新功能。
如果axis是int的元组,则对元组中指定的所有轴进行求和,而不是像以前那样单个轴或所有轴。
关于混淆矩阵这里还有一点不清晰,用例子:我下载了训练好的
deeplab-resnet.pth.tar
测试了VOC2012的miou
Acc:0.9451761417058431, Acc_class:0.8713263988242872, mIoU:0.7843039392259025, fwIoU: 0.9007642125939461
这里我拿一个多类别效果比较好的



2007_000129
2007_000033
2007_000346






我们再看一下混淆矩阵的生成:
def _generate_matrix(self, gt_image, pre_image):
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix用例子来解释混淆矩阵的生成:
21*21=441
数组个数是mask的个数
confusion_matrix是【0-440】,
它的21的位置,表示gt为1,预测为0
它的22的位置,表示gt为1,预测也为1,
它的23的位置,表示gt为1,预测为2,
gt_image[mask].astype('int'),是GroundTruth中的真实值在[0-21)左闭右开
数组个数是mask的个数
我们假设XXX = self.num_class * gt_image[mask].astype('int')
将值[0-21)分别乘21,这样就是
0对应0, 1对应21 , 2对应42, 3对应63.。。。。。。。20对应420
如果gt_image[mask].astype('int')有个位置的值是20,那么self.num_class * gt_image[mask].astype('int') 为420,
pre_image[mask]是预测值,取值在[0-21)区间内,
如果pre_image[mask]也预测对,那么他的值是20,
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
那么label的值为420+20=440
如果pre_image[mask]预测的是0,那么该位置的值是0,
那么label的值为420+0=420
如果pre_image[mask]预测的是1,那么该位置的值是1,
那么label的值为420+1=421
如果pre_image[mask]预测的是2,那么该位置的值是2,
那么label的值为420+1=422
如果pre_image[mask]预测的是3,那么该位置的值是3,
那么label的值为420+1=423
如果其他位置也有很多原本是420的,通过加上pred,得到的值为 420,421,422。。。。440
那么对labe求值的直方图
对应confusion_matrix,reshape一下
就是最后一行:
因为混淆矩阵是0-440 ,最后一行正好是420,421,422,。。。。。。440
那么对应第二行,同样的,
原本是gt为1,对应self.num_class * gt_image[mask].astype('int')=21
如果pre_image[mask]也预测对,那么应该是22
XXX=1,pre_image[mask]=0,对应21
XXX=1,pre_image[mask]=1,对应22
XXX=1,pre_image[mask]=2,对应23
XXX=1,pre_image[mask]=3,对应24
XXX=1,pre_image[mask]=20,对应41
在mask数组中,有很多对应如上不同取值的位置,那么对labe求值的直方图:
对应confusion_matrix,reshape一下
就是第二行:
# Fast test during the training
Acc = self.evaluator.Pixel_Accuracy()
Acc_class = self.evaluator.Pixel_Accuracy_Class()
mIoU = self.evaluator.Mean_Intersection_over_Union()
FWIoU = self.evaluator.Frequency_Weighted_Intersection_over_Union()
print("Acc:{}, Acc_class:{}, mIoU:{}, fwIoU: {}".format(Acc, Acc_class, mIoU, FWIoU))其他指标:

def Frequency_Weighted_Intersection_over_Union(self):
freq = np.sum(self.confusion_matrix, axis=1) / np.sum(self.confusion_matrix)
iu = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
FWIoU = (freq[freq > 0] * iu[freq > 0]).sum()
return FWIoU 
def Pixel_Accuracy(self):
Acc = np.diag(self.confusion_matrix).sum() / self.confusion_matrix.sum()
return Acc

def Pixel_Accuracy_Class(self):
Acc = np.diag(self.confusion_matrix) / self.confusion_matrix.sum(axis=1)
Acc = np.nanmean(Acc)
return Acc

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)